Refine search
Actions for selected content:
53194 results in Statistics and Probability
A new measure of inaccuracy for record statistics based on extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 10 March 2023, pp. 207-225
-
- Article
-
- You have access
- HTML
- Export citation
Phase transitions in biased opinion dynamics with 2-choices rule
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 10 March 2023, pp. 227-244
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a model of binary opinion dynamics where one opinion is inherently “superior” than the other, and social agents exhibit a “bias” toward the superior alternative. Specifically, it is assumed that an agent updates its choice to the superior alternative with probability α > 0 irrespective of its current opinion and opinions of other agents. With probability
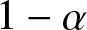 $1-\alpha$, it adopts majority opinion among two randomly sampled neighbors and itself. We are interested in the time it takes for the network to converge to a consensus on the superior alternative. In a complete graph of size n, we show that irrespective of the initial configuration of the network, the average time to reach consensus scales as
$1-\alpha$, it adopts majority opinion among two randomly sampled neighbors and itself. We are interested in the time it takes for the network to converge to a consensus on the superior alternative. In a complete graph of size n, we show that irrespective of the initial configuration of the network, the average time to reach consensus scales as 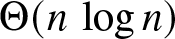 $\Theta(n\,\log n)$ when the bias parameter α is sufficiently high, that is,
$\Theta(n\,\log n)$ when the bias parameter α is sufficiently high, that is,  $\alpha \gt \alpha_c$ where αc is a threshold parameter that is uniquely characterized. When the bias is low, that is, when
$\alpha \gt \alpha_c$ where αc is a threshold parameter that is uniquely characterized. When the bias is low, that is, when 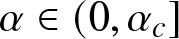 $\alpha \in (0,\alpha_c]$, we show that the same rate of convergence can only be achieved if the initial proportion of agents with the superior opinion is above certain threshold
$\alpha \in (0,\alpha_c]$, we show that the same rate of convergence can only be achieved if the initial proportion of agents with the superior opinion is above certain threshold 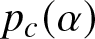 $p_c(\alpha)$. If this is not the case, then we show that the network takes
$p_c(\alpha)$. If this is not the case, then we show that the network takes 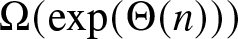 $\Omega(\exp(\Theta(n)))$ time on average to reach consensus.
$\Omega(\exp(\Theta(n)))$ time on average to reach consensus.
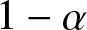
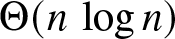

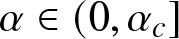
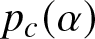
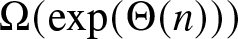
Thin-ended clusters in percolation in
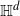 $\mathbb{H}^d$
$\mathbb{H}^d$
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 10 March 2023, pp. 581-610
- Print publication:
- June 2023
-
- Article
- Export citation
-
Consider Bernoulli bond percolation on a graph nicely embedded in hyperbolic space
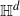 $\mathbb{H}^d$ in such a way that it admits a transitive action by isometries of
$\mathbb{H}^d$ in such a way that it admits a transitive action by isometries of 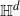 $\mathbb{H}^d$. Let
$\mathbb{H}^d$. Let 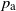 $p_{\text{a}}$ be the supremum of all percolation parameters such that no point at infinity of
$p_{\text{a}}$ be the supremum of all percolation parameters such that no point at infinity of 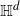 $\mathbb{H}^d$ lies in the boundary of the cluster of a fixed vertex with positive probability. Then for any parameter
$\mathbb{H}^d$ lies in the boundary of the cluster of a fixed vertex with positive probability. Then for any parameter 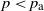 $p < p_{\text{a}}$, almost surely every percolation cluster is thin-ended, i.e. has only one-point boundaries of ends.
$p < p_{\text{a}}$, almost surely every percolation cluster is thin-ended, i.e. has only one-point boundaries of ends.
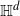
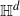
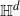
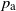
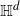
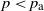
8 - Introduction to Relational Databases
- from Part III - Data in Databases
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 103-120
-
- Chapter
-
- You have access
- Open access
- Export citation
Appendix A - Description of HUD data and Analysis
- from 12 - Validation of Models Used by Banks to Estimate Their Allowance for Loan and Lease Losses
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 323-323
-
- Chapter
- Export citation
3 - Data = Content + Structure
- from Part I - Introduction
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 23-36
-
- Chapter
-
- You have access
- Open access
- Export citation
17 - Validation of Risk Management Models in Investment Management
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 439-444
-
- Chapter
- Export citation
14 - Best Practices in Data Management
- from Part V - Conclusion
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 209-218
-
- Chapter
-
- You have access
- Open access
- Export citation
Contributors
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp xiii-xiv
-
- Chapter
- Export citation
Part III - Data in Databases
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 101-102
-
- Chapter
-
- You have access
- Open access
- Export citation
8 - COM–Poisson Cure Rate Models
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 284-311
-
- Chapter
- Export citation
12 - Validation of Models Used by Banks to Estimate Their Allowance for Loan and Lease Losses
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 295-330
-
- Chapter
- Export citation
Part IV - Special Types of Data
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 145-146
-
- Chapter
-
- You have access
- Open access
- Export citation
6 - Evaluating Banks’ Value-at-Risk Models during the COVID-19 Crisis
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 104-123
-
- Chapter
- Export citation
10 - Database Fine-Tuning
- from Part III - Data in Databases
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 135-144
-
- Chapter
-
- You have access
- Open access
- Export citation
Foreword
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp xv-xvi
-
- Chapter
- Export citation
4 - Storing Data in Files
- from Part II - Data in Files
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 39-58
-
- Chapter
-
- You have access
- Open access
- Export citation
Dedication
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp v-vi
-
- Chapter
-
- You have access
- Open access
- Export citation
2 - The Conway–Maxwell–Poisson (COM–Poisson) Distribution
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 22-70
-
- Chapter
- Export citation
13 - Operational Risk
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 331-358
-
- Chapter
- Export citation
