Refine search
Actions for selected content:
53194 results in Statistics and Probability
Think about the stakeholders first! Toward an algorithmic transparency playbook for regulatory compliance
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 31 March 2023, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What do data portals do? Tracing the politics of online devices for making data public
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 30 March 2023, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The impact of simultaneous shocks to financial markets and mortality on pension buy-out prices
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 30 March 2023, pp. 392-417
- Print publication:
- May 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How do empirical estimators of popular risk measures impact pro-cyclicality?
- Part of
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 3 / November 2023
- Published online by Cambridge University Press:
- 29 March 2023, pp. 547-579
-
- Article
- Export citation
On Bayesian credibility mean for finite mixture distributions
- Part of
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 29 March 2023, pp. 5-29
-
- Article
- Export citation
-
Consider the problem of determining the Bayesian credibility mean
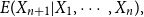 $E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims
$E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims 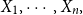 $X_1,\cdots, X_n,$ given parameter vector
$X_1,\cdots, X_n,$ given parameter vector 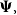 $\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information
$\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information 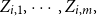 $Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim
$Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim 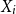 $X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about
$X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about 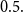 $0.5.$ Several examples have been given to illustrate the practical application of our findings.
$0.5.$ Several examples have been given to illustrate the practical application of our findings.
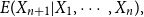
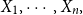
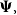
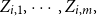
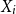
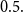
Asymptotic normality for
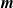 $\boldsymbol{m}$-dependent and constrained
$\boldsymbol{m}$-dependent and constrained 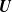 $\boldsymbol{U}$-statistics, with applications to pattern matching in random strings and permutations
$\boldsymbol{U}$-statistics, with applications to pattern matching in random strings and permutations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 28 March 2023, pp. 841-894
- Print publication:
- September 2023
-
- Article
- Export citation
-
We study (asymmetric)
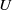 $U$-statistics based on a stationary sequence of
$U$-statistics based on a stationary sequence of 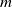 $m$-dependent variables; moreover, we consider constrained
$m$-dependent variables; moreover, we consider constrained 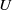 $U$-statistics, where the defining multiple sum only includes terms satisfying some restrictions on the gaps between indices. Results include a law of large numbers and a central limit theorem, together with results on rate of convergence, moment convergence, functional convergence, and a renewal theory version.
$U$-statistics, where the defining multiple sum only includes terms satisfying some restrictions on the gaps between indices. Results include a law of large numbers and a central limit theorem, together with results on rate of convergence, moment convergence, functional convergence, and a renewal theory version.Special attention is paid to degenerate cases where, after the standard normalization, the asymptotic variance vanishes; in these cases non-normal limits occur after a different normalization.
The results are motivated by applications to pattern matching in random strings and permutations. We obtain both new results and new proofs of old results.
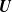
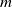
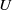
Responding to the coronavirus disease-2019 pandemic with innovative data use: The role of data challenges
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 27 March 2023, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Keng Seng Tan 1970–2023 In Memoriam
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 24 March 2023, pp. 1-6
-
- Article
-
- You have access
- HTML
- Export citation
The Berkelmans–Pries dependency function: A generic measure of dependence between random variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 23 March 2023, pp. 1115-1135
- Print publication:
- December 2023
-
- Article
- Export citation

Network Models for Data Science
- Theory, Algorithms, and Applications
-
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023
-
- Textbook
- Export citation
Author response to: Letter to Editor in response to assessment of early and post-COVID-19 vaccination antibody response in healthcare workers: A multicentre cross-sectional study on inactivated, mRNA and vector-based vaccines
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 22 March 2023, e73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An asymptotically optimal heuristic for general nonstationary finite-horizon restless multi-armed, multi-action bandits: Corrigendum
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 22 March 2023, pp. 1075-1083
- Print publication:
- September 2023
-
- Article
-
- You have access
- HTML
- Export citation
Catering of high-risk foods and potential of stored food menu data for timely outbreak investigations in healthcare facilities, Italy and Germany
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 22 March 2023, e61
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Raccoon rabies control and elimination in the northeastern USA and southern Québec, Canada
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 22 March 2023, e62
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Rabies virus (RABV) is a deadly zoonosis that circulates in wild carnivore populations in North America. Intensive management within the USA and Canada has been conducted to control the spread of the raccoon (Procyon lotor) variant of RABV and work towards elimination. We examined RABV occurrence across the northeastern USA and southeastern Québec, Canada during 2008–2018 using a multi-method, dynamic occupancy model. Using a 10 km × 10 km grid overlaid on the landscape, we examined the probability that a grid cell was occupied with RABV and relationships with management activities (oral rabies vaccination (ORV) and trap-vaccinate-release efforts), habitat, neighbour effects and temporal trends. We compared raccoon RABV detection probabilities between different surveillance samples (e.g. animals that are strange acting, road-kill, public health samples). The management of RABV through ORV was found to be the greatest driver in reducing the occurrence of rabies on the landscape. Additionally, RABV occupancy declined further with increasing duration of ORV baiting programmes. Grid cells north of ORV management were at or near elimination ($\hat{\psi }_{{\rm north}}$
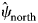 = 0.00, s.e. = 0.15), managed areas had low RABV occupancy ($\hat{\psi }_{{\rm managed}}$
= 0.00, s.e. = 0.15), managed areas had low RABV occupancy ($\hat{\psi }_{{\rm managed}}$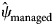 = 0.20, s.e. = 0.29) and enzootic areas had the highest level of RABV occupancy ($\hat{\psi }_{{\rm south}}$
= 0.20, s.e. = 0.29) and enzootic areas had the highest level of RABV occupancy ($\hat{\psi }_{{\rm south}}$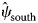 = 0.83, s.e. = 0.06). These results provide evidence that past management actions have been being successful at the goals of reducing and controlling the raccoon variant of RABV. At a finer scale we also found that vaccine bait type and bait density impacted RABV occupancy. Detection probabilities varied; samples from strange acting animals and public health had the highest detection rates. Our results support the movement of the ORV zone south within the USA due to high elimination probabilities along the US border with Québec. Additional enhanced rabies surveillance is still needed to ensure elimination is maintained.
= 0.83, s.e. = 0.06). These results provide evidence that past management actions have been being successful at the goals of reducing and controlling the raccoon variant of RABV. At a finer scale we also found that vaccine bait type and bait density impacted RABV occupancy. Detection probabilities varied; samples from strange acting animals and public health had the highest detection rates. Our results support the movement of the ORV zone south within the USA due to high elimination probabilities along the US border with Québec. Additional enhanced rabies surveillance is still needed to ensure elimination is maintained.
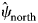
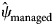
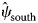
The size of a Markovian SIR epidemic given only removal data
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 21 March 2023, pp. 895-926
- Print publication:
- September 2023
-
- Article
- Export citation
-
During an epidemic outbreak, typically only partial information about the outbreak is known. A common scenario is that the infection times of individuals are unknown, but individuals, on displaying symptoms, are identified as infectious and removed from the population. We study the distribution of the number of infectives given only the times of removals in a Markovian susceptible–infectious–removed (SIR) epidemic. Primary interest is in the initial stages of the epidemic process, where a branching (birth–death) process approximation is applicable. We show that the number of individuals alive in a time-inhomogeneous birth–death process at time
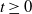 $t \geq 0$, given only death times up to and including time t, is a mixture of negative binomial distributions, with the number of mixing components depending on the total number of deaths, and the mixing weights depending upon the inter-arrival times of the deaths. We further consider the extension to the case where some deaths are unobserved. We also discuss the application of the results to control measures and statistical inference.
$t \geq 0$, given only death times up to and including time t, is a mixture of negative binomial distributions, with the number of mixing components depending on the total number of deaths, and the mixing weights depending upon the inter-arrival times of the deaths. We further consider the extension to the case where some deaths are unobserved. We also discuss the application of the results to control measures and statistical inference.
Impact of airline network on the global importation risk of mpox, 2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 21 March 2023, e60
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotic persistence time formulae for multitype birth–death processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 21 March 2023, pp. 895-920
- Print publication:
- September 2023
-
- Article
- Export citation
-
We consider a class of processes describing a population consisting of k types of individuals. The process is almost surely absorbed at the origin within finite time, and we study the expected time taken for such extinction to occur. We derive simple and precise asymptotic estimates for this expected persistence time, starting either from a single individual or from a quasi-equilibrium state, in the limit as a system size parameter N tends to infinity. Our process need not be a Markov process on
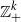 $ {\mathbb Z}_+^k$; we allow the possibility that individuals’ lifetimes may follow more general distributions than the exponential distribution.
$ {\mathbb Z}_+^k$; we allow the possibility that individuals’ lifetimes may follow more general distributions than the exponential distribution.
Comparative transmission of SARS-CoV-2 Omicron (B.1.1.529) and Delta (B.1.617.2) variants and the impact of vaccination: national cohort study, England
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 20 March 2023, e58
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Benchmarks for the benchmark approach to valuing long-term insurance liabilities: comment on Fergusson & Platen (2023)
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 20 March 2023, pp. 208-211
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessment of early and post COVID-19 vaccination antibody response in healthcare workers: a critical review
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 20 March 2023, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
