Refine search
Actions for selected content:
53194 results in Statistics and Probability
Approaching the coupon collector’s problem with group drawings via Stein’s method
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 25 April 2023, pp. 1352-1366
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
-
We study the coupon collector’s problem with group drawings. Assume there are n different coupons. At each time precisely s of the n coupons are drawn, where all choices are supposed to have equal probability. The focus lies on the fluctuations, as
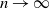 $n\to\infty$, of the number
$n\to\infty$, of the number 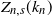 $Z_{n,s}(k_n)$ of coupons that have not been drawn in the first
$Z_{n,s}(k_n)$ of coupons that have not been drawn in the first 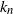 $k_n$ drawings. Using a size-biased coupling construction together with Stein’s method for normal approximation, a quantitative central limit theorem for
$k_n$ drawings. Using a size-biased coupling construction together with Stein’s method for normal approximation, a quantitative central limit theorem for 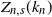 $Z_{n,s}(k_n)$ is shown for the case that
$Z_{n,s}(k_n)$ is shown for the case that 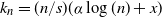 $k_n=({n/s})(\alpha\log(n)+x)$, where
$k_n=({n/s})(\alpha\log(n)+x)$, where 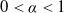 $0<\alpha<1$ and
$0<\alpha<1$ and 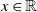 $x\in\mathbb{R}$. The same coupling construction is used to retrieve a quantitative Poisson limit theorem in the boundary case
$x\in\mathbb{R}$. The same coupling construction is used to retrieve a quantitative Poisson limit theorem in the boundary case 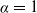 $\alpha=1$, again using Stein’s method.
$\alpha=1$, again using Stein’s method.
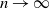
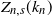
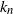
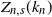
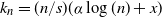
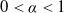
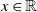
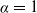
Ramsey upper density of infinite graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 25 April 2023, pp. 703-723
-
- Article
- Export citation
-
For a fixed infinite graph
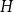 $H$, we study the largest density of a monochromatic subgraph isomorphic to
$H$, we study the largest density of a monochromatic subgraph isomorphic to 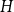 $H$ that can be found in every two-colouring of the edges of
$H$ that can be found in every two-colouring of the edges of 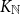 $K_{\mathbb{N}}$. This is called the Ramsey upper density of
$K_{\mathbb{N}}$. This is called the Ramsey upper density of 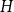 $H$ and was introduced by Erdős and Galvin in a restricted setting, and by DeBiasio and McKenney in general. Recently [4], the Ramsey upper density of the infinite path was determined. Here, we find the value of this density for all locally finite graphs
$H$ and was introduced by Erdős and Galvin in a restricted setting, and by DeBiasio and McKenney in general. Recently [4], the Ramsey upper density of the infinite path was determined. Here, we find the value of this density for all locally finite graphs 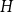 $H$ up to a factor of 2, answering a question of DeBiasio and McKenney. We also find the exact density for a wide class of bipartite graphs, including all locally finite forests. Our approach relates this problem to the solution of an optimisation problem for continuous functions. We show that, under certain conditions, the density depends only on the chromatic number of
$H$ up to a factor of 2, answering a question of DeBiasio and McKenney. We also find the exact density for a wide class of bipartite graphs, including all locally finite forests. Our approach relates this problem to the solution of an optimisation problem for continuous functions. We show that, under certain conditions, the density depends only on the chromatic number of 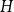 $H$, the number of components of
$H$, the number of components of 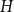 $H$ and the expansion ratio
$H$ and the expansion ratio 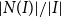 $|N(I)|/|I|$ of the independent sets of
$|N(I)|/|I|$ of the independent sets of 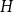 $H$.
$H$.
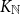
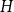
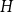
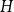
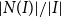
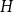
Prevalence of Trypanosoma cruzi infection in a cohort of people living with HIV/AIDS from an urban area
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 25 April 2023, e72
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
INTERCEPT ESTIMATION IN NONLINEAR SELECTION MODELS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 6 / December 2024
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1311-1363
-
- Article
-
- You have access
- Open access
- Export citation
Problems and results on 1-cross-intersecting set pair systems
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 691-702
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The notion of cross-intersecting set pair system of size
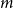 $m$,
$m$, 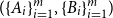 $ (\{A_i\}_{i=1}^m, \{B_i\}_{i=1}^m )$ with
$ (\{A_i\}_{i=1}^m, \{B_i\}_{i=1}^m )$ with 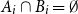 $A_i\cap B_i=\emptyset$ and
$A_i\cap B_i=\emptyset$ and 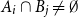 $A_i\cap B_j\ne \emptyset$, was introduced by Bollobás and it became an important tool of extremal combinatorics. His classical result states that
$A_i\cap B_j\ne \emptyset$, was introduced by Bollobás and it became an important tool of extremal combinatorics. His classical result states that 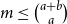 $m\le\binom{a+b}{a}$ if
$m\le\binom{a+b}{a}$ if 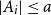 $|A_i|\le a$ and
$|A_i|\le a$ and 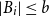 $|B_i|\le b$ for each
$|B_i|\le b$ for each 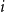 $i$. Our central problem is to see how this bound changes with the additional condition
$i$. Our central problem is to see how this bound changes with the additional condition 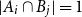 $|A_i\cap B_j|=1$ for
$|A_i\cap B_j|=1$ for 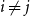 $i\ne j$. Such a system is called
$i\ne j$. Such a system is called 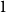 $1$-cross-intersecting. We show that these systems are related to perfect graphs, clique partitions of graphs, and finite geometries. We prove that their maximum size is
$1$-cross-intersecting. We show that these systems are related to perfect graphs, clique partitions of graphs, and finite geometries. We prove that their maximum size isat least
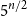 $5^{n/2}$ for
$5^{n/2}$ for  $n$ even,
$n$ even, 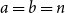 $a=b=n$,
$a=b=n$,equal to
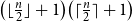 $\bigl (\lfloor \frac{n}{2}\rfloor +1\bigr )\bigl (\lceil \frac{n}{2}\rceil +1\bigr )$ if
$\bigl (\lfloor \frac{n}{2}\rfloor +1\bigr )\bigl (\lceil \frac{n}{2}\rceil +1\bigr )$ if 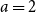 $a=2$ and
$a=2$ and 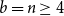 $b=n\ge 4$,
$b=n\ge 4$,at most
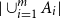 $|\cup _{i=1}^m A_i|$,
$|\cup _{i=1}^m A_i|$,asymptotically
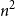 $n^2$ if
$n^2$ if 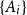 $\{A_i\}$ is a linear hypergraph (
$\{A_i\}$ is a linear hypergraph (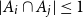 $|A_i\cap A_j|\le 1$ for
$|A_i\cap A_j|\le 1$ for 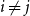 $i\ne j$),
$i\ne j$),asymptotically
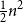 ${1\over 2}n^2$ if
${1\over 2}n^2$ if 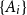 $\{A_i\}$ and
$\{A_i\}$ and 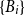 $\{B_i\}$ are both linear hypergraphs.
$\{B_i\}$ are both linear hypergraphs.
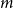
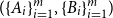
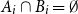
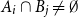
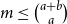
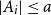
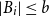
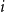
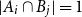
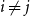
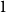
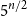

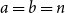
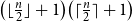
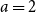
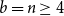
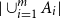
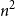
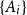
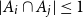
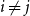
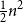
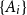
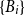
Lower bound for the expected supremum of fractional brownian motion using coupling
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1232-1248
- Print publication:
- December 2023
-
- Article
- Export citation
-
We derive a new theoretical lower bound for the expected supremum of drifted fractional Brownian motion with Hurst index
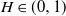 $H\in(0,1)$ over a (in)finite time horizon. Extensive simulation experiments indicate that our lower bound outperforms the Monte Carlo estimates based on very dense grids for
$H\in(0,1)$ over a (in)finite time horizon. Extensive simulation experiments indicate that our lower bound outperforms the Monte Carlo estimates based on very dense grids for 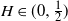 $H\in(0,\tfrac{1}{2})$. Additionally, we derive the Paley–Wiener–Zygmund representation of a linear fractional Brownian motion in the general case and give an explicit expression for the derivative of the expected supremum at
$H\in(0,\tfrac{1}{2})$. Additionally, we derive the Paley–Wiener–Zygmund representation of a linear fractional Brownian motion in the general case and give an explicit expression for the derivative of the expected supremum at 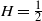 $H=\tfrac{1}{2}$ in the sense of Bisewski, Dȩbicki and Rolski (2021).
$H=\tfrac{1}{2}$ in the sense of Bisewski, Dȩbicki and Rolski (2021).
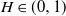
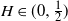
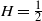
A physics-based domain adaptation framework for modeling and forecasting building energy systems
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Operationalizing digital self-determination
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NUCLEAR NORM REGULARIZED QUANTILE REGRESSION WITH INTERACTIVE FIXED EFFECTS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 6 / December 2024
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1391-1421
-
- Article
- Export citation
Characterization theorems for pseudo cross-variograms
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1219-1231
- Print publication:
- December 2023
-
- Article
- Export citation
Shortcuts for the construction of sub-annual life tables
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 332-350
- Print publication:
- May 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
“Insurers” hidden risk from reinsurance recaptures – the perspective of UK annuity writers’
-
- Journal:
- British Actuarial Journal / Volume 28 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Clique-factors in graphs with sublinear
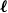 $\boldsymbol\ell$-independence number
$\boldsymbol\ell$-independence number
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 665-681
-
- Article
- Export citation
-
Given a graph
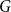 $G$ and an integer
$G$ and an integer 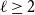 $\ell \ge 2$, we denote by
$\ell \ge 2$, we denote by 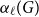 $\alpha _{\ell }(G)$ the maximum size of a
$\alpha _{\ell }(G)$ the maximum size of a 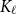 $K_{\ell }$-free subset of vertices in
$K_{\ell }$-free subset of vertices in 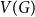 $V(G)$. A recent question of Nenadov and Pehova asks for determining the best possible minimum degree conditions forcing clique-factors in
$V(G)$. A recent question of Nenadov and Pehova asks for determining the best possible minimum degree conditions forcing clique-factors in  $n$-vertex graphs
$n$-vertex graphs 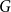 $G$ with
$G$ with 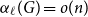 $\alpha _{\ell }(G) = o(n)$, which can be seen as a Ramsey–Turán variant of the celebrated Hajnal–Szemerédi theorem. In this paper we find the asymptotical sharp minimum degree threshold for
$\alpha _{\ell }(G) = o(n)$, which can be seen as a Ramsey–Turán variant of the celebrated Hajnal–Szemerédi theorem. In this paper we find the asymptotical sharp minimum degree threshold for 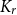 $K_r$-factors in
$K_r$-factors in  $n$-vertex graphs
$n$-vertex graphs 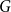 $G$ with
$G$ with 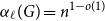 $\alpha _\ell (G)=n^{1-o(1)}$ for all
$\alpha _\ell (G)=n^{1-o(1)}$ for all 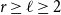 $r\ge \ell \ge 2$.
$r\ge \ell \ge 2$.
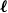
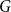
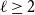
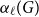
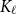
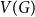

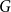
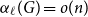
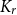

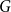
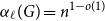
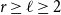
Expected number of faces in a random embedding of any graph is at most linear
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 682-690
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A random two-cell embedding of a given graph
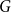 $G$ is obtained by choosing a random local rotation around every vertex. We analyse the expected number of faces of such an embedding, which is equivalent to studying its average genus. In 1991, Stahl [5] proved that the expected number of faces in a random embedding of an arbitrary graph of order
$G$ is obtained by choosing a random local rotation around every vertex. We analyse the expected number of faces of such an embedding, which is equivalent to studying its average genus. In 1991, Stahl [5] proved that the expected number of faces in a random embedding of an arbitrary graph of order  $n$ is at most
$n$ is at most 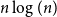 $n\log (n)$. While there are many families of graphs whose expected number of faces is
$n\log (n)$. While there are many families of graphs whose expected number of faces is 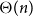 $\Theta (n)$, none are known where the expected number would be super-linear. This led the authors of [1] to conjecture that there is a linear upper bound. In this note we confirm their conjecture by proving that for any
$\Theta (n)$, none are known where the expected number would be super-linear. This led the authors of [1] to conjecture that there is a linear upper bound. In this note we confirm their conjecture by proving that for any  $n$-vertex multigraph, the expected number of faces in a random two-cell embedding is at most
$n$-vertex multigraph, the expected number of faces in a random two-cell embedding is at most 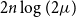 $2n\log (2\mu )$, where
$2n\log (2\mu )$, where 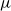 $\mu$ is the maximum edge-multiplicity. This bound is best possible up to a constant factor.
$\mu$ is the maximum edge-multiplicity. This bound is best possible up to a constant factor.

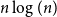
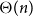

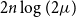
Open data as an anticorruption tool? Using distributed cognition to understand breakdowns in the creation of transparency data
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SARS-CoV-2 seroprevalence and determinants for salivary seropositivity among pupils and school staff: a prospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e75
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Large deviations of extremal eigenvalues of sample covariance matrices
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1275-1280
- Print publication:
- December 2023
-
- Article
- Export citation
-
Large deviations of the largest and smallest eigenvalues of
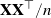 $\mathbf{X}\mathbf{X}^\top/n$ are studied in this note, where
$\mathbf{X}\mathbf{X}^\top/n$ are studied in this note, where 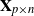 $\mathbf{X}_{p\times n}$ is a
$\mathbf{X}_{p\times n}$ is a 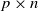 $p\times n$ random matrix with independent and identically distributed (i.i.d.) sub-Gaussian entries. The assumption imposed on the dimension size p and the sample size n is
$p\times n$ random matrix with independent and identically distributed (i.i.d.) sub-Gaussian entries. The assumption imposed on the dimension size p and the sample size n is 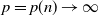 $p=p(n)\rightarrow\infty$ with
$p=p(n)\rightarrow\infty$ with 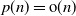 $p(n)={\mathrm{o}}(n)$. This study generalizes one result obtained in [3].
$p(n)={\mathrm{o}}(n)$. This study generalizes one result obtained in [3].
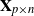
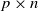
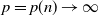
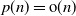
Impact of combination methods on extreme precipitation projections
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 3 / November 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 459-478
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Limiting shape for first-passage percolation models on random geometric graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1367-1385
- Print publication:
- December 2023
-
- Article
- Export citation
The use of autoencoders for training neural networks with mixed categorical and numerical features
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 213-232
- Print publication:
- May 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
