Refine search
Actions for selected content:
53194 results in Statistics and Probability
A NOVEL APPROACH TO PREDICTIVE ACCURACY TESTING IN NESTED ENVIRONMENTS
-
- Journal:
- Econometric Theory / Volume 41 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 17 May 2023, pp. 35-78
-
- Article
-
- You have access
- Open access
- Export citation
Universal geometric graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 15 May 2023, pp. 742-761
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We extend the notion of universal graphs to a geometric setting. A geometric graph is universal for a class
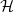 $\mathcal H$ of planar graphs if it contains an embedding, that is, a crossing-free drawing, of every graph in
$\mathcal H$ of planar graphs if it contains an embedding, that is, a crossing-free drawing, of every graph in 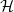 $\mathcal H$. Our main result is that there exists a geometric graph with
$\mathcal H$. Our main result is that there exists a geometric graph with  $n$ vertices and
$n$ vertices and 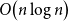 $O\!\left(n \log n\right)$ edges that is universal for
$O\!\left(n \log n\right)$ edges that is universal for  $n$-vertex forests; this generalises a well-known result by Chung and Graham, which states that there exists an (abstract) graph with
$n$-vertex forests; this generalises a well-known result by Chung and Graham, which states that there exists an (abstract) graph with  $n$ vertices and
$n$ vertices and 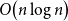 $O\!\left(n \log n\right)$ edges that contains every
$O\!\left(n \log n\right)$ edges that contains every  $n$-vertex forest as a subgraph. The upper bound of
$n$-vertex forest as a subgraph. The upper bound of 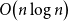 $O\!\left(n \log n\right)$ edges cannot be improved, even if more than
$O\!\left(n \log n\right)$ edges cannot be improved, even if more than  $n$ vertices are allowed. We also prove that every
$n$ vertices are allowed. We also prove that every  $n$-vertex convex geometric graph that is universal for
$n$-vertex convex geometric graph that is universal for  $n$-vertex outerplanar graphs has a near-quadratic number of edges, namely
$n$-vertex outerplanar graphs has a near-quadratic number of edges, namely 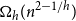 $\Omega _h(n^{2-1/h})$, for every positive integer
$\Omega _h(n^{2-1/h})$, for every positive integer 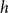 $h$; this almost matches the trivial
$h$; this almost matches the trivial 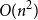 $O(n^2)$ upper bound given by the
$O(n^2)$ upper bound given by the  $n$-vertex complete convex geometric graph. Finally, we prove that there exists an
$n$-vertex complete convex geometric graph. Finally, we prove that there exists an  $n$-vertex convex geometric graph with
$n$-vertex convex geometric graph with  $n$ vertices and
$n$ vertices and 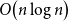 $O\!\left(n \log n\right)$ edges that is universal for
$O\!\left(n \log n\right)$ edges that is universal for  $n$-vertex caterpillars.
$n$-vertex caterpillars.



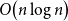

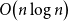



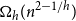
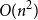



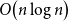

An investigation of the seasonal relationships between meteorological factors, water quality, and sporadic cases of Legionnaires’ disease in Washington, DC
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 15 May 2023, e88
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exponential control of the trajectories of iterated function systems with application to semi-strong GARCH
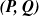 $\boldsymbol{{(P, Q)}}$ models
$\boldsymbol{{(P, Q)}}$ models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 15 May 2023, pp. 1501-1515
- Print publication:
- December 2023
-
- Article
- Export citation
Adverse childhood experiences and craving: Results from an Italian population in outpatient addiction treatment
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 12 May 2023, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
INFERENCE ON GARCH-MIDAS MODELS WITHOUT ANY SMALL-ORDER MOMENT
-
- Journal:
- Econometric Theory / Volume 40 / Issue 6 / December 2024
- Published online by Cambridge University Press:
- 12 May 2023, pp. 1422-1455
-
- Article
- Export citation
Index
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 458-464
-
- Chapter
- Export citation
6 - ARIMA(p, d, q)(P, D, Q)F Modeling and Forecasting
- from Part II - Univariate Models of Temporal Dependence
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 245-312
-
- Chapter
- Export citation
Preface
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp xi-xii
-
- Chapter
- Export citation
5 - Stationary Stochastic Processes
- from Part II - Univariate Models of Temporal Dependence
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 189-244
-
- Chapter
- Export citation
References
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 448-457
-
- Chapter
- Export citation
Pyrroloquinoline quinone influences intracellular alpha-synuclein aggregates
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 11 May 2023, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - Introduction to Time Series Data
- from Part I - Descriptive Features of Time Series Data
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 4-57
-
- Chapter
-
- You have access
- Export citation
Part I - Descriptive Features of Time Series Data
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 1-3
-
- Chapter
- Export citation
9 - Classical Regression with ARMA Residuals
- from Part III - Multivariate Modeling and Forecasting
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 390-430
-
- Chapter
- Export citation
Part II - Univariate Models of Temporal Dependence
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 159-161
-
- Chapter
- Export citation
7 - Latent Process Models for Time Series
- from Part III - Multivariate Modeling and Forecasting
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 316-340
-
- Chapter
- Export citation
3 - Summary Statistics of Stationary Time Series
- from Part I - Descriptive Features of Time Series Data
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp 114-158
-
- Chapter
- Export citation
Dedication
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp v-vi
-
- Chapter
- Export citation
Contents
-
- Book:
- Time Series for Data Scientists
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023, pp vii-x
-
- Chapter
- Export citation
