Refine search
Actions for selected content:
53194 results in Statistics and Probability
A branching random walk in the presence of a hard wall
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 22 May 2023, pp. 1-17
- Print publication:
- March 2024
-
- Article
- Export citation
-
We consider a branching random walk on a d-ary tree of height n (
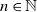 $n \in \mathbb{N}$), in the presence of a hard wall which restricts each value to be positive, where d is a natural number satisfying
$n \in \mathbb{N}$), in the presence of a hard wall which restricts each value to be positive, where d is a natural number satisfying 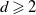 $d\geqslant2$. We consider the behaviour of Gaussian processes with long-range interactions, for example the discrete Gaussian free field, under the condition that it is positive on a large subset of vertices. We observe a relation with the expected maximum of the processes. We find the probability of the event that the branching random walk is positive at every vertex in the nth generation, and show that the conditional expectation of the Gaussian variable at a typical vertex, under positivity, is less than the expected maximum by order of
$d\geqslant2$. We consider the behaviour of Gaussian processes with long-range interactions, for example the discrete Gaussian free field, under the condition that it is positive on a large subset of vertices. We observe a relation with the expected maximum of the processes. We find the probability of the event that the branching random walk is positive at every vertex in the nth generation, and show that the conditional expectation of the Gaussian variable at a typical vertex, under positivity, is less than the expected maximum by order of 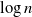 $\log n$.
$\log n$.
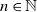
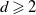
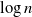
Genomic analysis of an outbreak of toxin gene bearing Corynebacterium diphtheriae in Northern Queensland, Australia reveals high level of genetic similarity
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 22 May 2023, e92
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A first-passage-place problem for integrated diffusion processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 22 May 2023, pp. 55-67
- Print publication:
- March 2024
-
- Article
- Export citation
-
Let
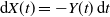 ${\mathrm{d}} X(t) = -Y(t) \, {\mathrm{d}} t$, where Y(t) is a one-dimensional diffusion process, and let
${\mathrm{d}} X(t) = -Y(t) \, {\mathrm{d}} t$, where Y(t) is a one-dimensional diffusion process, and let 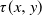 $\tau(x,y)$ be the first time the process (X(t), Y(t)), starting from (x, y), leaves a subset of the first quadrant. The problem of computing the probability
$\tau(x,y)$ be the first time the process (X(t), Y(t)), starting from (x, y), leaves a subset of the first quadrant. The problem of computing the probability 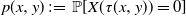 $p(x,y)\,:\!=\, \mathbb{P}[X(\tau(x,y))=0]$ is considered. The Laplace transform of the function p(x, y) is obtained in important particular cases, and it is shown that the transform can at least be inverted numerically. Explicit expressions for the Laplace transform of
$p(x,y)\,:\!=\, \mathbb{P}[X(\tau(x,y))=0]$ is considered. The Laplace transform of the function p(x, y) is obtained in important particular cases, and it is shown that the transform can at least be inverted numerically. Explicit expressions for the Laplace transform of 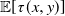 $\mathbb{E}[\tau(x,y)]$ and of the moment-generating function of
$\mathbb{E}[\tau(x,y)]$ and of the moment-generating function of 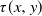 $\tau(x,y)$ can also be derived.
$\tau(x,y)$ can also be derived.
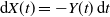
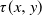
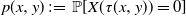
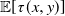
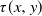
City data ecosystems between theory and practice: A qualitative exploratory study in seven European cities
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 22 May 2023, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Machine learning approaches for the prediction of serious fluid leakage from hydrocarbon wells
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 19 May 2023, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Averaging for slow–fast piecewise deterministic Markov processes with an attractive boundary
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 19 May 2023, pp. 1439-1468
- Print publication:
- December 2023
-
- Article
- Export citation
Raw driving data of passenger cars considering traffic conditions in Semnan city
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 19 May 2023, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prediction of the COVID-19 transmission: a case study of Pakistan
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 19 May 2023, e89
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Development and external validation of a prognostic tool for nonsevere COVID-19 inpatients
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 19 May 2023, e128
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Kalikow decomposition for counting processes with stochastic intensity and application to simulation algorithms
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 19 May 2023, pp. 1469-1500
- Print publication:
- December 2023
-
- Article
- Export citation
Use of portable air purifiers to reduce aerosols in hospital settings and cut down the clinical backlog: a critical analysis
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 19 May 2023, e86
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Distributions of random variables involved in discrete censored δ-shock models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 19 May 2023, pp. 1144-1170
- Print publication:
- December 2023
-
- Article
- Export citation
-
Suppose that a system is affected by a sequence of random shocks that occur over certain time periods. In this paper we study the discrete censored
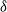 $\delta$-shock model,
$\delta$-shock model, 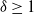 $\delta \ge 1$, for which the system fails whenever no shock occurs within a
$\delta \ge 1$, for which the system fails whenever no shock occurs within a 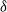 $\delta$-length time period from the last shock, by supposing that the interarrival times between consecutive shocks are described by a first-order Markov chain (as well as under the binomial shock process, i.e., when the interarrival times between successive shocks have a geometric distribution). Using the Markov chain embedding technique introduced by Chadjiconstantinidis et al. (Adv. Appl. Prob. 32, 2000), we study the joint and marginal distributions of the system’s lifetime, the number of shocks, and the number of periods in which no shocks occur, up to the failure of the system. The joint and marginal probability generating functions of these random variables are obtained, and several recursions and exact formulae are given for the evaluation of their probability mass functions and moments. It is shown that the system’s lifetime follows a Markov geometric distribution of order
$\delta$-length time period from the last shock, by supposing that the interarrival times between consecutive shocks are described by a first-order Markov chain (as well as under the binomial shock process, i.e., when the interarrival times between successive shocks have a geometric distribution). Using the Markov chain embedding technique introduced by Chadjiconstantinidis et al. (Adv. Appl. Prob. 32, 2000), we study the joint and marginal distributions of the system’s lifetime, the number of shocks, and the number of periods in which no shocks occur, up to the failure of the system. The joint and marginal probability generating functions of these random variables are obtained, and several recursions and exact formulae are given for the evaluation of their probability mass functions and moments. It is shown that the system’s lifetime follows a Markov geometric distribution of order 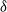 $\delta$ (a geometric distribution of order
$\delta$ (a geometric distribution of order 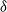 $\delta$ under the binomial setup) and also that it follows a matrix-geometric distribution. Some reliability properties are also given under the binomial shock process, by showing that a shift of the system’s lifetime random variable follows a compound geometric distribution. Finally, we introduce a new mixed discrete censored
$\delta$ under the binomial setup) and also that it follows a matrix-geometric distribution. Some reliability properties are also given under the binomial shock process, by showing that a shift of the system’s lifetime random variable follows a compound geometric distribution. Finally, we introduce a new mixed discrete censored 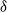 $\delta$-shock model, for which the system fails when no shock occurs within a
$\delta$-shock model, for which the system fails when no shock occurs within a 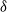 $\delta$-length time period from the last shock, or the magnitude of the shock is larger than a given critical threshold
$\delta$-length time period from the last shock, or the magnitude of the shock is larger than a given critical threshold 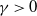 $\gamma >0$. Similarly, for this mixed model, we study the joint and marginal distributions of the system’s lifetime, the number of shocks, and the number of periods in which no shocks occur, up to the failure of the system, under the binomial shock process.
$\gamma >0$. Similarly, for this mixed model, we study the joint and marginal distributions of the system’s lifetime, the number of shocks, and the number of periods in which no shocks occur, up to the failure of the system, under the binomial shock process.
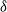
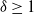
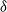
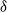
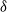
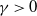
TESTING FOR ANTICIPATED CHANGES IN SPOT VOLATILITY AT EVENT TIMES
-
- Journal:
- Econometric Theory / Volume 41 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 19 May 2023, pp. 1-34
-
- Article
- Export citation
Association of current hepatitis B virus infection with mortality in adults with sepsis
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 19 May 2023, e94
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Joint models for cause-of-death mortality in multiple populations
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 18 May 2023, pp. 51-77
-
- Article
- Export citation
Subspace coverings with multiplicities
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 18 May 2023, pp. 782-795
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the problem of determining the minimum number
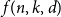 $f(n,k,d)$ of affine subspaces of codimension
$f(n,k,d)$ of affine subspaces of codimension 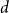 $d$ that are required to cover all points of
$d$ that are required to cover all points of 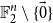 $\mathbb{F}_2^n\setminus \{\vec{0}\}$ at least
$\mathbb{F}_2^n\setminus \{\vec{0}\}$ at least 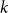 $k$ times while covering the origin at most
$k$ times while covering the origin at most 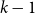 $k - 1$ times. The case
$k - 1$ times. The case 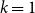 $k=1$ is a classic result of Jamison, which was independently obtained by Brouwer and Schrijver for
$k=1$ is a classic result of Jamison, which was independently obtained by Brouwer and Schrijver for 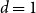 $d = 1$. The value of
$d = 1$. The value of 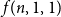 $f(n,1,1)$ also follows from a well-known theorem of Alon and Füredi about coverings of finite grids in affine spaces over arbitrary fields. Here we determine the value of this function exactly in various ranges of the parameters. In particular, we prove that for
$f(n,1,1)$ also follows from a well-known theorem of Alon and Füredi about coverings of finite grids in affine spaces over arbitrary fields. Here we determine the value of this function exactly in various ranges of the parameters. In particular, we prove that for 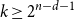 $k\geq 2^{n-d-1}$ we have
$k\geq 2^{n-d-1}$ we have 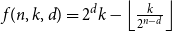 $f(n,k,d)=2^d k-\left\lfloor{\frac{k}{2^{n-d}}}\right\rfloor$, while for
$f(n,k,d)=2^d k-\left\lfloor{\frac{k}{2^{n-d}}}\right\rfloor$, while for 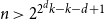 $n \gt 2^{2^d k-k-d+1}$ we have
$n \gt 2^{2^d k-k-d+1}$ we have 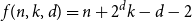 $f(n,k,d)=n + 2^d k -d-2$, and obtain asymptotic results between these two ranges. While previous work in this direction has primarily employed the polynomial method, we prove our results through more direct combinatorial and probabilistic arguments, and also exploit a connection to coding theory.
$f(n,k,d)=n + 2^d k -d-2$, and obtain asymptotic results between these two ranges. While previous work in this direction has primarily employed the polynomial method, we prove our results through more direct combinatorial and probabilistic arguments, and also exploit a connection to coding theory.
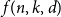
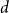
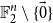
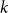
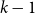
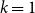
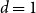
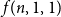
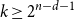
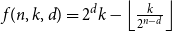
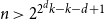
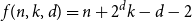
Genetic and epidemiological analyses of infection load and its relationship with psychiatric disorders
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 18 May 2023, e93
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A pair degree condition for Hamiltonian cycles in 3-uniform hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 17 May 2023, pp. 762-781
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove a new sufficient pair degree condition for tight Hamiltonian cycles in
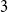 $3$-uniform hypergraphs that (asymptotically) improves the best known pair degree condition due to Rödl, Ruciński, and Szemerédi. For graphs, Chvátal characterised all those sequences of integers for which every pointwise larger (or equal) degree sequence guarantees the existence of a Hamiltonian cycle. A step towards Chvátal’s theorem was taken by Pósa, who improved on Dirac’s tight minimum degree condition for Hamiltonian cycles by showing that a certain weaker condition on the degree sequence of a graph already yields a Hamiltonian cycle.
$3$-uniform hypergraphs that (asymptotically) improves the best known pair degree condition due to Rödl, Ruciński, and Szemerédi. For graphs, Chvátal characterised all those sequences of integers for which every pointwise larger (or equal) degree sequence guarantees the existence of a Hamiltonian cycle. A step towards Chvátal’s theorem was taken by Pósa, who improved on Dirac’s tight minimum degree condition for Hamiltonian cycles by showing that a certain weaker condition on the degree sequence of a graph already yields a Hamiltonian cycle.In this work, we take a similar step towards a full characterisation of all pair degree matrices that ensure the existence of tight Hamiltonian cycles in
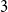 $3$-uniform hypergraphs by proving a
$3$-uniform hypergraphs by proving a 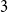 $3$-uniform analogue of Pósa’s result. In particular, our result strengthens the asymptotic version of the result by Rödl, Ruciński, and Szemerédi.
$3$-uniform analogue of Pósa’s result. In particular, our result strengthens the asymptotic version of the result by Rödl, Ruciński, and Szemerédi.
Intergenerational risk sharing in a defined contribution pension system: analysis with Bayesian optimization
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 17 May 2023, pp. 515-544
- Print publication:
- September 2023
-
- Article
- Export citation
Neural networks for quantile claim amount estimation: a quantile regression approach
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 17 May 2023, pp. 30-50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
