Refine search
Actions for selected content:
53194 results in Statistics and Probability
Direct and indirect vaccination effects on SARS-CoV-2 infection in day-care centres: Evaluating the policy for early vaccination of day-care staff in Germany, 2021
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 04 May 2023, e80
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
APR volume 55 issue 2 Cover and Back matter
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 04 May 2023, pp. b1-b2
- Print publication:
- June 2023
-
- Article
-
- You have access
- Export citation
JPR volume 60 issue 2 Cover and Front matter
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 04 May 2023, pp. f1-f2
- Print publication:
- June 2023
-
- Article
-
- You have access
- Export citation
JPR volume 60 issue 2 Cover and Back matter
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 04 May 2023, pp. b1-b2
- Print publication:
- June 2023
-
- Article
-
- You have access
- Export citation
NEW ROBUST INFERENCE FOR PREDICTIVE REGRESSIONS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 6 / December 2024
- Published online by Cambridge University Press:
- 03 May 2023, pp. 1364-1390
-
- Article
- Export citation
SIR epidemics driven by Feller processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 02 May 2023, pp. 1293-1316
- Print publication:
- December 2023
-
- Article
- Export citation
-
We consider a stochastic SIR (susceptible
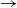 $\rightarrow$ infective
$\rightarrow$ infective 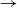 $\rightarrow$ removed) model in which the infectious periods are modulated by a collection of independent and identically distributed Feller processes. Each infected individual is associated with one of these processes, the trajectories of which determine the duration of his infectious period, his contamination rate, and his type of removal (e.g. death or immunization). We use a martingale approach to derive the distribution of the final epidemic size and severity for this model and provide some general examples. Next, we focus on a single infected individual facing a given number of susceptibles, and we determine the distribution of his outcome (number of contaminations, severity, type of removal). Using a discrete-time formulation of the model, we show that this distribution also provides us with an alternative, more stable method to compute the final epidemic outcome distribution.
$\rightarrow$ removed) model in which the infectious periods are modulated by a collection of independent and identically distributed Feller processes. Each infected individual is associated with one of these processes, the trajectories of which determine the duration of his infectious period, his contamination rate, and his type of removal (e.g. death or immunization). We use a martingale approach to derive the distribution of the final epidemic size and severity for this model and provide some general examples. Next, we focus on a single infected individual facing a given number of susceptibles, and we determine the distribution of his outcome (number of contaminations, severity, type of removal). Using a discrete-time formulation of the model, we show that this distribution also provides us with an alternative, more stable method to compute the final epidemic outcome distribution.
The virtuous smart city: Bridging the gap between ethical principles and practices of data-driven innovation
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 02 May 2023, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A large deviation theorem for a supercritical super-Brownian motion with absorption
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 02 May 2023, pp. 1249-1274
- Print publication:
- December 2023
-
- Article
- Export citation
-
We consider a one-dimensional superprocess with a supercritical local branching mechanism
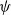 $\psi$, where particles move as a Brownian motion with drift
$\psi$, where particles move as a Brownian motion with drift 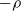 $-\rho$ and are killed when they reach the origin. It is known that the process survives with positive probability if and only if
$-\rho$ and are killed when they reach the origin. It is known that the process survives with positive probability if and only if 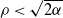 $\rho<\sqrt{2\alpha}$, where
$\rho<\sqrt{2\alpha}$, where 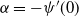 $\alpha=-\psi'(0)$. When
$\alpha=-\psi'(0)$. When 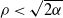 $\rho<\sqrt{2 \alpha}$, Kyprianou et al. [18] proved that
$\rho<\sqrt{2 \alpha}$, Kyprianou et al. [18] proved that 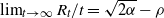 $\lim_{t\to \infty}R_t/t =\sqrt{2\alpha}-\rho$ almost surely on the survival set, where
$\lim_{t\to \infty}R_t/t =\sqrt{2\alpha}-\rho$ almost surely on the survival set, where 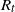 $R_t$ is the rightmost position of the support at time t. Motivated by this work, we investigate its large deviation, in other words, the convergence rate of
$R_t$ is the rightmost position of the support at time t. Motivated by this work, we investigate its large deviation, in other words, the convergence rate of 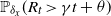 $\mathbb{P}_{\delta_x} (R_t >\gamma t+\theta)$ as
$\mathbb{P}_{\delta_x} (R_t >\gamma t+\theta)$ as 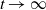 $t \to \infty$, where
$t \to \infty$, where 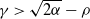 $\gamma >\sqrt{2 \alpha} -\rho$,
$\gamma >\sqrt{2 \alpha} -\rho$, 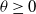 $\theta \ge 0$. As a by-product, a related Yaglom-type conditional limit theorem is obtained. Analogous results for branching Brownian motion can be found in Harris et al. [13].
$\theta \ge 0$. As a by-product, a related Yaglom-type conditional limit theorem is obtained. Analogous results for branching Brownian motion can be found in Harris et al. [13].
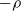
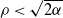
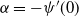
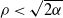
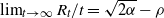
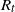
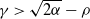
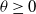
Maximal chordal subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 02 May 2023, pp. 724-741
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A chordal graph is a graph with no induced cycles of length at least
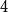 $4$. Let
$4$. Let 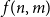 $f(n,m)$ be the maximal integer such that every graph with
$f(n,m)$ be the maximal integer such that every graph with  $n$ vertices and
$n$ vertices and 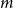 $m$ edges has a chordal subgraph with at least
$m$ edges has a chordal subgraph with at least 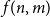 $f(n,m)$ edges. In 1985 Erdős and Laskar posed the problem of estimating
$f(n,m)$ edges. In 1985 Erdős and Laskar posed the problem of estimating 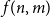 $f(n,m)$. In the late 1980s, Erdős, Gyárfás, Ordman and Zalcstein determined the value of
$f(n,m)$. In the late 1980s, Erdős, Gyárfás, Ordman and Zalcstein determined the value of 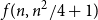 $f(n,n^2/4+1)$ and made a conjecture on the value of
$f(n,n^2/4+1)$ and made a conjecture on the value of 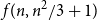 $f(n,n^2/3+1)$. In this paper we prove this conjecture and answer the question of Erdős and Laskar, determining
$f(n,n^2/3+1)$. In this paper we prove this conjecture and answer the question of Erdős and Laskar, determining 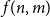 $f(n,m)$ asymptotically for all
$f(n,m)$ asymptotically for all 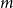 $m$ and exactly for
$m$ and exactly for 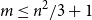 $m \leq n^2/3+1$.
$m \leq n^2/3+1$.
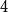
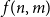

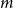
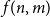
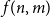
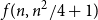
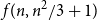
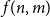
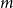
Estimating the VaR-induced Euler allocation rule
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 02 May 2023, pp. 619-635
- Print publication:
- September 2023
-
- Article
- Export citation
Prevalence of respiratory pathogens and risk of developing pneumonia under non-pharmaceutical interventions in Suzhou, China
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 02 May 2023, e82
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ON THE SIZE CONTROL OF THE HYBRID TEST FOR SUPERIOR PREDICTIVE ABILITY
-
- Journal:
- Econometric Theory / Volume 40 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 02 May 2023, pp. 213-232
-
- Article
- Export citation
-
This article analyzes the theoretical properties of the hybrid test for superior predictive ability. A simple example reveals that the test may not be size-controlled at common significance levels with rejection rates exceeding
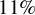 $11\%$ at a
$11\%$ at a 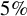 $5\%$ nominal level. Generalizing this observation, the main results show the pointwise asymptotic invalidity of the hybrid test under reasonable conditions. Monte Carlo simulations support these theoretical findings.
$5\%$ nominal level. Generalizing this observation, the main results show the pointwise asymptotic invalidity of the hybrid test under reasonable conditions. Monte Carlo simulations support these theoretical findings.
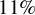
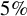
ASB volume 53 issue 2 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 12 May 2023, pp. f1-f2
- Print publication:
- May 2023
-
- Article
-
- You have access
- Export citation
ASB volume 53 issue 2 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 12 May 2023, pp. b1-b3
- Print publication:
- May 2023
-
- Article
-
- You have access
- Export citation
Mandatory and seasonal vaccination against COVID-19: Attitudes of the vaccinated people in Serbia
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 28 April 2023, e83
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring the effect of novel six moments on hand hygiene compliance among hospital cleaning staff members: a quasi-experimental study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 28 April 2023, e73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Effectiveness of near-UVA in SARS-CoV-2 inactivation
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 27 April 2023, e76
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Circulation and colonisation of Blastocystis subtypes in schoolchildren of various ethnicities in rural northern Thailand
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 27 April 2023, e77
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mixing time bounds for edge flipping on regular graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 26 April 2023, pp. 1317-1332
- Print publication:
- December 2023
-
- Article
- Export citation
-
An edge flipping is a non-reversible Markov chain on a given connected graph, as defined in Chung and Graham (2012). In the same paper, edge flipping eigenvalues and stationary distributions for some classes of graphs were identified. We further study edge flipping spectral properties to show a lower bound for the rate of convergence in the case of regular graphs. Moreover, we show by a coupling argument that a cutoff occurs at
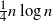 $\frac{1}{4} n \log n$ for the edge flipping on the complete graph.
$\frac{1}{4} n \log n$ for the edge flipping on the complete graph.
Uniform-in-phase-space data selection with iterative normalizing flows
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 25 April 2023, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
