Refine search
Actions for selected content:
53194 results in Statistics and Probability
Tail variance allocation, Shapley value, and the majorization problem
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 06 June 2023, pp. 153-171
- Print publication:
- March 2024
-
- Article
- Export citation
Propagation of chaos and large deviations in mean-field models with jumps on block-structured networks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 05 June 2023, pp. 1301-1361
- Print publication:
- December 2023
-
- Article
- Export citation
Homogenization of non-symmetric jump processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 05 June 2023, pp. 1-33
- Print publication:
- March 2024
-
- Article
- Export citation
Exact convergence analysis for metropolis–hastings independence samplers in Wasserstein distances
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 05 June 2023, pp. 33-54
- Print publication:
- March 2024
-
- Article
- Export citation
Upper large deviations for power-weighted edge lengths in spatial random networks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 05 June 2023, pp. 34-70
- Print publication:
- March 2024
-
- Article
- Export citation
-
We study the large-volume asymptotics of the sum of power-weighted edge lengths
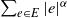 $\sum_{e \in E}|e|^\alpha$ in Poisson-based spatial random networks. In the regime
$\sum_{e \in E}|e|^\alpha$ in Poisson-based spatial random networks. In the regime 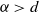 $\alpha > d$, we provide a set of sufficient conditions under which the upper-large-deviation asymptotics are characterized by a condensation phenomenon, meaning that the excess is caused by a negligible portion of Poisson points. Moreover, the rate function can be expressed through a concrete optimization problem. This framework encompasses in particular directed, bidirected, and undirected variants of the k-nearest-neighbor graph, as well as suitable
$\alpha > d$, we provide a set of sufficient conditions under which the upper-large-deviation asymptotics are characterized by a condensation phenomenon, meaning that the excess is caused by a negligible portion of Poisson points. Moreover, the rate function can be expressed through a concrete optimization problem. This framework encompasses in particular directed, bidirected, and undirected variants of the k-nearest-neighbor graph, as well as suitable 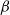 $\beta$-skeletons.
$\beta$-skeletons.
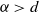
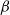
Moderate deviations inequalities for Gaussian process regression
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 05 June 2023, pp. 172-197
- Print publication:
- March 2024
-
- Article
- Export citation
Circulation and colonisation of Blastocystis subtypes in schoolchildren of various ethnicities in rural northern Thailand – Erratum
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 02 June 2023, e85
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Extropy: Characterizations and dynamic versions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 02 June 2023, pp. 1333-1351
- Print publication:
- December 2023
-
- Article
- Export citation
Fit for purpose? The patents regime, the Fourth Industrial Revolution, and sustainable development
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 02 June 2023, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Bayesian Filtering and Smoothing
-
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023

Time Series for Data Scientists
- Data Management, Description, Modeling and Forecasting
-
- Published online:
- 01 June 2023
- Print publication:
- 11 May 2023
-
- Textbook
- Export citation
Modelling the impact of COVID-19 and routine MenACWY vaccination on meningococcal carriage and disease in the UK
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 01 June 2023, e98
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unavoidable patterns in locally balanced colourings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 01 June 2023, pp. 796-808
-
- Article
- Export citation
-
Which patterns must a two-colouring of
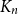 $K_n$ contain if each vertex has at least
$K_n$ contain if each vertex has at least 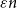 $\varepsilon n$ red and
$\varepsilon n$ red and 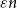 $\varepsilon n$ blue neighbours? We show that when
$\varepsilon n$ blue neighbours? We show that when 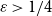 $\varepsilon \gt 1/4$,
$\varepsilon \gt 1/4$, 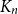 $K_n$ must contain a complete subgraph on
$K_n$ must contain a complete subgraph on 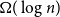 $\Omega (\log n)$ vertices where one of the colours forms a balanced complete bipartite graph.
$\Omega (\log n)$ vertices where one of the colours forms a balanced complete bipartite graph.When
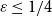 $\varepsilon \leq 1/4$, this statement is no longer true, as evidenced by the following colouring
$\varepsilon \leq 1/4$, this statement is no longer true, as evidenced by the following colouring 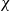 $\chi$ of
$\chi$ of 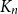 $K_n$. Divide the vertex set into
$K_n$. Divide the vertex set into 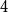 $4$ parts nearly equal in size as
$4$ parts nearly equal in size as 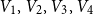 $V_1,V_2,V_3, V_4$, and let the blue colour class consist of the edges between
$V_1,V_2,V_3, V_4$, and let the blue colour class consist of the edges between 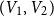 $(V_1,V_2)$,
$(V_1,V_2)$, 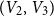 $(V_2,V_3)$,
$(V_2,V_3)$, 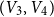 $(V_3,V_4)$, and the edges contained inside
$(V_3,V_4)$, and the edges contained inside 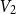 $V_2$ and inside
$V_2$ and inside 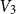 $V_3$. Surprisingly, we find that this obstruction is unique in the following sense. Any two-colouring of
$V_3$. Surprisingly, we find that this obstruction is unique in the following sense. Any two-colouring of 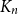 $K_n$ in which each vertex has at least
$K_n$ in which each vertex has at least 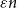 $\varepsilon n$ red and
$\varepsilon n$ red and 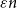 $\varepsilon n$ blue neighbours (with
$\varepsilon n$ blue neighbours (with 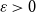 $\varepsilon \gt 0$) contains a vertex set
$\varepsilon \gt 0$) contains a vertex set 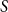 $S$ of order
$S$ of order 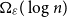 $\Omega _{\varepsilon }(\log n)$ on which one colour class forms a balanced complete bipartite graph, or which has the same colouring as
$\Omega _{\varepsilon }(\log n)$ on which one colour class forms a balanced complete bipartite graph, or which has the same colouring as 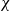 $\chi$.
$\chi$.
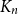
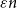
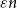
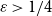
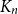
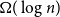
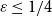
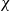
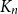
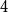
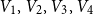
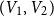
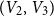
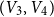
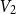
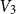
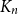
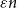
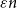
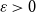
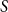
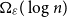
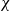
SPECIFICATION TESTS FOR TIME-VARYING COEFFICIENT PANEL DATA MODELS
-
- Journal:
- Econometric Theory / Volume 41 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 01 June 2023, pp. 123-170
-
- Article
- Export citation
One health surveillance strategy for coronaviruses in Italian wildlife
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 01 June 2023, e96
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bootstrap percolation in random geometric graphs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 31 May 2023, pp. 1254-1300
- Print publication:
- December 2023
-
- Article
- Export citation
-
Following Bradonjić and Saniee, we study a model of bootstrap percolation on the Gilbert random geometric graph on the 2-dimensional torus. In this model, the expected number of vertices of the graph is n, and the expected degree of a vertex is
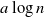 $a\log n$ for some fixed
$a\log n$ for some fixed 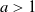 $a>1$. Each vertex is added with probability p to a set
$a>1$. Each vertex is added with probability p to a set 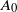 $A_0$ of initially infected vertices. Vertices subsequently become infected if they have at least
$A_0$ of initially infected vertices. Vertices subsequently become infected if they have at least 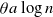 $ \theta a \log n $ infected neighbours. Here
$ \theta a \log n $ infected neighbours. Here 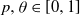 $p, \theta \in [0,1]$ are taken to be fixed constants.
$p, \theta \in [0,1]$ are taken to be fixed constants.We show that if
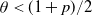 $\theta < (1+p)/2$, then a sufficiently large local outbreak leads with high probability to the infection spreading globally, with all but o(n) vertices eventually becoming infected. On the other hand, for
$\theta < (1+p)/2$, then a sufficiently large local outbreak leads with high probability to the infection spreading globally, with all but o(n) vertices eventually becoming infected. On the other hand, for 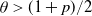 $ \theta > (1+p)/2$, even if one adversarially infects every vertex inside a ball of radius
$ \theta > (1+p)/2$, even if one adversarially infects every vertex inside a ball of radius 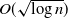 $O(\sqrt{\log n} )$, with high probability the infection will spread to only o(n) vertices beyond those that were initially infected.
$O(\sqrt{\log n} )$, with high probability the infection will spread to only o(n) vertices beyond those that were initially infected.In addition we give some bounds on the
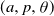 $(a, p, \theta)$ regions ensuring the emergence of large local outbreaks or the existence of islands of vertices that never become infected. We also give a complete picture of the (surprisingly complex) behaviour of the analogous 1-dimensional bootstrap percolation model on the circle. Finally we raise a number of problems, and in particular make a conjecture on an ‘almost no percolation or almost full percolation’ dichotomy which may be of independent interest.
$(a, p, \theta)$ regions ensuring the emergence of large local outbreaks or the existence of islands of vertices that never become infected. We also give a complete picture of the (surprisingly complex) behaviour of the analogous 1-dimensional bootstrap percolation model on the circle. Finally we raise a number of problems, and in particular make a conjecture on an ‘almost no percolation or almost full percolation’ dichotomy which may be of independent interest.
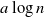
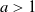
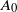
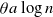
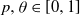
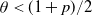
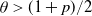
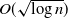
How valid is the 2- to 10-day incubation period for cases of Legionnaires’ disease?: A reappraisal in the context of the German LeTriWa study; Berlin, 2016–2020
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 29 May 2023, e97
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A confirmation of a conjecture on Feldman’s two-armed bandit problem
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 26 May 2023, pp. 121-136
- Print publication:
- March 2024
-
- Article
- Export citation
The winner takes it all but one
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 26 May 2023, pp. 137-152
- Print publication:
- March 2024
-
- Article
- Export citation
-
We study competing first passage percolation on graphs generated by the configuration model with infinite-mean degrees. Initially, two uniformly chosen vertices are infected with a type 1 and type 2 infection, respectively, and the infection then spreads via nearest neighbors in the graph. The time it takes for the type 1 (resp. 2) infection to traverse an edge e is given by a random variable
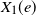 $X_1(e)$ (resp.
$X_1(e)$ (resp. 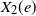 $X_2(e)$) and, if the vertex at the other end of the edge is still uninfected, it then becomes type 1 (resp. 2) infected and immune to the other type. Assuming that the degrees follow a power-law distribution with exponent
$X_2(e)$) and, if the vertex at the other end of the edge is still uninfected, it then becomes type 1 (resp. 2) infected and immune to the other type. Assuming that the degrees follow a power-law distribution with exponent 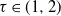 $\tau \in (1,2)$, we show that with high probability as the number of vertices tends to infinity, one of the infection types occupies all vertices except for the starting point of the other type. Moreover, both infections have a positive probability of winning regardless of the passage-time distribution. The result is also shown to hold for the erased configuration model, where self-loops are erased and multiple edges are merged, and when the degrees are conditioned to be smaller than
$\tau \in (1,2)$, we show that with high probability as the number of vertices tends to infinity, one of the infection types occupies all vertices except for the starting point of the other type. Moreover, both infections have a positive probability of winning regardless of the passage-time distribution. The result is also shown to hold for the erased configuration model, where self-loops are erased and multiple edges are merged, and when the degrees are conditioned to be smaller than 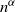 $n^\alpha$ for some
$n^\alpha$ for some 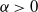 $\alpha\gt 0$.
$\alpha\gt 0$.
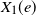
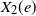
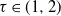
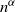
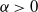
10 - Model Estimation and Types of Data
- from Part IV - Model Construction and Evaluation
-
- Book:
- Nonlife Actuarial Models
- Published online:
- 07 July 2023
- Print publication:
- 25 May 2023, pp 255-273
-
- Chapter
- Export citation
