Refine search
Actions for selected content:
53194 results in Statistics and Probability
16 - Parameter Estimation
-
- Book:
- Bayesian Filtering and Smoothing
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 319-348
-
- Chapter
- Export citation
8 - General Gaussian Filtering
-
- Book:
- Bayesian Filtering and Smoothing
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 131-167
-
- Chapter
- Export citation
5 - Modeling with State Space Models
-
- Book:
- Bayesian Filtering and Smoothing
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 73-90
-
- Chapter
- Export citation
4 - Discretization of Continuous-Time Dynamic Models
-
- Book:
- Bayesian Filtering and Smoothing
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 44-72
-
- Chapter
- Export citation
15 - Particle Smoothing
-
- Book:
- Bayesian Filtering and Smoothing
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 308-318
-
- Chapter
- Export citation
9 - Gaussian Filtering by Enabling Approximations
-
- Book:
- Bayesian Filtering and Smoothing
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 168-203
-
- Chapter
- Export citation
Preface
-
- Book:
- Bayesian Filtering and Smoothing
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp xi-xiv
-
- Chapter
- Export citation
11 - Particle Filtering
-
- Book:
- Bayesian Filtering and Smoothing
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 229-252
-
- Chapter
- Export citation
Analysis of declining trends in sugarcane yield at Wonji-Shoa Sugar Estate, Central Ethiopia
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 14 June 2023, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An outbreak of nosocomial infection of neonatal aseptic meningitis caused by echovirus 18
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 June 2023, e107
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association between socioeconomic deprivation and incidence of infectious intestinal disease by pathogen and linked transmission route: An ecological analysis in the UK
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 June 2023, e109
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Some comments on “A Hermite spline approach for modelling population mortality” by Tang, Li & Tickle (2022)
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 3 / November 2023
- Published online by Cambridge University Press:
- 13 June 2023, pp. 643-646
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Archaeology of random recursive dags and Cooper-Frieze random networks
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 13 June 2023, pp. 859-873
-
- Article
- Export citation
A fourth way to the digital transformation: The data republic as a fair data ecosystem
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 12 June 2023, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On relevation redundancy to coherent systems at component and system levels
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 09 June 2023, pp. 104-120
- Print publication:
- March 2024
-
- Article
- Export citation
No arbitrage and multiplicative special semimartingales
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 09 June 2023, pp. 1033-1074
- Print publication:
- September 2023
-
- Article
- Export citation
Conditions for indexability of restless bandits and an
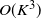 $O(K^3)$ algorithm to compute whittle index – CORRIGENDUM
$O(K^3)$ algorithm to compute whittle index – CORRIGENDUM
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 09 June 2023, pp. 1473-1474
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
Investigating association between inflammatory bowel disease and rotavirus vaccination in a paediatric cohort in the UK
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 09 June 2023, e103
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Explosion of continuous-state branching processes with competition in a Lévy environment
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 09 June 2023, pp. 68-81
- Print publication:
- March 2024
-
- Article
- Export citation
Comparing Mycobacterium tuberculosis transmission reconstruction models from whole genome sequence data
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 09 June 2023, e105
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
