Refine search
Actions for selected content:
53194 results in Statistics and Probability
Dedication
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp v-vi
-
- Chapter
- Export citation
Prologue
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp xxxviii-xxxviii
-
- Chapter
- Export citation
Contents
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp vii-vii
-
- Chapter
- Export citation
Chapter 10 - Healthcare Decision-Making for Cost-Effectiveness
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp 244-285
-
- Chapter
- Export citation
Chapter 3 - Software
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp 55-90
-
- Chapter
- Export citation
Introduction
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp xxxix-xlii
-
- Chapter
- Export citation
About the Author
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp xviii-xviii
-
- Chapter
- Export citation
Chapter 8 - How Are Group Decisions Practiced in Healthcare?
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp 199-211
-
- Chapter
- Export citation
Tables
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp xii-xvii
-
- Chapter
- Export citation
Chapter 6 - Why Models Are Important in Healthcare
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp 156-187
-
- Chapter
- Export citation
Preface
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp xix-xx
-
- Chapter
- Export citation
Chapter 11 - Risk Analysis in Healthcare Decision-Making
-
- Book:
- Data-Guided Healthcare Decision Making
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023, pp 286-311
-
- Chapter
- Export citation
Transitions between peace and systemic war as bifurcations in a signed network dynamical system
-
- Journal:
- Network Science / Volume 11 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 21 June 2023, pp. 458-501
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Information-theoretic convergence of extreme values to the Gumbel distribution
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 21 June 2023, pp. 244-254
- Print publication:
- March 2024
-
- Article
- Export citation
City data ecosystems between theory and practice: A qualitative exploratory study in seven European cities – CORRIGENDUM
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 20 June 2023, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Handedness and test anxiety: An examination of mixed-handed and consistent-handed students
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 20 June 2023, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Test anxiety refers to maladaptive cognitive and physiological reactions that interfere with optimal performance. Self-regulatory models suggest test anxiety occurs when there is a perceived discrepancy between current functioning and mental representations of desired academic goals. Interestingly, prior investigations have demonstrated those with greater interhemispheric communication are better able to detect discrepancies between current functioning and preexisting mental representations. Thus, the current study was designed to investigate the relationship between test anxiety and handedness—a commonly used proxy variable for interhemispheric communication. Undergraduate and graduate students (N = 277, 85.20% female, 68.19% Caucasian,
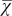 $ \overline{\chi} $age = 29.88) (SD = 9.53) completed the FRIEDBEN Test Anxiety Scale and Edinburgh Handedness Inventory – Short Form. A series of Mann–Whitney U tests were used to test for differences in the cognitive, physiological, and social components of test anxiety between mixed- and consistent-handers. The results indicated that mixed-handers had significantly higher levels of cognitive test anxiety than consistent-handers. We believe this information has important implications for our understanding of the role of discrepancy detection and interhemispheric communication in eliciting and maintaining test-anxious responses.
$ \overline{\chi} $age = 29.88) (SD = 9.53) completed the FRIEDBEN Test Anxiety Scale and Edinburgh Handedness Inventory – Short Form. A series of Mann–Whitney U tests were used to test for differences in the cognitive, physiological, and social components of test anxiety between mixed- and consistent-handers. The results indicated that mixed-handers had significantly higher levels of cognitive test anxiety than consistent-handers. We believe this information has important implications for our understanding of the role of discrepancy detection and interhemispheric communication in eliciting and maintaining test-anxious responses.
Continuous-time locally stationary time series models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 20 June 2023, pp. 965-998
- Print publication:
- September 2023
-
- Article
- Export citation
Responding to Africa’s burden of disease: accelerating progress
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 20 June 2023, e114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Monotonicity of implied volatility for perpetual put options
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 19 June 2023, pp. 301-310
- Print publication:
- March 2024
-
- Article
- Export citation
Estimates of mpox effective reproduction number in Spain, April–August 2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 16 June 2023, e112
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
