Refine search
Actions for selected content:
53194 results in Statistics and Probability
Identification of post-COVID-19 condition phenotypes, and differences in health-related quality of life and healthcare use: a cluster analysis
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 18 July 2023, e123
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using molecular network analysis to understand current HIV-1 transmission characteristics in an inland area of Yunnan, China
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 18 July 2023, e124
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ratemaking in a changing environment
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 18 July 2023, pp. 596-618
- Print publication:
- September 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Local Data Spaces: Leveraging trusted research environments for secure location-based policy research in the age of coronavirus disease-2019 – CORRIGENDUM
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 17 July 2023, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Artificial intelligence and algorithmic decisions in fraud detection: An interpretive structural model
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 14 July 2023, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Petty bribery, pluralistic ignorance, and the collective action problem
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 14 July 2023, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk management with local least squares Monte Carlo
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 14 July 2023, pp. 489-514
- Print publication:
- September 2023
-
- Article
- Export citation
Asymptotic expansion of the expected Minkowski functional for isotropic central limit random fields
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 14 July 2023, pp. 1390-1414
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation

Data-Guided Healthcare Decision Making
-
- Published online:
- 13 July 2023
- Print publication:
- 22 June 2023
Assessing pig farm biosecurity measures for the control of Salmonella on European farms
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 13 July 2023, e130
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hepatitis E virus seroprevalence among employees in catering and public place industries in Nanjing, China
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 13 July 2023, e122
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On off-line and on-line Bayesian filtering for uncertainty quantification of structural deterioration
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 13 July 2023, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Poliovirus outbreak in New York State, August 2022: qualitative assessment of immediate public health responses and priorities for improving vaccine coverage
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 12 July 2023, e120
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ALGORITHMIC SUBSAMPLING UNDER MULTIWAY CLUSTERING
-
- Journal:
- Econometric Theory / Volume 41 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 11 July 2023, pp. 79-122
-
- Article
-
- You have access
- Open access
- Export citation
Portfolio management for insurers and pension funds and COVID-19: targeting volatility for equity, balanced, and target-date funds with leverage constraints
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 11 July 2023, pp. 78-101
-
- Article
- Export citation
Reinsurance games with
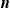 $\boldsymbol{{n}}$ variance-premium reinsurers: from tree to chain
$\boldsymbol{{n}}$ variance-premium reinsurers: from tree to chain
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 11 July 2023, pp. 706-728
- Print publication:
- September 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Invasive listeriosis in Finland: surveillance and cluster investigations, 2011–2021
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 10 July 2023, e118
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PDE for the joint law of the pair of a continuous diffusion and its running maximum
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 10 July 2023, pp. 1171-1210
- Print publication:
- December 2023
-
- Article
- Export citation
-
Let X be a d-dimensional diffusion and M the running supremum of its first component. In this paper, we show that for any
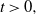 $t>0,$ the density (with respect to the
$t>0,$ the density (with respect to the 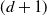 $(d+1)$-dimensional Lebesgue measure) of the pair
$(d+1)$-dimensional Lebesgue measure) of the pair 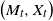 $\big(M_t,X_t\big)$ is a weak solution of a Fokker–Planck partial differential equation on the closed set
$\big(M_t,X_t\big)$ is a weak solution of a Fokker–Planck partial differential equation on the closed set 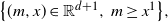 $\big\{(m,x)\in \mathbb{R}^{d+1},\,{m\geq x^1}\big\},$ using an integral expansion of this density.
$\big\{(m,x)\in \mathbb{R}^{d+1},\,{m\geq x^1}\big\},$ using an integral expansion of this density.
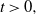
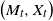
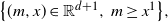
Incidence of SARS-CoV-2 infection and associated risk factors among staff and residents at homeless shelters in King County, Washington: an active surveillance study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 10 July 2023, e129
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cross-language validation of COVID-19 Compliance Scale in 28 languages
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 10 July 2023, e119
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
