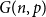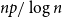Refine search
Actions for selected content:
53194 results in Statistics and Probability
JPR volume 60 issue 3 Cover and Back matter
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 August 2023, pp. b1-b2
- Print publication:
- September 2023
-
- Article
-
- You have access
- Export citation
Concerns, perceived risk, and hesitancy on COVID-19 vaccine: a qualitative exploration among university students living in the West Bank
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 07 August 2023, e139
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bootstrap percolation in inhomogeneous random graphs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 07 August 2023, pp. 156-204
- Print publication:
- March 2024
-
- Article
- Export citation
-
A bootstrap percolation process on a graph with n vertices is an ‘infection’ process evolving in rounds. Let
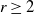 $r \ge 2$ be fixed. Initially, there is a subset of infected vertices. In each subsequent round, every uninfected vertex that has at least r infected neighbors becomes infected as well and remains so forever.
$r \ge 2$ be fixed. Initially, there is a subset of infected vertices. In each subsequent round, every uninfected vertex that has at least r infected neighbors becomes infected as well and remains so forever.We consider this process in the case where the underlying graph is an inhomogeneous random graph whose kernel is of rank one. Assuming that initially every vertex is infected independently with probability
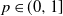 $p \in (0,1]$, we provide a law of large numbers for the size of the set of vertices that are infected by the end of the process. Moreover, we investigate the case
$p \in (0,1]$, we provide a law of large numbers for the size of the set of vertices that are infected by the end of the process. Moreover, we investigate the case 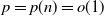 $p = p(n) = o(1)$, and we focus on the important case of inhomogeneous random graphs exhibiting a power-law degree distribution with exponent
$p = p(n) = o(1)$, and we focus on the important case of inhomogeneous random graphs exhibiting a power-law degree distribution with exponent 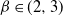 $\beta \in (2,3)$. The first two authors have shown in this setting the existence of a critical
$\beta \in (2,3)$. The first two authors have shown in this setting the existence of a critical 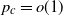 $p_c =o(1)$ such that, with high probability, if
$p_c =o(1)$ such that, with high probability, if 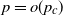 $p =o(p_c)$, then the process does not evolve at all, whereas if
$p =o(p_c)$, then the process does not evolve at all, whereas if 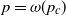 $p = \omega(p_c)$, then the final set of infected vertices has size
$p = \omega(p_c)$, then the final set of infected vertices has size 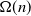 $\Omega(n)$. In this work we determine the asymptotic fraction of vertices that will eventually be infected and show that it also satisfies a law of large numbers.
$\Omega(n)$. In this work we determine the asymptotic fraction of vertices that will eventually be infected and show that it also satisfies a law of large numbers.
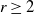
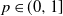
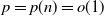
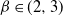
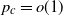
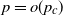
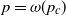
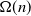
The proportion of triangles in a class of anisotropic Poisson line tessellations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 07 August 2023, pp. 214-229
- Print publication:
- March 2024
-
- Article
- Export citation
-
Stationary Poisson processes of lines in the plane are studied, whose directional distributions are concentrated on
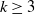 $k\geq 3$ equally spread directions. The random lines of such processes decompose the plane into a collection of random polygons, which form a so-called Poisson line tessellation. The focus of this paper is to determine the proportion of triangles in such tessellations, or equivalently, the probability that the typical cell is a triangle. As a by-product, a new deviation of Miles’s classical result for the isotropic case is obtained by an approximation argument.
$k\geq 3$ equally spread directions. The random lines of such processes decompose the plane into a collection of random polygons, which form a so-called Poisson line tessellation. The focus of this paper is to determine the proportion of triangles in such tessellations, or equivalently, the probability that the typical cell is a triangle. As a by-product, a new deviation of Miles’s classical result for the isotropic case is obtained by an approximation argument.
APR volume 55 issue 3 Cover and Back matter
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 August 2023, pp. b1-b2
- Print publication:
- September 2023
-
- Article
-
- You have access
- Export citation
Chase–escape in dynamic device-to-device networks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 07 August 2023, pp. 311-339
- Print publication:
- March 2024
-
- Article
- Export citation
JPR volume 60 issue 3 Cover and Front matter
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 August 2023, pp. f1-f2
- Print publication:
- September 2023
-
- Article
-
- You have access
- Export citation
APR volume 55 issue 3 Cover and Front matter
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 August 2023, pp. f1-f2
- Print publication:
- September 2023
-
- Article
-
- You have access
- Export citation
ECT volume 39 issue 4 Cover and Back matter
-
- Journal:
- Econometric Theory / Volume 39 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 04 August 2023, pp. b1-b2
-
- Article
-
- You have access
- Export citation
ECT volume 39 issue 4 Cover and Front matter
-
- Journal:
- Econometric Theory / Volume 39 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 04 August 2023, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Evaluation of a rapid diagnostic test for measles IgM detection; accuracy and the reliability of visual reading using sera from the measles surveillance programme in Brazil, 2015
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 04 August 2023, e151
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Duality theory for exponential utility-based hedging in the Almgren–Chriss model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 03 August 2023, pp. 420-438
- Print publication:
- June 2024
-
- Article
- Export citation
Plant growth stages and weather index insurance design
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 3 / November 2023
- Published online by Cambridge University Press:
- 03 August 2023, pp. 438-458
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
IDENTIFICATION AND INFERENCE IN A QUANTILE REGRESSION DISCONTINUITY DESIGN UNDER RANK SIMILARITY WITH COVARIATES
-
- Journal:
- Econometric Theory / Volume 41 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 02 August 2023, pp. 172-217
-
- Article
- Export citation
Prevalence and shared risk factors of HIV in three key populations in Vietnam: A systematic review and meta-analysis
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 01 August 2023, e138
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Worst-case Omega ratio under distribution uncertainty with its application in robust portfolio selection
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 01 August 2023, pp. 318-340
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the joint survival probability of two collaborating firms
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 01 August 2023, pp. 369-384
- Print publication:
- June 2024
-
- Article
- Export citation
On the exponential growth rates of lattice animals and interfaces
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 31 July 2023, pp. 912-955
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We introduce a formula for translating any upper bound on the percolation threshold of a lattice
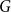 $G$ into a lower bound on the exponential growth rate of lattice animals
$G$ into a lower bound on the exponential growth rate of lattice animals 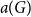 $a(G)$ and vice versa. We exploit this in both directions. We obtain the rigorous lower bound
$a(G)$ and vice versa. We exploit this in both directions. We obtain the rigorous lower bound 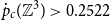 ${\dot{p}_c}({\mathbb{Z}}^3)\gt 0.2522$ for 3-dimensional site percolation. We also improve on the best known asymptotic bounds on
${\dot{p}_c}({\mathbb{Z}}^3)\gt 0.2522$ for 3-dimensional site percolation. We also improve on the best known asymptotic bounds on 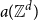 $a({\mathbb{Z}}^d)$ as
$a({\mathbb{Z}}^d)$ as 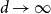 $d\to \infty$. Our formula remains valid if instead of lattice animals we enumerate certain subspecies called interfaces. Enumerating interfaces leads to functional duality formulas that are tightly connected to percolation and are not valid for lattice animals, as well as to strict inequalities for the percolation threshold.
$d\to \infty$. Our formula remains valid if instead of lattice animals we enumerate certain subspecies called interfaces. Enumerating interfaces leads to functional duality formulas that are tightly connected to percolation and are not valid for lattice animals, as well as to strict inequalities for the percolation threshold.Incidentally, we prove that the rate of the exponential decay of the cluster size distribution of Bernoulli percolation is a continuous function of
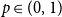 $p\in (0,1)$.
$p\in (0,1)$.
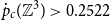
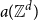
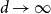
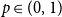
A diagnostic model based on routine blood examination for serious bacterial infections in neonates–a cross-sectional study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 31 July 2023, e137
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Limiting empirical spectral distribution for the non-backtracking matrix of an Erdős-Rényi random graph
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 31 July 2023, pp. 956-973
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this note, we give a precise description of the limiting empirical spectral distribution for the non-backtracking matrices for an Erdős-Rényi graph
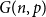 $G(n,p)$ assuming
$G(n,p)$ assuming 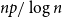 $np/\log n$ tends to infinity. We show that derandomizing part of the non-backtracking random matrix simplifies the spectrum considerably, and then, we use Tao and Vu’s replacement principle and the Bauer-Fike theorem to show that the partly derandomized spectrum is, in fact, very close to the original spectrum.
$np/\log n$ tends to infinity. We show that derandomizing part of the non-backtracking random matrix simplifies the spectrum considerably, and then, we use Tao and Vu’s replacement principle and the Bauer-Fike theorem to show that the partly derandomized spectrum is, in fact, very close to the original spectrum.