Refine search
Actions for selected content:
53194 results in Statistics and Probability
Understanding the disease and economic impact of avirulent avian paramyxovirus type 1 (APMV-1) infection in Great Britain
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 25 August 2023, e163
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Typologies of duocentric networks among low-income newlywed couples
-
- Journal:
- Network Science / Volume 11 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 25 August 2023, pp. 632-656
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mortality associated with Omicron and influenza infections in France before and during the COVID-19 pandemic
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 25 August 2023, e148
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Algorithmic High-Dimensional Robust Statistics
-
- Published online:
- 24 August 2023
- Print publication:
- 07 September 2023
Detection and treatment of outliers for multivariate robust loss reserving
- Part of
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 24 August 2023, pp. 102-125
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interlacement limit of a stopped random walk trace on a torus
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 24 August 2023, pp. 354-388
- Print publication:
- March 2024
-
- Article
- Export citation
-
We consider a simple random walk on
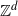 $\mathbb{Z}^d$ started at the origin and stopped on its first exit time from
$\mathbb{Z}^d$ started at the origin and stopped on its first exit time from 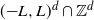 $({-}L,L)^d \cap \mathbb{Z}^d$. Write L in the form
$({-}L,L)^d \cap \mathbb{Z}^d$. Write L in the form 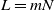 $L = m N$ with
$L = m N$ with 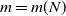 $m = m(N)$ and N an integer going to infinity in such a way that
$m = m(N)$ and N an integer going to infinity in such a way that 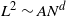 $L^2 \sim A N^d$ for some real constant
$L^2 \sim A N^d$ for some real constant 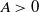 $A \gt 0$. Our main result is that for
$A \gt 0$. Our main result is that for 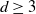 $d \ge 3$, the projection of the stopped trajectory to the N-torus locally converges, away from the origin, to an interlacement process at level
$d \ge 3$, the projection of the stopped trajectory to the N-torus locally converges, away from the origin, to an interlacement process at level 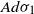 $A d \sigma_1$, where
$A d \sigma_1$, where 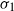 $\sigma_1$ is the exit time of a Brownian motion from the unit cube
$\sigma_1$ is the exit time of a Brownian motion from the unit cube 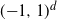 $({-}1,1)^d$ that is independent of the interlacement process. The above problem is a variation on results of Windisch (2008) and Sznitman (2009).
$({-}1,1)^d$ that is independent of the interlacement process. The above problem is a variation on results of Windisch (2008) and Sznitman (2009).
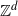
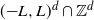
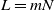
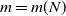
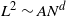
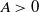
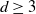
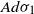
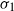
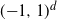
Exchangeable FGM copulas
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 24 August 2023, pp. 205-234
- Print publication:
- March 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Freedom and choice: public attitudes seven years on
-
- Journal:
- British Actuarial Journal / Volume 28 / 2023
- Published online by Cambridge University Press:
- 23 August 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Strong convergence of peaks over a threshold
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 23 August 2023, pp. 529-539
- Print publication:
- June 2024
-
- Article
- Export citation
-
Extreme value theory plays an important role in providing approximation results for the extremes of a sequence of independent random variables when their distribution is unknown. An important one is given by the generalised Pareto distribution
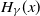 $H_\gamma(x)$ as an approximation of the distribution
$H_\gamma(x)$ as an approximation of the distribution 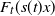 $F_t(s(t)x)$ of the excesses over a threshold t, where s(t) is a suitable norming function. We study the rate of convergence of
$F_t(s(t)x)$ of the excesses over a threshold t, where s(t) is a suitable norming function. We study the rate of convergence of 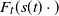 $F_t(s(t)\cdot)$ to
$F_t(s(t)\cdot)$ to 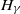 $H_\gamma$ in variational and Hellinger distances and translate it into that regarding the Kullback–Leibler divergence between the respective densities.
$H_\gamma$ in variational and Hellinger distances and translate it into that regarding the Kullback–Leibler divergence between the respective densities.
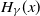
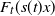
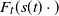
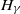
Determinants of measles persistence in Beijing, China: A modelling study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 22 August 2023, e144
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Branching processes in random environments with thresholds
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 22 August 2023, pp. 495-544
- Print publication:
- June 2024
-
- Article
- Export citation
-
Motivated by applications to COVID dynamics, we describe a model of a branching process in a random environment
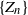 $\{Z_n\}$ whose characteristics change when crossing upper and lower thresholds. This introduces a cyclical path behavior involving periods of increase and decrease leading to supercritical and subcritical regimes. Even though the process is not Markov, we identify subsequences at random time points
$\{Z_n\}$ whose characteristics change when crossing upper and lower thresholds. This introduces a cyclical path behavior involving periods of increase and decrease leading to supercritical and subcritical regimes. Even though the process is not Markov, we identify subsequences at random time points 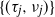 $\{(\tau_j, \nu_j)\}$—specifically the values of the process at crossing times, viz.
$\{(\tau_j, \nu_j)\}$—specifically the values of the process at crossing times, viz. 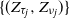 $\{(Z_{\tau_j}, Z_{\nu_j})\}$—along which the process retains the Markov structure. Under mild moment and regularity conditions, we establish that the subsequences possess a regenerative structure and prove that the limiting normal distributions of the growth rates of the process in supercritical and subcritical regimes decouple. For this reason, we establish limit theorems concerning the length of supercritical and subcritical regimes and the proportion of time the process spends in these regimes. As a byproduct of our analysis, we explicitly identify the limiting variances in terms of the functionals of the offspring distribution, threshold distribution, and environmental sequences.
$\{(Z_{\tau_j}, Z_{\nu_j})\}$—along which the process retains the Markov structure. Under mild moment and regularity conditions, we establish that the subsequences possess a regenerative structure and prove that the limiting normal distributions of the growth rates of the process in supercritical and subcritical regimes decouple. For this reason, we establish limit theorems concerning the length of supercritical and subcritical regimes and the proportion of time the process spends in these regimes. As a byproduct of our analysis, we explicitly identify the limiting variances in terms of the functionals of the offspring distribution, threshold distribution, and environmental sequences.
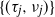
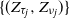
THE ESTIMATION RISK IN EXTREME SYSTEMIC RISK FORECASTS
-
- Journal:
- Econometric Theory / Volume 41 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 22 August 2023, pp. 341-390
-
- Article
-
- You have access
- Open access
- Export citation
Optimising rabies vaccination of dogs in India
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 22 August 2023, e164
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stable systems with power law conditions for Poisson hail
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 22 August 2023, pp. 315-353
- Print publication:
- March 2024
-
- Article
- Export citation
Normal and stable approximation to subgraph counts in superpositions of Bernoulli random graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 18 August 2023, pp. 401-419
- Print publication:
- June 2024
-
- Article
- Export citation
-
Real networks often exhibit clustering, the tendency to form relatively small groups of nodes with high edge densities. This clustering property can cause large numbers of small and dense subgraphs to emerge in otherwise sparse networks. Subgraph counts are an important and commonly used source of information about the network structure and function. We study probability distributions of subgraph counts in a community affiliation graph. This is a random graph generated as an overlay of m partly overlapping independent Bernoulli random graphs (layers)
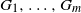 $G_1,\dots,G_m$ with variable sizes and densities. The model is parameterised by a joint distribution of layer sizes and densities. When m grows linearly in the number of nodes n, the model generates sparse random graphs with a rich statistical structure, admitting a nonvanishing clustering coefficient and a power-law limiting degree distribution. In this paper we establish the normal and
$G_1,\dots,G_m$ with variable sizes and densities. The model is parameterised by a joint distribution of layer sizes and densities. When m grows linearly in the number of nodes n, the model generates sparse random graphs with a rich statistical structure, admitting a nonvanishing clustering coefficient and a power-law limiting degree distribution. In this paper we establish the normal and  $\alpha$-stable approximations to the numbers of small cliques, cycles, and more general 2-connected subgraphs of a community affiliation graph.
$\alpha$-stable approximations to the numbers of small cliques, cycles, and more general 2-connected subgraphs of a community affiliation graph.

A systematic review of the evidence on the associations and safety of COVID-19 vaccination and post COVID-19 condition
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 18 August 2023, e145
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Migration–contagion processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 18 August 2023, pp. 71-105
- Print publication:
- March 2024
-
- Article
- Export citation
-
Consider the following migration process based on a closed network of N queues with
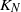 $K_N$ customers. Each station is a
$K_N$ customers. Each station is a  $\cdot$/M/
$\cdot$/M/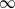 $\infty$ queue with service (or migration) rate
$\infty$ queue with service (or migration) rate 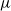 $\mu$. Upon departure, a customer is routed independently and uniformly at random to another station. In addition to migration, these customers are subject to a susceptible–infected–susceptible (SIS) dynamics. That is, customers are in one of two states: I for infected, or S for susceptible. Customers can swap their state either from I to S or from S to I only in stations. More precisely, at any station, each susceptible customer becomes infected with the instantaneous rate
$\mu$. Upon departure, a customer is routed independently and uniformly at random to another station. In addition to migration, these customers are subject to a susceptible–infected–susceptible (SIS) dynamics. That is, customers are in one of two states: I for infected, or S for susceptible. Customers can swap their state either from I to S or from S to I only in stations. More precisely, at any station, each susceptible customer becomes infected with the instantaneous rate 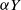 $\alpha Y$ if there are Y infected customers in the station, whereas each infected customer recovers and becomes susceptible with rate
$\alpha Y$ if there are Y infected customers in the station, whereas each infected customer recovers and becomes susceptible with rate 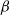 $\beta$. We let N tend to infinity and assume that
$\beta$. We let N tend to infinity and assume that 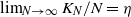 $\lim_{N\to \infty} K_N/N= \eta $, where
$\lim_{N\to \infty} K_N/N= \eta $, where 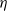 $\eta$ is a positive constant representing the customer density. The main problem of interest concerns the set of parameters of such a system for which there exists a stationary regime where the epidemic survives in the limiting system. The latter limit will be referred to as the thermodynamic limit. We use coupling and stochastic monotonicity arguments to establish key properties of the associated Markov processes, which in turn allow us to give the structure of the phase transition diagram of this thermodynamic limit with respect to
$\eta$ is a positive constant representing the customer density. The main problem of interest concerns the set of parameters of such a system for which there exists a stationary regime where the epidemic survives in the limiting system. The latter limit will be referred to as the thermodynamic limit. We use coupling and stochastic monotonicity arguments to establish key properties of the associated Markov processes, which in turn allow us to give the structure of the phase transition diagram of this thermodynamic limit with respect to 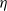 $\eta$. The analysis of the Kolmogorov equations of this SIS model reduces to that of a wave-type PDE for which we have found no explicit solution. This plain SIS model is one among several companion stochastic processes that exhibit both random migration and contagion. Two of them are discussed in the present paper as they provide variants to the plain SIS model as well as some bounds and approximations. These two variants are the departure-on-change-of-state (DOCS) model and the averaged-infection-rate (AIR) model, which both admit closed-form solutions. The AIR system is a classical mean-field model where the infection mechanism based on the actual population of infected customers is replaced by a mechanism based on some empirical average of the number of infected customers in all stations. The latter admits a product-form solution. DOCS features accelerated migration in that each change of SIS state implies an immediate departure. This model leads to another wave-type PDE that admits a closed-form solution. In this text, the main focus is on the closed stochastic networks and their limits. The open systems consisting of a single station with Poisson input are instrumental in the analysis of the thermodynamic limits and are also of independent interest. This class of SIS dynamics has incarnations in virtually all queueing networks of the literature.
$\eta$. The analysis of the Kolmogorov equations of this SIS model reduces to that of a wave-type PDE for which we have found no explicit solution. This plain SIS model is one among several companion stochastic processes that exhibit both random migration and contagion. Two of them are discussed in the present paper as they provide variants to the plain SIS model as well as some bounds and approximations. These two variants are the departure-on-change-of-state (DOCS) model and the averaged-infection-rate (AIR) model, which both admit closed-form solutions. The AIR system is a classical mean-field model where the infection mechanism based on the actual population of infected customers is replaced by a mechanism based on some empirical average of the number of infected customers in all stations. The latter admits a product-form solution. DOCS features accelerated migration in that each change of SIS state implies an immediate departure. This model leads to another wave-type PDE that admits a closed-form solution. In this text, the main focus is on the closed stochastic networks and their limits. The open systems consisting of a single station with Poisson input are instrumental in the analysis of the thermodynamic limits and are also of independent interest. This class of SIS dynamics has incarnations in virtually all queueing networks of the literature.
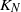

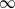
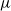
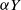
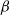
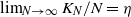
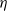
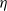
Modelling mass drug administration strategies for reducing scabies burden in Monrovia, Liberia
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 18 August 2023, e153
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Informing the Global Data Future: Benchmarking Data Governance Frameworks
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 18 August 2023, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Colorful path detection in vertex-colored temporal
-
- Journal:
- Network Science / Volume 11 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 18 August 2023, pp. 615-631
-
- Article
- Export citation
