Refine search
Actions for selected content:
53194 results in Statistics and Probability
Representativeness of whole-genome sequencing approaches in England: the importance for understanding inequalities associated with SARS-CoV-2 infection
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 20 September 2023, e169
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prevalence of anti-SARS-CoV-2 antibodies in people attending the two main Goma markets in the eastern Democratic Republic of the Congo
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 19 September 2023, e167
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Long-term health outcomes of Q-fever fatigue syndrome patients
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 19 September 2023, e179
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SPECIFICATION TESTS FOR TIME-VARYING COEFFICIENT PANEL DATA MODELS – ERRATUM
-
- Journal:
- Econometric Theory / Volume 41 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 19 September 2023, p. 171
-
- Article
- Export citation
ON GMM INFERENCE: PARTIAL IDENTIFICATION, IDENTIFICATION STRENGTH, AND NONSTANDARD ASYMPTOTICS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 18 September 2023, pp. 875-925
-
- Article
-
- You have access
- Open access
- Export citation
Do NBA teams avoid trading within their own division?
-
- Journal:
- Network Science / Volume 11 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 18 September 2023, pp. 657-669
-
- Article
- Export citation
Height function localisation on trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 18 September 2023, pp. 50-64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the combined imperfect repair process
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 18 September 2023, pp. 341-354
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Factors associated with urinary diversion and fatality of hospitalised acute pyelonephritis patients in France: a national cross-sectional study (FUrTIHF-2)
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 18 September 2023, e161
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fluctuations of the local times of the self-repelling random walk with directed edges
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 15 September 2023, pp. 545-586
- Print publication:
- June 2024
-
- Article
- Export citation
-
In 2008, Tóth and Vető defined the self-repelling random walk with directed edges as a non-Markovian random walk on
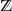 $\unicode{x2124}$: in this model, the probability that the walk moves from a point of
$\unicode{x2124}$: in this model, the probability that the walk moves from a point of 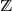 $\unicode{x2124}$ to a given neighbor depends on the number of previous crossings of the directed edge from the initial point to the target, called the local time of the edge. Tóth and Vető found that this model exhibited very peculiar behavior, as the process formed by the local times of all the edges, evaluated at a stopping time of a certain type and suitably renormalized, converges to a deterministic process, instead of a random one as in similar models. In this work, we study the fluctuations of the local times process around its deterministic limit, about which nothing was previously known. We prove that these fluctuations converge in the Skorokhod
$\unicode{x2124}$ to a given neighbor depends on the number of previous crossings of the directed edge from the initial point to the target, called the local time of the edge. Tóth and Vető found that this model exhibited very peculiar behavior, as the process formed by the local times of all the edges, evaluated at a stopping time of a certain type and suitably renormalized, converges to a deterministic process, instead of a random one as in similar models. In this work, we study the fluctuations of the local times process around its deterministic limit, about which nothing was previously known. We prove that these fluctuations converge in the Skorokhod 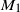 $M_1$ topology, as well as in the uniform topology away from the discontinuities of the limit, but not in the most classical Skorokhod topology. We also prove the convergence of the fluctuations of the aforementioned stopping times.
$M_1$ topology, as well as in the uniform topology away from the discontinuities of the limit, but not in the most classical Skorokhod topology. We also prove the convergence of the fluctuations of the aforementioned stopping times.
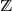
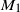
Epidemiology and molecular typing of multidrug-resistant bacteria in day care centres in Flanders, Belgium
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 15 September 2023, e156
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Clinical characteristics of 1279 patients with hepatitis E in Tianjin
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 September 2023, e157
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparison theorem and stability under perturbation of transition rate matrices for regime-switching processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 14 September 2023, pp. 540-557
- Print publication:
- June 2024
-
- Article
- Export citation
Immunogenicity and safety of COVID-19 vaccines among people living with HIV: A systematic review and meta-analysis
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 September 2023, e176
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Individual life insurance during epidemics
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 13 September 2023, pp. 152-175
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Introduction to Probability for Computing
-
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023
-
- Textbook
- Export citation
Atypical diarrhoeagenic Escherichia coli in milk related to a large foodborne outbreak
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 11 September 2023, e150
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Seroprevalence of SARS-CoV-2 antibodies in Republic of Congo, February 2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 11 September 2023, e162
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The correlation between humoral immune responses and severity of clinical symptoms in COVID-19 patients
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 11 September 2023, e158
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
VALID HETEROSKEDASTICITY ROBUST TESTING
-
- Journal:
- Econometric Theory / Volume 41 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 11 September 2023, pp. 249-301
-
- Article
-
- You have access
- Open access
- Export citation
