Refine search
Actions for selected content:
53194 results in Statistics and Probability
Reviews
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp ii-ii
-
- Chapter
- Export citation
Part IV - Computer Systems Modeling and Simulation
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 209-252
-
- Chapter
- Export citation
23 - Primality Testing
- from Part VII - Randomized Algorithms
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 403-418
-
- Chapter
- Export citation
-
Summary
One of the most important problems in the field of computer science is a math problem as well: How can we determine if an integer
is prime?
18 - Tail Bounds
- from Part VI - Tail Bounds and Applications
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 306-326
-
- Chapter
- Export citation
-
Summary
Until now, we have typically talked about the mean, variance, or higher moments of a random variable (r.v.). In this chapter, we will be concerned with the tail probability of a r.v.
22 - Monte Carlo Randomized Algorithms
- from Part VII - Randomized Algorithms
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 383-402
-
- Chapter
- Export citation
Part II - Discrete Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 43-132
-
- Chapter
- Export citation
6 - z-Transforms
- from Part II - Discrete Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 116-132
-
- Chapter
- Export citation
14 - Event-Driven Simulation
- from Part IV - Computer Systems Modeling and Simulation
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 240-252
-
- Chapter
- Export citation
Part I - Fundamentals and Probability on Events
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 1-42
-
- Chapter
- Export citation
7 - Continuous Random Variables: Single Distribution
- from Part III - Continuous Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 134-152
-
- Chapter
- Export citation
ECT volume 39 issue 5 Cover and Back matter
-
- Journal:
- Econometric Theory / Volume 39 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 28 September 2023, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Part V - Statistical Inference
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 253-304
-
- Chapter
- Export citation
25 - Ergodicity for Finite-State Discrete-Time Markov Chains
- from Part VIII - Discrete-Time Markov Chains
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 438-478
-
- Chapter
- Export citation
-
Summary
At this point in our discussion of discrete-time Markov chains (DTMCs) with
19 - Applications of Tail Bounds: Confidence Intervals and Balls and Bins
- from Part VI - Tail Bounds and Applications
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 327-345
-
- Chapter
- Export citation
1 - Before We Start … Some Mathematical Basics
- from Part I - Fundamentals and Probability on Events
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 2-20
-
- Chapter
- Export citation
16 - Classical Statistical Inference
- from Part V - Statistical Inference
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 265-284
-
- Chapter
- Export citation
5 - Variance, Higher Moments, and Random Sums
- from Part II - Discrete Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 83-115
-
- Chapter
- Export citation
The Excluded Tree Minor Theorem Revisited
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 27 September 2023, pp. 85-90
-
- Article
- Export citation
-
We prove that for every tree
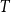 $T$ of radius
$T$ of radius 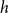 $h$, there is an integer
$h$, there is an integer  $c$ such that every
$c$ such that every 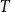 $T$-minor-free graph is contained in
$T$-minor-free graph is contained in 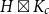 $H\boxtimes K_c$ for some graph
$H\boxtimes K_c$ for some graph 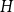 $H$ with pathwidth at most
$H$ with pathwidth at most 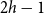 $2h-1$. This is a qualitative strengthening of the Excluded Tree Minor Theorem of Robertson and Seymour (GM I). We show that radius is the right parameter to consider in this setting, and
$2h-1$. This is a qualitative strengthening of the Excluded Tree Minor Theorem of Robertson and Seymour (GM I). We show that radius is the right parameter to consider in this setting, and 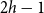 $2h-1$ is the best possible bound.
$2h-1$ is the best possible bound.
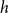

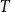
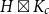
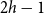
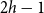
Nosocomial outbreak in a respiratory ward caused by the SARS-CoV-2 Omicron BA 5.2.1 subvariant associated with non-severe illness in vaccinated patients
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 26 September 2023, e171
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Factors associated with adverse pregnancy outcomes of maternal syphilis in Henan, China, 2016–2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 25 September 2023, e170
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
