Refine search
Actions for selected content:
53194 results in Statistics and Probability
3 - What Is a Social Network?
- from Part I - Thinking Structurally
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 45-66
-
- Chapter
- Export citation
4 - How Are Social Network Data Collected?
- from Part I - Thinking Structurally
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 67-87
-
- Chapter
- Export citation
Influenza hospitalisations in Spain between the last influenza and COVID-19 pandemic (2009–2019)
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 04 October 2023, e177
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association of SARS-CoV-2 viral load with abnormal laboratory characteristics and clinical outcomes in hospitalised COVID-19 patients
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 02 October 2023, e173
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Many Hamiltonian subsets in large graphs with given density
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 02 October 2023, pp. 110-120
-
- Article
- Export citation
-
A set of vertices in a graph is a Hamiltonian subset if it induces a subgraph containing a Hamiltonian cycle. Kim, Liu, Sharifzadeh, and Staden proved that for large
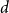 $d$, among all graphs with minimum degree
$d$, among all graphs with minimum degree 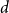 $d$,
$d$, 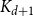 $K_{d+1}$ minimises the number of Hamiltonian subsets. We prove a near optimal lower bound that takes also the order and the structure of a graph into account. For many natural graph classes, it provides a much better bound than the extremal one (
$K_{d+1}$ minimises the number of Hamiltonian subsets. We prove a near optimal lower bound that takes also the order and the structure of a graph into account. For many natural graph classes, it provides a much better bound than the extremal one (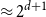 $\approx 2^{d+1}$). Among others, our bound implies that an
$\approx 2^{d+1}$). Among others, our bound implies that an  $n$-vertex
$n$-vertex 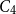 $C_4$-free graph with minimum degree
$C_4$-free graph with minimum degree 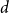 $d$ contains at least
$d$ contains at least 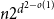 $n2^{d^{2-o(1)}}$ Hamiltonian subsets.
$n2^{d^{2-o(1)}}$ Hamiltonian subsets.
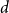
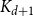
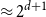

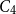
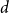
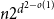
The impact of modeling decisions in statistical profiling
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 02 October 2023, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Intersecting families without unique shadow
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 02 October 2023, pp. 91-109
-
- Article
- Export citation
-
Let
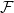 $\mathcal{F}$ be an intersecting family. A
$\mathcal{F}$ be an intersecting family. A 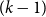 $(k-1)$-set
$(k-1)$-set 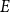 $E$ is called a unique shadow if it is contained in exactly one member of
$E$ is called a unique shadow if it is contained in exactly one member of 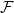 $\mathcal{F}$. Let
$\mathcal{F}$. Let 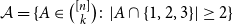 ${\mathcal{A}}=\{A\in \binom{[n]}{k}\colon |A\cap \{1,2,3\}|\geq 2\}$. In the present paper, we show that for
${\mathcal{A}}=\{A\in \binom{[n]}{k}\colon |A\cap \{1,2,3\}|\geq 2\}$. In the present paper, we show that for 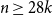 $n\geq 28k$,
$n\geq 28k$, 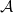 $\mathcal{A}$ is the unique family attaining the maximum size among all intersecting families without unique shadow. Several other results of a similar flavour are established as well.
$\mathcal{A}$ is the unique family attaining the maximum size among all intersecting families without unique shadow. Several other results of a similar flavour are established as well.
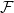
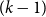
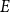
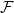
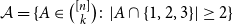
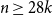
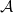
Genetic diversity of Plasmodium vivax in immigrant patients exhibiting severe and non-severe clinical manifestations in northern suburbs of Paris
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 02 October 2023, e127
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal stopping methodology for the secretary problem with random queries
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 02 October 2023, pp. 578-602
- Print publication:
- June 2024
-
- Article
- Export citation
Structured Replacement Policies for Offshore Wind Turbines
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 02 October 2023, pp. 355-386
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stochastic differential equation approximations of generative adversarial network training and its long-run behavior
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 02 October 2023, pp. 465-489
- Print publication:
- June 2024
-
- Article
- Export citation
3 - Common Discrete Random Variables
- from Part II - Discrete Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 44-57
-
- Chapter
- Export citation
15 - Estimators for Mean and Variance
- from Part V - Statistical Inference
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 255-264
-
- Chapter
- Export citation
-
Summary
The general setting in statistics is that we observe some data and then try to infer some property of the underlying distribution behind this data. The underlying distribution behind the data is unknown and represented by random variable (r.v.)
. This chapter will briefly introduce the general concept of estimators, focusing on estimators for the mean and variance.
References
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 539-543
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp iv-iv
-
- Chapter
- Export citation
12 - The Poisson Process
- from Part IV - Computer Systems Modeling and Simulation
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 210-228
-
- Chapter
- Export citation
24 - Discrete-Time Markov Chains: Finite-State
- from Part VIII - Discrete-Time Markov Chains
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 420-437
-
- Chapter
- Export citation
20 - Hashing Algorithms
- from Part VI - Tail Bounds and Applications
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 346-362
-
- Chapter
- Export citation
Part VII - Randomized Algorithms
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 363-418
-
- Chapter
- Export citation
8 - Continuous Random Variables: Joint Distributions
- from Part III - Continuous Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 153-169
-
- Chapter
- Export citation
