Refine search
Actions for selected content:
53194 results in Statistics and Probability
13 - Models for Networks
- from Part III - Making Structural Predictions
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 301-339
-
- Chapter
- Export citation
12 - Networks and Culture
- from Part II - Seeing Structure
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 269-298
-
- Chapter
- Export citation
Part II - Seeing Structure
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 115-298
-
- Chapter
- Export citation
8 - Cohesion and Groups
- from Part II - Seeing Structure
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 161-189
-
- Chapter
- Export citation
Part I - Thinking Structurally
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 17-114
-
- Chapter
- Export citation
11 - Affiliations and Dualities
- from Part II - Seeing Structure
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 246-268
-
- Chapter
- Export citation
15 - Models for Social Influence
- from Part III - Making Structural Predictions
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 364-389
-
- Chapter
- Export citation
5 - How Are Social Network Data Visualized?
- from Part I - Thinking Structurally
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 88-114
-
- Chapter
- Export citation
Considerations for actuaries when advising on commutation rates
-
- Journal:
- British Actuarial Journal / Volume 28 / 2023
- Published online by Cambridge University Press:
- 05 October 2023, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dependence among order statistics for time-transformed exponential models
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 05 October 2023, pp. 387-402
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
 $(X_{1},\ldots,X_{n})$ be a random vector distributed according to a time-transformed exponential model. This is a special class of exchangeable models, which, in particular, includes multivariate distributions with Schur-constant survival functions. Let for
$(X_{1},\ldots,X_{n})$ be a random vector distributed according to a time-transformed exponential model. This is a special class of exchangeable models, which, in particular, includes multivariate distributions with Schur-constant survival functions. Let for 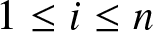 $1\leq i\leq n$,
$1\leq i\leq n$, 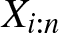 $X_{i:n}$ denote the corresponding ith-order statistic. We consider the problem of comparing the strength of dependence between any pair of Xi’s with that of the corresponding order statistics. It is in particular proved that for
$X_{i:n}$ denote the corresponding ith-order statistic. We consider the problem of comparing the strength of dependence between any pair of Xi’s with that of the corresponding order statistics. It is in particular proved that for 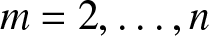 $m=2,\ldots,n$, the dependence of
$m=2,\ldots,n$, the dependence of 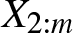 $X_{2:m}$ on
$X_{2:m}$ on 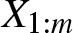 $X_{1:m}$ is more than that of X2 on X1 according to more stochastic increasingness (positive monotone regression) order, which in turn implies that
$X_{1:m}$ is more than that of X2 on X1 according to more stochastic increasingness (positive monotone regression) order, which in turn implies that 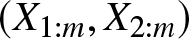 $(X_{1:m},X_{2:m})$ is more concordant than
$(X_{1:m},X_{2:m})$ is more concordant than 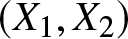 $(X_{1},X_{2})$. It will be interesting to examine whether these results can be extended to other exchangeable models.
$(X_{1},X_{2})$. It will be interesting to examine whether these results can be extended to other exchangeable models.

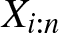
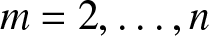
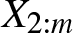
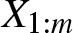
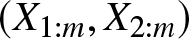
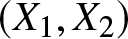
14 - Models for Network Diffusion
- from Part III - Making Structural Predictions
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 340-363
-
- Chapter
- Export citation
2 - What Is Social Structure?
- from Part I - Thinking Structurally
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 19-44
-
- Chapter
- Export citation
Figures
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp ix-xiv
-
- Chapter
- Export citation
16 - Conclusion
- from Part III - Making Structural Predictions
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 390-420
-
- Chapter
- Export citation
Contents
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp vii-viii
-
- Chapter
- Export citation
Preservation of mean inactivity time ordering for coherent systems
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 05 October 2023, pp. 666-692
- Print publication:
- June 2024
-
- Article
- Export citation
1 - Introduction
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 1-16
-
- Chapter
- Export citation
10 - Positions and Roles
- from Part II - Seeing Structure
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 216-245
-
- Chapter
- Export citation
9 - Hierarchy and Centrality
- from Part II - Seeing Structure
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 190-215
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp vi-vi
-
- Chapter
- Export citation
