Refine search
Actions for selected content:
53194 results in Statistics and Probability
Characteristics of the switch process and geometric divisibility
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 06 November 2023, pp. 802-809
- Print publication:
- September 2024
-
- Article
- Export citation
-
The switch process alternates independently between 1 and
 $-1$, with the first switch to 1 occurring at the origin. The expected value function of this process is defined uniquely by the distribution of switching times. The relation between the two is implicitly described through the Laplace transform, which is difficult to use for determining if a given function is the expected value function of some switch process. We derive an explicit relation under the assumption of monotonicity of the expected value function. It is shown that geometric divisible switching time distributions correspond to a non-negative decreasing expected value function. Moreover, an explicit relation between the expected value of a switch process and the autocovariance function of the switch process stationary counterpart is obtained, leading to a new interpretation of the classical Pólya criterion for positive-definiteness.
$-1$, with the first switch to 1 occurring at the origin. The expected value function of this process is defined uniquely by the distribution of switching times. The relation between the two is implicitly described through the Laplace transform, which is difficult to use for determining if a given function is the expected value function of some switch process. We derive an explicit relation under the assumption of monotonicity of the expected value function. It is shown that geometric divisible switching time distributions correspond to a non-negative decreasing expected value function. Moreover, an explicit relation between the expected value of a switch process and the autocovariance function of the switch process stationary counterpart is obtained, leading to a new interpretation of the classical Pólya criterion for positive-definiteness.

Graph-based methods for discrete choice
-
- Journal:
- Network Science / Volume 12 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 06 November 2023, pp. 21-40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Skin and soft tissue infection incidence before and during the COVID-19 pandemic
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 06 November 2023, e190
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SUBSAMPLING INFERENCE FOR NONPARAMETRIC EXTREMAL CONDITIONAL QUANTILES
-
- Journal:
- Econometric Theory / Volume 41 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 06 November 2023, pp. 326-340
-
- Article
-
- You have access
- Open access
- Export citation
On the choosability of
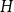 $H$-minor-free graphs
$H$-minor-free graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 03 November 2023, pp. 129-142
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a graph
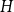 $H$, let us denote by
$H$, let us denote by 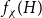 $f_\chi (H)$ and
$f_\chi (H)$ and 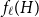 $f_\ell (H)$, respectively, the maximum chromatic number and the maximum list chromatic number of
$f_\ell (H)$, respectively, the maximum chromatic number and the maximum list chromatic number of 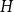 $H$-minor-free graphs. Hadwiger’s famous colouring conjecture from 1943 states that
$H$-minor-free graphs. Hadwiger’s famous colouring conjecture from 1943 states that 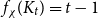 $f_\chi (K_t)=t-1$ for every
$f_\chi (K_t)=t-1$ for every 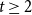 $t \ge 2$. A closely related problem that has received significant attention in the past concerns
$t \ge 2$. A closely related problem that has received significant attention in the past concerns 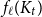 $f_\ell (K_t)$, for which it is known that
$f_\ell (K_t)$, for which it is known that 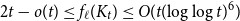 $2t-o(t) \le f_\ell (K_t) \le O(t (\!\log \log t)^6)$. Thus,
$2t-o(t) \le f_\ell (K_t) \le O(t (\!\log \log t)^6)$. Thus, 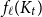 $f_\ell (K_t)$ is bounded away from the conjectured value
$f_\ell (K_t)$ is bounded away from the conjectured value 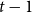 $t-1$ for
$t-1$ for 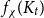 $f_\chi (K_t)$ by at least a constant factor. The so-called
$f_\chi (K_t)$ by at least a constant factor. The so-called 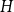 $H$-Hadwiger’s conjecture, proposed by Seymour, asks to prove that
$H$-Hadwiger’s conjecture, proposed by Seymour, asks to prove that 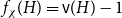 $f_\chi (H)={\textrm{v}}(H)-1$ for a given graph
$f_\chi (H)={\textrm{v}}(H)-1$ for a given graph 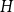 $H$ (which would be implied by Hadwiger’s conjecture).
$H$ (which would be implied by Hadwiger’s conjecture).In this paper, we prove several new lower bounds on
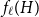 $f_\ell (H)$, thus exploring the limits of a list colouring extension of
$f_\ell (H)$, thus exploring the limits of a list colouring extension of 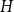 $H$-Hadwiger’s conjecture. Our main results are:
$H$-Hadwiger’s conjecture. Our main results are:For every
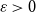 $\varepsilon \gt 0$ and all sufficiently large graphs
$\varepsilon \gt 0$ and all sufficiently large graphs 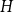 $H$ we have
$H$ we have 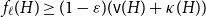 $f_\ell (H)\ge (1-\varepsilon )({\textrm{v}}(H)+\kappa (H))$, where
$f_\ell (H)\ge (1-\varepsilon )({\textrm{v}}(H)+\kappa (H))$, where 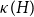 $\kappa (H)$ denotes the vertex-connectivity of
$\kappa (H)$ denotes the vertex-connectivity of 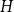 $H$.
$H$.For every
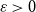 $\varepsilon \gt 0$ there exists
$\varepsilon \gt 0$ there exists 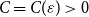 $C=C(\varepsilon )\gt 0$ such that asymptotically almost every
$C=C(\varepsilon )\gt 0$ such that asymptotically almost every  $n$-vertex graph
$n$-vertex graph 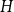 $H$ with
$H$ with 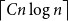 $\left \lceil C n\log n\right \rceil$ edges satisfies
$\left \lceil C n\log n\right \rceil$ edges satisfies 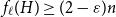 $f_\ell (H)\ge (2-\varepsilon )n$.
$f_\ell (H)\ge (2-\varepsilon )n$.
The first result generalizes recent results on complete and complete bipartite graphs and shows that the list chromatic number of
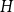 $H$-minor-free graphs is separated from the desired value of
$H$-minor-free graphs is separated from the desired value of 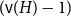 $({\textrm{v}}(H)-1)$ by a constant factor for all large graphs
$({\textrm{v}}(H)-1)$ by a constant factor for all large graphs 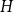 $H$ of linear connectivity. The second result tells us that for almost all graphs
$H$ of linear connectivity. The second result tells us that for almost all graphs 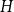 $H$ with superlogarithmic average degree
$H$ with superlogarithmic average degree 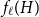 $f_\ell (H)$ is separated from
$f_\ell (H)$ is separated from 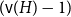 $({\textrm{v}}(H)-1)$ by a constant factor arbitrarily close to
$({\textrm{v}}(H)-1)$ by a constant factor arbitrarily close to 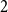 $2$. Conceptually these results indicate that the graphs
$2$. Conceptually these results indicate that the graphs 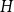 $H$ for which
$H$ for which 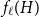 $f_\ell (H)$ is close to the conjectured value
$f_\ell (H)$ is close to the conjectured value 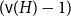 $({\textrm{v}}(H)-1)$ for
$({\textrm{v}}(H)-1)$ for 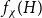 $f_\chi (H)$ are typically rather sparse.
$f_\chi (H)$ are typically rather sparse.
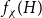
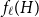
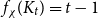
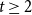
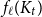
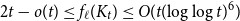
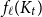
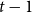
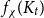
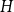
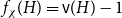
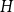
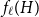
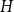
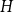
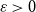
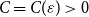

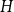
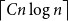
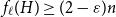
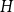
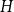
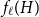
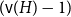
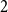
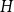
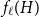
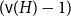
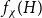
Parametrized polyconvex hyperelasticity with physics-augmented neural networks
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 03 November 2023, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Determinants of incomplete childhood hepatitis B vaccination in Sierra Leone, Liberia, and Guinea: Analysis of national surveys (2018–2020)
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 03 November 2023, e193
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Embedding data science innovations in organizations: a new workflow approach
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 03 November 2023, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Incomplete to complete multiphysics forecasting: a hybrid approach for learning unknown phenomena
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 03 November 2023, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Interaction Models
- Specification and Interpretation
-
- Published online:
- 02 November 2023
- Print publication:
- 16 November 2023
Tessellation-valued processes that are generated by cell division
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 01 November 2023, pp. 697-715
- Print publication:
- June 2024
-
- Article
- Export citation
-
Processes of random tessellations of the Euclidean space
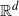 $\mathbb{R}^d$,
$\mathbb{R}^d$, 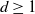 $d\geq 1$, are considered that are generated by subsequent division of their cells. Such processes are characterized by the laws of the life times of the cells until their division and by the laws for the random hyperplanes that divide the cells at the end of their life times. The STIT (STable with respect to ITerations) tessellation processes are a reference model. In the present paper a generalization concerning the life time distributions is introduced, a sufficient condition for the existence of such cell division tessellation processes is provided, and a construction is described. In particular, for the case that the random dividing hyperplanes have a Mondrian distribution—which means that all cells of the tessellations are cuboids—it is shown that the intrinsic volumes, except the Euler characteristic, can be used as the parameter for the exponential life time distribution of the cells.
$d\geq 1$, are considered that are generated by subsequent division of their cells. Such processes are characterized by the laws of the life times of the cells until their division and by the laws for the random hyperplanes that divide the cells at the end of their life times. The STIT (STable with respect to ITerations) tessellation processes are a reference model. In the present paper a generalization concerning the life time distributions is introduced, a sufficient condition for the existence of such cell division tessellation processes is provided, and a construction is described. In particular, for the case that the random dividing hyperplanes have a Mondrian distribution—which means that all cells of the tessellations are cuboids—it is shown that the intrinsic volumes, except the Euler characteristic, can be used as the parameter for the exponential life time distribution of the cells.
Risk of severe outcomes among Omicron sub-lineages BA.4.6, BA.2.75, and BQ.1 compared to BA.5 in England
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 31 October 2023, e189
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trajectory fitting estimation for reflected stochastic linear differential equations of a large signal
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 31 October 2023, pp. 741-754
- Print publication:
- September 2024
-
- Article
- Export citation
Capital requirement modeling for market and non-life premium risk in a dynamic insurance portfolio
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 31 October 2023, pp. 205-236
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A large-deviation principle for birth–death processes with a linear rate of downward jumps
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 31 October 2023, pp. 781-801
- Print publication:
- September 2024
-
- Article
- Export citation
COVID-19 epidemiology and rural healthcare: a survey in a Spanish village
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 27 October 2023, e188
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI-assisted modeling of capillary-driven droplet dynamics
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 27 October 2023, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cell-free plasma next-generation sequencing assists in the evaluation of secondary pneumonia in patients with COVID-19: a case series
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 27 October 2023, e185
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On sparsity, power-law, and clustering properties of graphex processes - ADDENDUM
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 27 October 2023, p. 1
-
- Article
- Export citation
On a time-changed variant of the generalized counting process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 27 October 2023, pp. 716-738
- Print publication:
- June 2024
-
- Article
- Export citation
