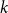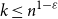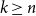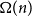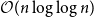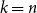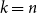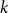Refine search
Actions for selected content:
53194 results in Statistics and Probability
Chapter 4 - Social Media Assessments around the Globe
- from Part II - Global Perspectives on Key Methods/Topics
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 131-156
-
- Chapter
- Export citation
Index
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 360-370
-
- Chapter
- Export citation
Introduction
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 1-8
-
- Chapter
- Export citation
Evaluation of global sensitivity analysis methods for computational structural mechanics problems
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 09 November 2023, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Copyright page
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp iv-iv
-
- Chapter
- Export citation
Part I - Foundations
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 9-128
-
- Chapter
- Export citation
Chapter 2 - Toward Improved Workplace Measurement with Passive Sensing Technologies
- from Part I - Foundations
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 46-106
-
- Chapter
- Export citation
Chapter 6 - Mobile Sensing around the Globe
- from Part II - Global Perspectives on Key Methods/Topics
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 176-210
-
- Chapter
- Export citation
Chapter 9 - A European Perspective on Psychometric Measurement Technology
- from Part III - Regional Focus
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 271-307
-
- Chapter
- Export citation
Contributors
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp vii-viii
-
- Chapter
- Export citation
Chapter 12 - Reflections on Testing, Assessment, and the Future
- from Part III - Regional Focus
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 349-359
-
- Chapter
- Export citation
Chapter 10 - Testing and Measurement in North America with a Focus on Transformation
- from Part III - Regional Focus
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 308-325
-
- Chapter
- Export citation
Chapter 1 - Machine Learning Algorithms and Measurement
- from Part I - Foundations
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 11-45
-
- Chapter
- Export citation
Chapter 8 - Technology-Enabled Measurement in Singapore
- from Part III - Regional Focus
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 239-270
-
- Chapter
- Export citation
Chapter 11 - Technology and Measurement Challenges in Education and the Labor Market in South America
- from Part III - Regional Focus
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 326-348
-
- Chapter
- Export citation
Chapter 7 - Technology and Measurement in Asia
- from Part III - Regional Focus
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 213-238
-
- Chapter
- Export citation
Part II - Global Perspectives on Key Methods/Topics
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 129-210
-
- Chapter
- Export citation

Technology and Measurement around the Globe
-
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023
On oriented cycles in randomly perturbed digraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 08 November 2023, pp. 157-178
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In 2003, Bohman, Frieze, and Martin initiated the study of randomly perturbed graphs and digraphs. For digraphs, they showed that for every
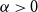 $\alpha \gt 0$, there exists a constant
$\alpha \gt 0$, there exists a constant 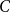 $C$ such that for every
$C$ such that for every  $n$-vertex digraph of minimum semi-degree at least
$n$-vertex digraph of minimum semi-degree at least 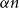 $\alpha n$, if one adds
$\alpha n$, if one adds 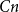 $Cn$ random edges then asymptotically almost surely the resulting digraph contains a consistently oriented Hamilton cycle. We generalize their result, showing that the hypothesis of this theorem actually asymptotically almost surely ensures the existence of every orientation of a cycle of every possible length, simultaneously. Moreover, we prove that we can relax the minimum semi-degree condition to a minimum total degree condition when considering orientations of a cycle that do not contain a large number of vertices of indegree
$Cn$ random edges then asymptotically almost surely the resulting digraph contains a consistently oriented Hamilton cycle. We generalize their result, showing that the hypothesis of this theorem actually asymptotically almost surely ensures the existence of every orientation of a cycle of every possible length, simultaneously. Moreover, we prove that we can relax the minimum semi-degree condition to a minimum total degree condition when considering orientations of a cycle that do not contain a large number of vertices of indegree 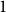 $1$. Our proofs make use of a variant of an absorbing method of Montgomery.
$1$. Our proofs make use of a variant of an absorbing method of Montgomery.
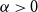
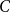

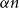
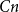
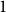
Mastermind with a linear number of queries
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 08 November 2023, pp. 143-156
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Since the 1960s Mastermind has been studied for the combinatorial and information-theoretical interest the game has to offer. Many results have been discovered starting with Erdős and Rényi determining the optimal number of queries needed for two colours. For
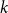 $k$ colours and
$k$ colours and  $n$ positions, Chvátal found asymptotically optimal bounds when
$n$ positions, Chvátal found asymptotically optimal bounds when 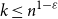 $k \le n^{1-\varepsilon }$. Following a sequence of gradual improvements for
$k \le n^{1-\varepsilon }$. Following a sequence of gradual improvements for 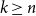 $k\geq n$ colours, the central open question is to resolve the gap between
$k\geq n$ colours, the central open question is to resolve the gap between 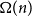 $\Omega (n)$ and
$\Omega (n)$ and 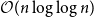 $\mathcal{O}(n\log \log n)$ for
$\mathcal{O}(n\log \log n)$ for 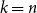 $k=n$. In this paper, we resolve this gap by presenting the first algorithm for solving
$k=n$. In this paper, we resolve this gap by presenting the first algorithm for solving 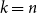 $k=n$ Mastermind with a linear number of queries. As a consequence, we are able to determine the query complexity of Mastermind for any parameters
$k=n$ Mastermind with a linear number of queries. As a consequence, we are able to determine the query complexity of Mastermind for any parameters 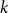 $k$ and
$k$ and  $n$.
$n$.