Refine search
Actions for selected content:
53194 results in Statistics and Probability
7 - When an Independent Variable Interacts with Itself
-
- Book:
- Interaction Models
- Published online:
- 02 November 2023
- Print publication:
- 16 November 2023, pp 273-312
-
- Chapter
- Export citation
Large cliques or cocliques in hypergraphs with forbidden order-size pairs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 16 November 2023, pp. 286-299
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The well-known Erdős-Hajnal conjecture states that for any graph
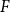 $F$, there exists
$F$, there exists 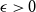 $\epsilon \gt 0$ such that every
$\epsilon \gt 0$ such that every  $n$-vertex graph
$n$-vertex graph 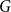 $G$ that contains no induced copy of
$G$ that contains no induced copy of 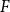 $F$ has a homogeneous set of size at least
$F$ has a homogeneous set of size at least 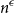 $n^{\epsilon }$. We consider a variant of the Erdős-Hajnal problem for hypergraphs where we forbid a family of hypergraphs described by their orders and sizes. For graphs, we observe that if we forbid induced subgraphs on
$n^{\epsilon }$. We consider a variant of the Erdős-Hajnal problem for hypergraphs where we forbid a family of hypergraphs described by their orders and sizes. For graphs, we observe that if we forbid induced subgraphs on 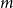 $m$ vertices and
$m$ vertices and 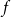 $f$ edges for any positive
$f$ edges for any positive 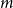 $m$ and
$m$ and 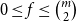 $0\leq f \leq \binom{m}{2}$, then we obtain large homogeneous sets. For triple systems, in the first nontrivial case
$0\leq f \leq \binom{m}{2}$, then we obtain large homogeneous sets. For triple systems, in the first nontrivial case 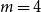 $m=4$, for every
$m=4$, for every 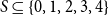 $S \subseteq \{0,1,2,3,4\}$, we give bounds on the minimum size of a homogeneous set in a triple system where the number of edges spanned by every four vertices is not in
$S \subseteq \{0,1,2,3,4\}$, we give bounds on the minimum size of a homogeneous set in a triple system where the number of edges spanned by every four vertices is not in 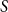 $S$. In most cases the bounds are essentially tight. We also determine, for all
$S$. In most cases the bounds are essentially tight. We also determine, for all 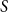 $S$, whether the growth rate is polynomial or polylogarithmic. Some open problems remain.
$S$, whether the growth rate is polynomial or polylogarithmic. Some open problems remain.
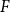
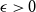

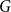
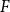
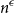
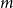
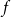
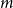
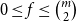
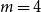
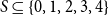
Part II - More Complex Forms of Conditionality
-
- Book:
- Interaction Models
- Published online:
- 02 November 2023
- Print publication:
- 16 November 2023, pp 193-194
-
- Chapter
- Export citation
Dedication
-
- Book:
- Interaction Models
- Published online:
- 02 November 2023
- Print publication:
- 16 November 2023, pp vii-viii
-
- Chapter
- Export citation
Injection drug use and sexually transmitted infections among men who have sex with men: A retrospective cohort study at an HIV/AIDS referral hospital in Tokyo, 2013–2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 15 November 2023, e195
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Seroprevalence of Zika in Brazil stratified by age and geographic distribution
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 15 November 2023, e197
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Congenital Zika is a devastating consequence of maternal Zika virus infections. Estimates of age-dependent seroprevalence profiles are central to our understanding of the force of Zika virus infections. We set out to calculate the age-dependent seroprevalence of Zika virus infections in Brazil. We analyzed serum samples stratified by age and geographic location, collected from 2016 to 2019, from about 16,000 volunteers enrolled in a Phase 3 dengue vaccine trial led by the Institute Butantan in Brazil. Our results show that Zika seroprevalence has a remarkable age-dependent and geographical distribution, with an average age of the first infection varying from region to region, ranging from 4.97 (3.03–5.41) to 7.24 (6.98–7.90) years. The calculated basic reproduction number,
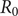 $ {R}_0 $, varied from region to region, ranging from 1.18 (1.04–1.41) to 2.33 (1.54–3.85). Such data are paramount to determine the optimal age to vaccinate against Zika, if and when such a vaccine becomes available.
$ {R}_0 $, varied from region to region, ranging from 1.18 (1.04–1.41) to 2.33 (1.54–3.85). Such data are paramount to determine the optimal age to vaccinate against Zika, if and when such a vaccine becomes available.
Spanning trees in graphs without large bipartite holes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 14 November 2023, pp. 270-285
-
- Article
-
- You have access
- HTML
- Export citation
-
We show that for any
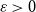 $\varepsilon \gt 0$ and
$\varepsilon \gt 0$ and 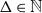 $\Delta \in \mathbb{N}$, there exists
$\Delta \in \mathbb{N}$, there exists 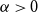 $\alpha \gt 0$ such that for sufficiently large
$\alpha \gt 0$ such that for sufficiently large  $n$, every
$n$, every  $n$-vertex graph
$n$-vertex graph 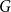 $G$ satisfying that
$G$ satisfying that 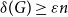 $\delta (G)\geq \varepsilon n$ and
$\delta (G)\geq \varepsilon n$ and 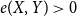 $e(X, Y)\gt 0$ for every pair of disjoint vertex sets
$e(X, Y)\gt 0$ for every pair of disjoint vertex sets 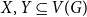 $X, Y\subseteq V(G)$ of size
$X, Y\subseteq V(G)$ of size 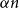 $\alpha n$ contains all spanning trees with maximum degree at most
$\alpha n$ contains all spanning trees with maximum degree at most 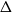 $\Delta$. This strengthens a result of Böttcher, Han, Kohayakawa, Montgomery, Parczyk, and Person.
$\Delta$. This strengthens a result of Böttcher, Han, Kohayakawa, Montgomery, Parczyk, and Person.
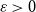
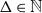
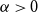


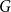
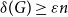
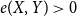
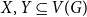
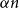
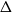
Approximate discrete entropy monotonicity for log-concave sums
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 13 November 2023, pp. 196-209
-
- Article
- Export citation
-
It is proven that a conjecture of Tao (2010) holds true for log-concave random variables on the integers: For every
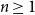 $n \geq 1$, if
$n \geq 1$, if 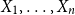 $X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas
$X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas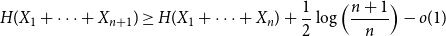 \begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}
\begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}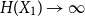 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 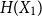 $H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if
$H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if 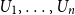 $U_1,\ldots,U_n$ are independent continuous uniforms on
$U_1,\ldots,U_n$ are independent continuous uniforms on 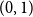 $(0,1)$, thenas
$(0,1)$, thenas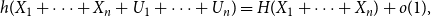 \begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}
\begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}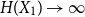 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 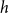 $h$ stands for the differential entropy. Explicit bounds for the
$h$ stands for the differential entropy. Explicit bounds for the 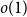 $o(1)$-terms are provided.
$o(1)$-terms are provided.
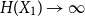
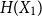
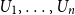
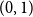
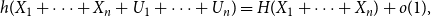
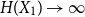
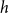
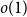
Evaluation of phase-adjusted interventions for COVID-19 using an improved SEIR model
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 13 November 2023, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Calibration of transition risk for corporate bonds
-
- Journal:
- British Actuarial Journal / Volume 28 / 2023
- Published online by Cambridge University Press:
- 13 November 2023, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prevalence and incidence of emergency department presentations and hospital separations with injecting-related infections in a longitudinal cohort of people who inject drugs
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 13 November 2023, e192
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association between face mask use and risk of SARS-CoV-2 infection: Cross-sectional study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 13 November 2023, e194
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PERFORMANCE OF EMPIRICAL RISK MINIMIZATION FOR LINEAR REGRESSION WITH DEPENDENT DATA
-
- Journal:
- Econometric Theory / Volume 41 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 10 November 2023, pp. 391-420
-
- Article
-
- You have access
- Open access
- Export citation
A special case of Vu’s conjecture: colouring nearly disjoint graphs of bounded maximum degree
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 10 November 2023, pp. 179-195
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A collection of graphs is nearly disjoint if every pair of them intersects in at most one vertex. We prove that if
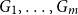 $G_1, \dots, G_m$ are nearly disjoint graphs of maximum degree at most
$G_1, \dots, G_m$ are nearly disjoint graphs of maximum degree at most 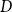 $D$, then the following holds. For every fixed
$D$, then the following holds. For every fixed 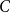 $C$, if each vertex
$C$, if each vertex 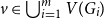 $v \in \bigcup _{i=1}^m V(G_i)$ is contained in at most
$v \in \bigcup _{i=1}^m V(G_i)$ is contained in at most 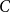 $C$ of the graphs
$C$ of the graphs 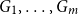 $G_1, \dots, G_m$, then the (list) chromatic number of
$G_1, \dots, G_m$, then the (list) chromatic number of 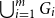 $\bigcup _{i=1}^m G_i$ is at most
$\bigcup _{i=1}^m G_i$ is at most 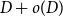 $D + o(D)$. This result confirms a special case of a conjecture of Vu and generalizes Kahn’s bound on the list chromatic index of linear uniform hypergraphs of bounded maximum degree. In fact, this result holds for the correspondence (or DP) chromatic number and thus implies a recent result of Molloy and Postle, and we derive this result from a more general list colouring result in the setting of ‘colour degrees’ that also implies a result of Reed and Sudakov.
$D + o(D)$. This result confirms a special case of a conjecture of Vu and generalizes Kahn’s bound on the list chromatic index of linear uniform hypergraphs of bounded maximum degree. In fact, this result holds for the correspondence (or DP) chromatic number and thus implies a recent result of Molloy and Postle, and we derive this result from a more general list colouring result in the setting of ‘colour degrees’ that also implies a result of Reed and Sudakov.
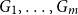
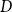
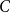
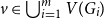
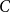
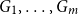
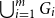
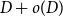

Statistics and Data Visualization in Climate Science with R and Python
-
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023

Applying Benford's Law for Assessing the Validity of Social Science Data
-
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023
Part III - Regional Focus
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 211-359
-
- Chapter
- Export citation
Chapter 3 - Information Privacy
- from Part I - Foundations
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 107-128
-
- Chapter
- Export citation
Contents
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp v-vi
-
- Chapter
- Export citation
Chapter 5 - Game-Based Assessment around the Globe
- from Part II - Global Perspectives on Key Methods/Topics
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 157-175
-
- Chapter
- Export citation
