Refine search
Actions for selected content:
53194 results in Statistics and Probability
Limited evidence for structural balance in the family
-
- Journal:
- Network Science / Volume 11 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 17 August 2023, pp. 589-614
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Range-based risk measures and their applications
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 15 August 2023, pp. 636-657
- Print publication:
- September 2023
-
- Article
- Export citation
Evaluating the effectiveness of whistleblower protection: A new index
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 15 August 2023, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Individual participant data sharing intentions and practices during the coronavirus disease-2019 pandemic: A rapid review
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 15 August 2023, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Animal sources of antimicrobial-resistant bacterial infections in humans: a systematic review
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 August 2023, e143
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Social mixing and network characteristics of COVID-19 patients before and after widespread interventions: A population-based study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 August 2023, e141
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
SARS-CoV-2 rapidly spreads among humans via social networks, with social mixing and network characteristics potentially facilitating transmission. However, limited data on topological structural features has hindered in-depth studies. Existing research is based on snapshot analyses, preventing temporal investigations of network changes. Comparing network characteristics over time offers additional insights into transmission dynamics. We examined confirmed COVID-19 patients from an eastern Chinese province, analyzing social mixing and network characteristics using transmission network topology before and after widespread interventions. Between the two time periods, the percentage of singleton networks increased from 38.9
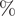 $ \% $ to 62.8
$ \% $ to 62.8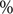 $ \% $
$ \% $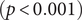 $ (p<0.001) $; the average shortest path length decreased from 1.53 to 1.14
$ (p<0.001) $; the average shortest path length decreased from 1.53 to 1.14 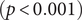 $ (p<0.001) $; the average betweenness reduced from 0.65 to 0.11
$ (p<0.001) $; the average betweenness reduced from 0.65 to 0.11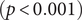 $ (p<0.001) $; the average cluster size dropped from 4.05 to 2.72
$ (p<0.001) $; the average cluster size dropped from 4.05 to 2.72 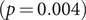 $ (p=0.004) $; and the out-degree had a slight but nonsignificant decline from 0.75 to 0.63
$ (p=0.004) $; and the out-degree had a slight but nonsignificant decline from 0.75 to 0.63 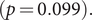 $ (p=0.099). $ Results show that nonpharmaceutical interventions effectively disrupted transmission networks, preventing further disease spread. Additionally, we found that the networks’ dynamic structure provided more information than solely examining infection curves after applying descriptive and agent-based modeling approaches. In summary, we investigated social mixing and network characteristics of COVID-19 patients during different pandemic stages, revealing transmission network heterogeneities.
$ (p=0.099). $ Results show that nonpharmaceutical interventions effectively disrupted transmission networks, preventing further disease spread. Additionally, we found that the networks’ dynamic structure provided more information than solely examining infection curves after applying descriptive and agent-based modeling approaches. In summary, we investigated social mixing and network characteristics of COVID-19 patients during different pandemic stages, revealing transmission network heterogeneities.
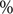
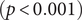
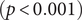
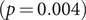
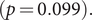
Reliability analyses of linear two-dimensional consecutive k-type systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 14 August 2023, pp. 439-464
- Print publication:
- June 2024
-
- Article
- Export citation
-
In this paper, several linear two-dimensional consecutive k-type systems are studied, which include the linear connected-(k, r)-out-of-
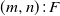 $(m,n)\colon\! F$ system and the linear l-connected-(k, r)-out-of-
$(m,n)\colon\! F$ system and the linear l-connected-(k, r)-out-of-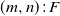 $(m,n)\colon\! F$ system without/with overlapping. Reliabilities of these systems are studied via the finite Markov chain imbedding approach (FMCIA) in a novel way. Some numerical examples are provided to illustrate the theoretical results established here and also to demonstrate the efficiency of the developed method. Finally, some possible applications and generalizations of the developed results are pointed out.
$(m,n)\colon\! F$ system without/with overlapping. Reliabilities of these systems are studied via the finite Markov chain imbedding approach (FMCIA) in a novel way. Some numerical examples are provided to illustrate the theoretical results established here and also to demonstrate the efficiency of the developed method. Finally, some possible applications and generalizations of the developed results are pointed out.
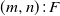
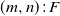
Estimation of vaccination coverage and associated factors in older Mexican adults
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 August 2023, e134
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quasipolynomial-time algorithms for Gibbs point processes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 11 August 2023, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We demonstrate a quasipolynomial-time deterministic approximation algorithm for the partition function of a Gibbs point process interacting via a stable potential. This result holds for all activities
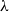 $\lambda$ for which the partition function satisfies a zero-free assumption in a neighbourhood of the interval
$\lambda$ for which the partition function satisfies a zero-free assumption in a neighbourhood of the interval 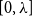 $[0,\lambda ]$. As a corollary, for all finiterange stable potentials, we obtain a quasipolynomial-time deterministic algorithm for all
$[0,\lambda ]$. As a corollary, for all finiterange stable potentials, we obtain a quasipolynomial-time deterministic algorithm for all 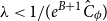 $\lambda \lt 1/(e^{B + 1} \hat C_\phi )$ where
$\lambda \lt 1/(e^{B + 1} \hat C_\phi )$ where 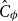 $\hat C_\phi$ is a temperedness parameter and
$\hat C_\phi$ is a temperedness parameter and 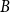 $B$ is the stability constant of
$B$ is the stability constant of 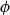 $\phi$. In the special case of a repulsive potential such as the hard-sphere gas we improve the range of activity by a factor of at least
$\phi$. In the special case of a repulsive potential such as the hard-sphere gas we improve the range of activity by a factor of at least 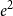 $e^2$ and obtain a quasipolynomial-time deterministic approximation algorithm for all
$e^2$ and obtain a quasipolynomial-time deterministic approximation algorithm for all 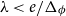 $\lambda \lt e/\Delta _\phi$, where
$\lambda \lt e/\Delta _\phi$, where 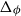 $\Delta _\phi$ is the potential-weighted connective constant of the potential
$\Delta _\phi$ is the potential-weighted connective constant of the potential 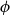 $\phi$. Our algorithm approximates coefficients of the cluster expansion of the partition function and uses the interpolation method of Barvinok to extend this approximation throughout the zero-free region.
$\phi$. Our algorithm approximates coefficients of the cluster expansion of the partition function and uses the interpolation method of Barvinok to extend this approximation throughout the zero-free region.
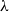
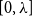
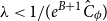
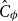
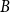
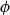
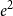
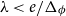
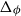
12 - Optimal Particle Filter
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 153-163
-
- Chapter
- Export citation
8 - The Kalman Filter and Smoother
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 112-124
-
- Chapter
- Export citation
Part II - Data Assimilation
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 99-100
-
- Chapter
- Export citation
Part III - Kalman Inversion
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 171-172
-
- Chapter
- Export citation
7 - Filtering and Smoothing Problems and Well-Posedness
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 101-111
-
- Chapter
- Export citation
2 - The Linear-Gaussian Setting
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 21-31
-
- Chapter
- Export citation
10 - The Extended and Ensemble Kalman Filters
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 133-143
-
- Chapter
- Export citation
Dedication
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp v-vi
-
- Chapter
- Export citation
3 - Optimization Perspective
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 32-48
-
- Chapter
- Export citation
5 - Monte Carlo Sampling and Importance Sampling
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 59-72
-
- Chapter
- Export citation
Exercises for Part I
-
- Book:
- Inverse Problems and Data Assimilation
- Published online:
- 27 July 2023
- Print publication:
- 10 August 2023, pp 91-98
-
- Chapter
- Export citation
