Refine search
Actions for selected content:
53194 results in Statistics and Probability
Characteristics associated with successful foodborne outbreak investigations involving United States retail food establishments (2014–2016)
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 20 March 2023, e78
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The duality of networks and groups: Models to generate two-mode networks from one-mode networks
-
- Journal:
- Network Science / Volume 11 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 20 March 2023, pp. 397-410
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A central limit theorem for conservative fragmentation chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 17 March 2023, pp. 1031-1068
- Print publication:
- September 2023
-
- Article
- Export citation
-
We are interested in a fragmentation process. We observe fragments frozen when their sizes are less than
 $\varepsilon$ (
$\varepsilon$ (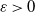 $\varepsilon>0$). It is known (Bertoin and Martínez, 2005) that the empirical measure of these fragments converges in law, under some renormalization. Hoffmann and Krell (2011) showed a bound for the rate of convergence. Here, we show a central limit theorem, under some assumptions. This gives us an exact rate of convergence.
$\varepsilon>0$). It is known (Bertoin and Martínez, 2005) that the empirical measure of these fragments converges in law, under some renormalization. Hoffmann and Krell (2011) showed a bound for the rate of convergence. Here, we show a central limit theorem, under some assumptions. This gives us an exact rate of convergence.

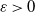
Experimental monitoring of nonlinear wave interactions in crab orchard sandstone under uniaxial load
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 16 March 2023, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SHARP TEST FOR EQUILIBRIUM UNIQUENESS IN DISCRETE GAMES WITH PRIVATE INFORMATION AND COMMON KNOWLEDGE UNOBSERVED HETEROGENEITY
-
- Journal:
- Econometric Theory / Volume 40 / Issue 6 / December 2024
- Published online by Cambridge University Press:
- 16 March 2023, pp. 1253-1310
-
- Article
-
- You have access
- Open access
- Export citation
FUNCTIONAL SEQUENTIAL TREATMENT ALLOCATION WITH COVARIATES
-
- Journal:
- Econometric Theory / Volume 40 / Issue 6 / December 2024
- Published online by Cambridge University Press:
- 16 March 2023, pp. 1211-1252
-
- Article
- Export citation
NEW CONTROL FUNCTION APPROACHES IN THRESHOLD REGRESSION WITH ENDOGENEITY
-
- Journal:
- Econometric Theory / Volume 40 / Issue 5 / October 2024
- Published online by Cambridge University Press:
- 16 March 2023, pp. 1065-1119
-
- Article
-
- You have access
- Open access
- Export citation
Hepatitis B burden and population immunity in a high endemicity city – a geographically random household epidemiology study for evaluating achievability of elimination – ERRATUM
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 16 March 2023, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
DiD IT?: a differences-in-differences investigation tool to quantify the impact of local incidents on public health using real-time syndromic surveillance health data
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 15 March 2023, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Value of contrast-enhanced ultrasound in the differential diagnosis of ureteral tuberculosis from ureteral malignant tumour in women
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 15 March 2023, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The 3-step hedge-based valuation: fair valuation in the presence of systematic risks
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 14 March 2023, pp. 418-442
- Print publication:
- May 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Geographical variation in hepatitis C-related severe liver disease and patient risk factors: a multicentre cross-sectional study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 March 2023, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Strong feller and ergodic properties of the (1+1)-affine process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 14 March 2023, pp. 812-834
- Print publication:
- September 2023
-
- Article
- Export citation
Pseudo-model-free hedging for variable annuities via deep reinforcement learning
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 3 / November 2023
- Published online by Cambridge University Press:
- 14 March 2023, pp. 503-546
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predictive modelling of Ross River virus using climate data in the Darling Downs
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 March 2023, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiological characteristics, spatial clusters and monthly incidence prediction of hand, foot and mouth disease from 2017 to 2022 in Shanxi Province, China
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 March 2023, e54
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Bruss–Robertson–Steele inequality
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 13 March 2023, pp. 1112-1114
- Print publication:
- September 2023
-
- Article
- Export citation
-
The Bruss–Robertson–Steele (BRS) inequality bounds the expected number of items of random size which can be packed into a given suitcase. Remarkably, no independence assumptions are needed on the random sizes, which points to a simple explanation; the inequality is the integrated form of an
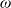 $\omega$-by-
$\omega$-by-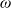 $\omega$ inequality, as this note proves.
$\omega$ inequality, as this note proves.
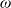
Risk allocation through shapley decompositions, with applications to variable annuities
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 13 March 2023, pp. 311-331
- Print publication:
- May 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Worst-case moments under partial ambiguity
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 13 March 2023, pp. 443-465
- Print publication:
- May 2023
-
- Article
- Export citation
Target benefit pension plan with longevity risk and intergenerational equity – CORRIGENDUM
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 13 March 2023, p. 488
- Print publication:
- May 2023
-
- Article
-
- You have access
- HTML
- Export citation
