Refine search
Actions for selected content:
53194 results in Statistics and Probability
9 - Relational Databases and Multiple Tables
- from Part III - Data in Databases
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 121-134
-
- Chapter
-
- You have access
- Open access
- Export citation
Contents
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp vii-xi
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 219-222
-
- Chapter
-
- You have access
- Open access
- Export citation
7 - Performance Monitoring for Supervisory Stress-Testing Models
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 124-155
-
- Chapter
- Export citation
Preface
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp xxi-xxii
-
- Chapter
- Export citation
12 - Text Data
- from Part IV - Special Types of Data
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 166-186
-
- Chapter
-
- You have access
- Open access
- Export citation
Part II - Data in Files
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 37-38
-
- Chapter
-
- You have access
- Open access
- Export citation
8 - Counterparty Credit Risk
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 156-174
-
- Chapter
- Export citation
References
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 312-326
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp xvii-xviii
-
- Chapter
- Export citation
Preface
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp xi-xiv
-
- Chapter
-
- You have access
- Open access
- Export citation
2 - Validating Bank Holding Companies’ Value-at-Risk Models for Market Risk
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 22-48
-
- Chapter
- Export citation
Index
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 445-470
-
- Chapter
- Export citation
1 - Introduction: Count Data Containing Dispersion
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 1-21
-
- Chapter
-
- You have access
- Export citation
11 - Case Studies in Wholesale Risk Model Validation
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 263-294
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp iv-iv
-
- Chapter
- Export citation
Moran models and Wright–Fisher diffusions with selection and mutation in a one-sided random environment
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 09 March 2023, pp. 701-767
- Print publication:
- September 2023
-
- Article
- Export citation
-
Consider a two-type Moran population of size N with selection and mutation, where the selective advantage of the fit individuals is amplified at extreme environmental conditions. Assume selection and mutation are weak with respect to N, and extreme environmental conditions rarely occur. We show that, as
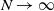 $N\to\infty$, the type frequency process with time sped up by N converges to the solution to a Wright–Fisher-type SDE with a jump term modeling the effect of the environment. We use an extension of the ancestral selection graph (ASG) to describe the genealogical picture of the model. Next, we show that the type frequency process and the line-counting process of a pruned version of the ASG satisfy a moment duality. This relation yields a characterization of the asymptotic type distribution. We characterize the ancestral type distribution using an alternative pruning of the ASG. Most of our results are stated in annealed and quenched form.
$N\to\infty$, the type frequency process with time sped up by N converges to the solution to a Wright–Fisher-type SDE with a jump term modeling the effect of the environment. We use an extension of the ancestral selection graph (ASG) to describe the genealogical picture of the model. Next, we show that the type frequency process and the line-counting process of a pruned version of the ASG satisfy a moment duality. This relation yields a characterization of the asymptotic type distribution. We characterize the ancestral type distribution using an alternative pruning of the ASG. Most of our results are stated in annealed and quenched form.
4 - Multivariate Forms of the COM–Poisson Distribution
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 124-152
-
- Chapter
- Export citation
7 - R and the tidyverse
- from Part II - Data in Files
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 87-100
-
- Chapter
-
- You have access
- Open access
- Export citation
13 - Network Data
- from Part IV - Special Types of Data
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 187-206
-
- Chapter
-
- You have access
- Open access
- Export citation
