Refine search
Actions for selected content:
53194 results in Statistics and Probability
Early detection of local SARS-CoV-2 outbreaks by wastewater surveillance: a feasibility study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 01 February 2023, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Seroprevalence of COVID-19 infection in a densely populated district in the eastern Democratic Republic of Congo
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 01 February 2023, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On impact of largest claims reinsurance treaties on the ceding company’s loss reserve
- Part of
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 2 / July 2023
- Published online by Cambridge University Press:
- 01 February 2023, pp. 328-357
-
- Article
- Export citation
Reciprocal properties of random fields on undirected graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 31 January 2023, pp. 781-796
- Print publication:
- September 2023
-
- Article
- Export citation
-
We clarify and refine the definition of a reciprocal random field on an undirected graph, with the reciprocal chain as a special case, by introducing four new properties: the factorizing, global, local, and pairwise reciprocal properties, in decreasing order of strength, with respect to a set of nodes
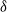 $\delta$. They reduce to the better-known Markov properties if
$\delta$. They reduce to the better-known Markov properties if 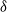 $\delta$ is the empty set, or, with the exception of the local property, if
$\delta$ is the empty set, or, with the exception of the local property, if 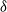 $\delta$ is a complete set. Conditions for each reciprocal property to imply the next stronger property are derived, and it is shown that, conditionally on the values at a set of nodes
$\delta$ is a complete set. Conditions for each reciprocal property to imply the next stronger property are derived, and it is shown that, conditionally on the values at a set of nodes 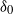 $\delta_0$, all four properties are preserved for the subgraph induced by the remaining nodes, with respect to the node set
$\delta_0$, all four properties are preserved for the subgraph induced by the remaining nodes, with respect to the node set 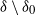 $\delta\setminus\delta_0$. We note that many of the above results are new even for reciprocal chains.
$\delta\setminus\delta_0$. We note that many of the above results are new even for reciprocal chains.
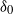
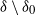
HIV care continuum outcomes among recently diagnosed people with HIV (PWH) in Washington, DC
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 30 January 2023, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiple-drawing dynamic Friedman urns with opposite-reinforcement
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 26 January 2023, pp. 115-129
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Invasive pneumococcal surveillance to assess the potential benefits of extended spectrum conjugate vaccines (PCV15/PCV20) in older adults
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 26 January 2023, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mean flow reconstruction of unsteady flows using physics-informed neural networks
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 25 January 2023, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A simplest mathematics of turn-taking: Conversational deep structure, emergence, and permeation
-
- Journal:
- Network Science / Volume 11 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 25 January 2023, pp. 224-248
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Effects of haptic imagery on purchase intention
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 25 January 2023, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Preferential attachment hypergraph with high modularity
-
- Journal:
- Network Science / Volume 10 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 23 January 2023, pp. 400-429
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NWS volume 10 issue 4 Cover and Front matter
-
- Journal:
- Network Science / Volume 10 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 23 January 2023, pp. f1-f3
-
- Article
-
- You have access
- Export citation
Expanding the boundaries of interdisciplinary field: Contribution of Network Science journal to the development of network science
-
- Journal:
- Network Science / Volume 11 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 20 January 2023, pp. 65-97
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal control of supervisors balancing individual and joint responsibilities
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 20 January 2023, pp. 130-149
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quality issues in co-authorship data of a national scientific community
-
- Journal:
- Network Science / Volume 11 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 20 January 2023, pp. 98-112
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sturm–Liouville theory and decay parameter for quadratic markov branching processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 19 January 2023, pp. 737-764
- Print publication:
- September 2023
-
- Article
- Export citation
Trichinella infection in Serbia from 2011 to 2020: a success story in the field of One Health
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 19 January 2023, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A large A(H3N2) influenza outbreak with a high attack rate in a drug user community in Italy, April 2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 19 January 2023, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PES volume 37 issue 1 Cover
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 18 January 2023, p. f1
-
- Article
-
- You have access
- Export citation
Relationships between cumulative entropy/extropy, Gini mean difference and probability weighted moments
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 18 January 2023, pp. 28-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
