Refine search
Actions for selected content:
52669 results in Statistics and Probability
COVID-19 in the WHO African region: using risk assessment to inform decisions on public health and social measures
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 10 May 2021, e259
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Foundations of Constructive Probability Theory
-
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021
Effect of selective removal of badgers (Meles meles) on ranging behaviour during a ‘Test and Vaccinate or Remove’ intervention in Northern Ireland
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 07 May 2021, e125
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Communicability of varicella before rash onset: a literature review
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 07 May 2021, e131
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The study of variability in engineering design—An appreciation and a retrospective
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 07 May 2021, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A cluster of Shiga Toxin-producing Escherichia coli O157:H7 highlights raw pet food as an emerging potential source of infection in humans
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 06 May 2021, e124
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
IFRS 17 contractual service: a life insurance perspective
-
- Journal:
- British Actuarial Journal / Volume 26 / 2021
- Published online by Cambridge University Press:
- 04 May 2021, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A fused mixed-methods approach to thematic analysis of personal networks: Two case studies of caregiver support networks
-
- Journal:
- Network Science / Volume 9 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 04 May 2021, pp. 236-253
-
- Article
-
- You have access
- Open access
- Export citation
ASB volume 51 issue 2 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 18 May 2021, pp. f1-f2
- Print publication:
- May 2021
-
- Article
-
- You have access
- Export citation
ASB volume 51 issue 2 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 18 May 2021, pp. b1-b2
- Print publication:
- May 2021
-
- Article
-
- You have access
- Export citation
Simulation-based evaluation of school reopening strategies during COVID-19: A case study of São Paulo, Brazil
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 30 April 2021, e118
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Counting matchings via capacity-preserving operators
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 30 April 2021, pp. 956-981
-
- Article
-
- You have access
- Open access
- Export citation
SIGNATURES OF MULTI-STATE SYSTEMS BASED ON A SERIES/PARALLEL/RECURRENT STRUCTURE OF MODULES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 30 April 2021, pp. 824-850
-
- Article
- Export citation
Attach importance of the bootstrap t test against Student's t test in clinical epidemiology: a demonstrative comparison using COVID-19 as an example
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 30 April 2021, e107
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SARS-CoV-2 mutations: the biological trackway towards viral fitness
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 30 April 2021, e110
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NEGATIVE POWERS OF INTEGRATED PROCESSES
-
- Journal:
- Econometric Theory / Volume 38 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 30 April 2021, pp. 339-369
-
- Article
-
- You have access
- Open access
- Export citation
-
This paper derives the limit distribution of the rescaled sum of the absolute value of an integrated process with continuously distributed innovations raised to a negative power less than
 $-$1, and of the analogous statistic that is obtained using the same function of an integrated process but only considering positive values of the integrated process. We show that the limit behavior of this statistic is determined by the values of the integrated process that are closest to 0, and find the limit behavior of the values of the integrated process that are closest to 0.
$-$1, and of the analogous statistic that is obtained using the same function of an integrated process but only considering positive values of the integrated process. We show that the limit behavior of this statistic is determined by the values of the integrated process that are closest to 0, and find the limit behavior of the values of the integrated process that are closest to 0.

Additive bases via Fourier analysis
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 29 April 2021, pp. 930-941
-
- Article
- Export citation
-
Extending a result by Alon, Linial, and Meshulam to abelian groups, we prove that if G is a finite abelian group of exponent m and S is a sequence of elements of G such that any subsequence of S consisting of at least
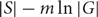 $$|S| - m\ln |G|$$ elements generates G, then S is an additive basis of G . We also prove that the additive span of any l generating sets of G contains a coset of a subgroup of size at least
$$|S| - m\ln |G|$$ elements generates G, then S is an additive basis of G . We also prove that the additive span of any l generating sets of G contains a coset of a subgroup of size at least 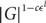 $$|G{|^{1 - c{ \in ^l}}}$$ for certain c=c(m) and
$$|G{|^{1 - c{ \in ^l}}}$$ for certain c=c(m) and 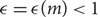 $$ \in=\in (m) < 1$$; we use the probabilistic method to give sharper values of c(m) and
$$ \in=\in (m) < 1$$; we use the probabilistic method to give sharper values of c(m) and 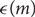 $$ \in (m)$$ in the case when G is a vector space; and we give new proofs of related known results.
$$ \in (m)$$ in the case when G is a vector space; and we give new proofs of related known results.
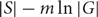
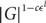
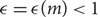
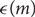
Use of the Hayami diffusive wave equation to model the relationship infected–recoveries–deaths of Covid-19 pandemic
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 29 April 2021, e138
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Atypical presentation of Neisseria meningitidis serogroup W disease is associated with the introduction of the 2013 strain
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 29 April 2021, e126
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ASYMPTOTICS FOR SYSTEMIC RISK WITH DEPENDENT HEAVY-TAILED LOSSES
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 29 April 2021, pp. 571-605
- Print publication:
- May 2021
-
- Article
- Export citation
