Refine search
Actions for selected content:
52669 results in Statistics and Probability
3 - Programming statistical graphics
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 53-92
-
- Chapter
- Export citation
Stochastic comparison of parallel systems with Pareto components
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 20 May 2021, pp. 950-962
-
- Article
- Export citation
-
Pareto distribution is an important distribution in extreme value theory. In this paper, we consider parallel systems with Pareto components and study the effect of heterogeneity on skewness of such systems. It is shown that, when the lifetimes of components have different shape parameters, the parallel system with heterogeneous Pareto component lifetimes is more skewed than the system with independent and identically distributed Pareto components. However, for the case when the lifetimes of components have different scale parameters, the result gets reversed in the sense of star ordering. We also establish the relation between star ordering and dispersive ordering by extending the result of Deshpande and Kochar [(1983). Dispersive ordering is the same as tail ordering. Advances in Applied Probability 15(3): 686–687] from support
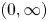 $(0, \infty )$ to general supports
$(0, \infty )$ to general supports 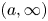 $(a, \infty )$,
$(a, \infty )$, 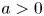 $a > 0$. As a consequence, we obtain some new results on dispersion of order statistics from heterogeneous Pareto samples with respect to dispersive ordering.
$a > 0$. As a consequence, we obtain some new results on dispersion of order statistics from heterogeneous Pareto samples with respect to dispersive ordering.
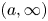
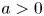
6 - Simulation
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 150-196
-
- Chapter
- Export citation
COVID-19 vaccine hesitancy among medical students in India
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 20 May 2021, e132
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Complex programming in the tidyverse
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 139-149
-
- Chapter
- Export citation
Preface to the first edition
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp xix-xx
-
- Chapter
- Export citation
4 - Programming with R
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 93-138
-
- Chapter
- Export citation
Copyright page
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp iv-iv
-
- Chapter
- Export citation
Preface to the third edition
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp xv-xvi
-
- Chapter
- Export citation
Index
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 257-260
-
- Chapter
- Export citation
Expanded contents
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp ix-xiv
-
- Chapter
- Export citation
2 - Introduction to the R language
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 7-52
-
- Chapter
- Export citation
Preface to the second edition
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp xvii-xviii
-
- Chapter
- Export citation
Contents
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp v-viii
-
- Chapter
- Export citation
Appendix B - Base graphics details
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 251-256
-
- Chapter
- Export citation
Appendices
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 248-256
-
- Chapter
- Export citation
1 - Getting started
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 1-6
-
- Chapter
- Export citation
7 - Computational linear algebra
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 197-221
-
- Chapter
- Export citation
8 - Numerical optimization
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 222-247
-
- Chapter
- Export citation
Appendix A - Review of random variables and distributions
-
- Book:
- A First Course in Statistical Programming with R
- Published online:
- 08 November 2021
- Print publication:
- 20 May 2021, pp 248-250
-
- Chapter
- Export citation
