Refine search
Actions for selected content:
52669 results in Statistics and Probability
Turán-type results for intersection graphs of boxes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 19 May 2021, pp. 982-987
-
- Article
-
- You have access
- Open access
- Export citation
-
In this short note, we prove the following analog of the Kővári–Sós–Turán theorem for intersection graphs of boxes. If G is the intersection graph of n axis-parallel boxes in
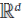 $${{\mathbb{R}}^d}$$ such that G contains no copy of Kt,t, then G has at most ctn( log n)2d+3 edges, where c = c(d)>0 only depends on d. Our proof is based on exploring connections between boxicity, separation dimension and poset dimension. Using this approach, we also show that a construction of Basit, Chernikov, Starchenko, Tao and Tran of K2,2-free incidence graphs of points and rectangles in the plane can be used to disprove a conjecture of Alon, Basavaraju, Chandran, Mathew and Rajendraprasad. We show that there exist graphs of separation dimension 4 having superlinear number of edges.
$${{\mathbb{R}}^d}$$ such that G contains no copy of Kt,t, then G has at most ctn( log n)2d+3 edges, where c = c(d)>0 only depends on d. Our proof is based on exploring connections between boxicity, separation dimension and poset dimension. Using this approach, we also show that a construction of Basit, Chernikov, Starchenko, Tao and Tran of K2,2-free incidence graphs of points and rectangles in the plane can be used to disprove a conjecture of Alon, Basavaraju, Chandran, Mathew and Rajendraprasad. We show that there exist graphs of separation dimension 4 having superlinear number of edges.
Risk factors associated with the incidence of self-reported COVID-19-like illness: data from a web-based syndromic surveillance system in the Netherlands
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 19 May 2021, e129
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Distribution of molecular strains of Mycobacterium tuberculosis in an intermediate burden Asia Pacific city
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 19 May 2021, e134
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Seroprevalence of SARS-CoV-2 antibodies in the poorest region of Brazil: results from a population-based study
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 18 May 2021, e130
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reimagining data responsibility: 10 new approaches toward a culture of trust in re-using data to address critical public needs
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 18 May 2021, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ON THE
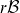 $r\mathcal{B}$ELL FAMILY OF DISTRIBUTIONS WITH ACTUARIAL APPLICATIONS
$r\mathcal{B}$ELL FAMILY OF DISTRIBUTIONS WITH ACTUARIAL APPLICATIONS
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 18 May 2021, pp. 185-210
- Print publication:
- January 2022
-
- Article
- Export citation
-
In this paper, a new three-parameter discrete family of distributions, the
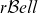 $r{\mathcal B}ell$ family, is introduced. The family is based on series expansion of the r-Bell polynomials. The proposed model generalises the classical Poisson and the recently proposed Bell and Bell–Touchard distributions. It exhibits interesting stochastic properties. Its probabilities can be computed by a recursive formula that allows us to calculate the probability function of the amount of aggregate claims in the collective risk model in terms of an integral equation. Univariate and bivariate regression models are presented. The former regression model is used to explain the number of out-of-use claims in an automobile insurance portfolio, by showing a good out-of-sample performance. The latter is used to describe the number of out-of-use and parking claims jointly. This family provides an alternative to other traditionally used distributions to describe count data such as the negative binomial and Poisson-inverse Gaussian models.
$r{\mathcal B}ell$ family, is introduced. The family is based on series expansion of the r-Bell polynomials. The proposed model generalises the classical Poisson and the recently proposed Bell and Bell–Touchard distributions. It exhibits interesting stochastic properties. Its probabilities can be computed by a recursive formula that allows us to calculate the probability function of the amount of aggregate claims in the collective risk model in terms of an integral equation. Univariate and bivariate regression models are presented. The former regression model is used to explain the number of out-of-use claims in an automobile insurance portfolio, by showing a good out-of-sample performance. The latter is used to describe the number of out-of-use and parking claims jointly. This family provides an alternative to other traditionally used distributions to describe count data such as the negative binomial and Poisson-inverse Gaussian models.
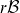
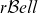
The value of data matching for public poverty initiatives: a local voucher program example
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 18 May 2021, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The genomic distribution map of human papillomavirus in Western China
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 18 May 2021, e135
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Robust coordination in adversarial social networks: From human behavior to agent-based modeling
-
- Journal:
- Network Science / Volume 9 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 17 May 2021, pp. 255-290
-
- Article
-
- You have access
- Open access
- Export citation
Multi-output Gaussian processes for multi-population longevity modelling
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 2 / July 2021
- Published online by Cambridge University Press:
- 17 May 2021, pp. 318-345
-
- Article
- Export citation
Review of infective dose, routes of transmission and outcome of COVID-19 caused by the SARS-COV-2: comparison with other respiratory viruses– CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 14 May 2021, e116
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiological assessment of 5598 brucellosis inpatients in Spain (1997–2015)
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 14 May 2021, e149
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Implementing epidemic intelligence in the WHO African region for early detection and response to acute public health events
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 14 May 2021, e261
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association of smoking and cardiovascular disease with disease progression in COVID-19: a systematic review and meta-analysis
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 12 May 2021, e143
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Scenario Weights for Importance Measurement (SWIM) – an R package for sensitivity analysis
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 2 / July 2021
- Published online by Cambridge University Press:
- 12 May 2021, pp. 458-483
-
- Article
- Export citation
NEIGHBOURING PREDICTION FOR MORTALITY
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 12 May 2021, pp. 689-718
- Print publication:
- September 2021
-
- Article
- Export citation
High but slightly declining COVID-19 vaccine acceptance and reasons for vaccine acceptance, Finland April to December 2020
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 11 May 2021, e123
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On inactivity times of failed components of coherent system under double monitoring
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 11 May 2021, pp. 923-940
-
- Article
- Export citation
Depths in hooking networks
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 11 May 2021, pp. 941-949
-
- Article
- Export citation
Statistical features of persistence and long memory in mortality data
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 2 / July 2021
- Published online by Cambridge University Press:
- 11 May 2021, pp. 291-317
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
