Refine search
Actions for selected content:
52669 results in Statistics and Probability
From microscopic price dynamics to multidimensional rough volatility models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 July 2021, pp. 425-462
- Print publication:
- June 2021
-
- Article
- Export citation
Bounds for expected supremum of fractional Brownian motion with drift
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 411-427
- Print publication:
- June 2021
-
- Article
- Export citation
-
We provide upper and lower bounds for the mean
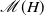 $\mathscr{M}(H)$ of
$\mathscr{M}(H)$ of 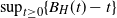 $\sup_{t\geq 0} \{B_H(t) - t\}$, with
$\sup_{t\geq 0} \{B_H(t) - t\}$, with 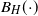 $B_H(\!\cdot\!)$ a zero-mean, variance-normalized version of fractional Brownian motion with Hurst parameter
$B_H(\!\cdot\!)$ a zero-mean, variance-normalized version of fractional Brownian motion with Hurst parameter 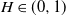 $H\in(0,1)$. We find bounds in (semi-) closed form, distinguishing between
$H\in(0,1)$. We find bounds in (semi-) closed form, distinguishing between 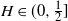 $H\in(0,\frac{1}{2}]$ and
$H\in(0,\frac{1}{2}]$ and 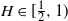 $H\in[\frac{1}{2},1)$, where in the former regime a numerical procedure is presented that drastically reduces the upper bound. For
$H\in[\frac{1}{2},1)$, where in the former regime a numerical procedure is presented that drastically reduces the upper bound. For 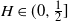 $H\in(0,\frac{1}{2}]$, the ratio between the upper and lower bound is bounded, whereas for
$H\in(0,\frac{1}{2}]$, the ratio between the upper and lower bound is bounded, whereas for 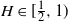 $H\in[\frac{1}{2},1)$ the derived upper and lower bound have a strongly similar shape. We also derive a new upper bound for the mean of
$H\in[\frac{1}{2},1)$ the derived upper and lower bound have a strongly similar shape. We also derive a new upper bound for the mean of 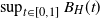 $\sup_{t\in[0,1]} B_H(t)$,
$\sup_{t\in[0,1]} B_H(t)$, 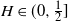 $H\in(0,\frac{1}{2}]$, which is tight around
$H\in(0,\frac{1}{2}]$, which is tight around 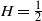 $H=\frac{1}{2}$.
$H=\frac{1}{2}$.
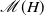
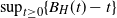
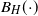
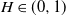
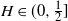
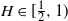
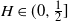
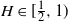
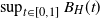
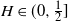
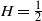
JPR volume 58 issue 2 Cover and Back matter
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. b1-b2
- Print publication:
- June 2021
-
- Article
-
- You have access
- Export citation
Data-driven sparse reconstruction of flow over a stalled aerofoil using experimental data
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 31 May 2021, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Recent work has demonstrated the use of sparse sensors in combination with the proper orthogonal decomposition (POD) to produce data-driven reconstructions of the full velocity fields in a variety of flows. The present work investigates the fidelity of such techniques applied to a stalled NACA 0012 aerofoil at
 $ {Re}_c=75,000 $ at an angle of attack
$ {Re}_c=75,000 $ at an angle of attack 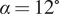 $ \alpha ={12}^{\circ } $ as measured experimentally using planar time-resolved particle image velocimetry. In contrast to many previous studies, the flow is absent of any dominant shedding frequency and exhibits a broad range of singular values due to the turbulence in the separated region. Several reconstruction methodologies for linear state estimation based on classical compressed sensing and extended POD methodologies are presented as well as nonlinear refinement through the use of a shallow neural network (SNN). It is found that the linear reconstructions inspired by the extended POD are inferior to the compressed sensing approach provided that the sparse sensors avoid regions of the flow with small variance across the global POD basis. Regardless of the linear method used, the nonlinear SNN gives strikingly similar performance in its refinement of the reconstructions. The capability of sparse sensors to reconstruct separated turbulent flow measurements is further discussed and directions for future work suggested.
$ \alpha ={12}^{\circ } $ as measured experimentally using planar time-resolved particle image velocimetry. In contrast to many previous studies, the flow is absent of any dominant shedding frequency and exhibits a broad range of singular values due to the turbulence in the separated region. Several reconstruction methodologies for linear state estimation based on classical compressed sensing and extended POD methodologies are presented as well as nonlinear refinement through the use of a shallow neural network (SNN). It is found that the linear reconstructions inspired by the extended POD are inferior to the compressed sensing approach provided that the sparse sensors avoid regions of the flow with small variance across the global POD basis. Regardless of the linear method used, the nonlinear SNN gives strikingly similar performance in its refinement of the reconstructions. The capability of sparse sensors to reconstruct separated turbulent flow measurements is further discussed and directions for future work suggested.

The power of two choices for random walks
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 28 May 2021, pp. 73-100
-
- Article
-
- You have access
- Open access
- Export citation
-
We apply the power-of-two-choices paradigm to a random walk on a graph: rather than moving to a uniform random neighbour at each step, a controller is allowed to choose from two independent uniform random neighbours. We prove that this allows the controller to significantly accelerate the hitting and cover times in several natural graph classes. In particular, we show that the cover time becomes linear in the number n of vertices on discrete tori and bounded degree trees, of order
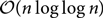 $${\mathcal O}(n\log \log n)$$ on bounded degree expanders, and of order
$${\mathcal O}(n\log \log n)$$ on bounded degree expanders, and of order 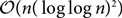 $${\mathcal O}(n{(\log \log n)^2})$$ on the Erdős–Rényi random graph in a certain sparsely connected regime. We also consider the algorithmic question of computing an optimal strategy and prove a dichotomy in efficiency between computing strategies for hitting and cover times.
$${\mathcal O}(n{(\log \log n)^2})$$ on the Erdős–Rényi random graph in a certain sparsely connected regime. We also consider the algorithmic question of computing an optimal strategy and prove a dichotomy in efficiency between computing strategies for hitting and cover times.

Counterexamples in Measure and Integration
-
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021
4 - Integration and Measure
- from Part II - Probability Theory
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 45-137
-
- Chapter
- Export citation
PROPERTIES OF THE INVERSE OF A NONCENTRAL WISHART MATRIX
-
- Journal:
- Econometric Theory / Volume 38 / Issue 6 / December 2022
- Published online by Cambridge University Press:
- 27 May 2021, pp. 1092-1116
-
- Article
-
- You have access
- Open access
- Export citation
9 - a.u. Continuous Process
- from Part III - Stochastic Process
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 331-373
-
- Chapter
- Export citation
Dedication
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp v-vi
-
- Chapter
- Export citation
Appendices
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 575-576
-
- Chapter
- Export citation
2 - Preliminaries
- from Part I - Introduction and Preliminaries
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 6-16
-
- Chapter
- Export citation
11 - Markov Process
- from Part III - Stochastic Process
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 493-574
-
- Chapter
- Export citation
Contents
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp vii-ix
-
- Chapter
- Export citation
Index
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 609-612
-
- Chapter
- Export citation
Appendix B - Taylor’s Theorem
- from Appendices
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 605-605
-
- Chapter
- Export citation
Appendix A - Change of Integration Variables
- from Appendices
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 577-604
-
- Chapter
- Export citation
Nomenclature
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp xi-xiv
-
- Chapter
- Export citation
ENDOGENEITY IN SEMIPARAMETRIC THRESHOLD REGRESSION
-
- Journal:
- Econometric Theory / Volume 38 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 27 May 2021, pp. 562-595
-
- Article
- Export citation
3 - Partition of Unity
- from Part I - Introduction and Preliminaries
-
- Book:
- Foundations of Constructive Probability Theory
- Published online:
- 07 May 2021
- Print publication:
- 27 May 2021, pp 17-42
-
- Chapter
- Export citation
