Refine search
Actions for selected content:
52669 results in Statistics and Probability
Evidence of on-going transmission of Shiga toxin-producing Escherichia coli O157:H7 following a foodborne outbreak
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 07 June 2021, e147
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Designing a Bonus-Malus system reflecting the claim size under the dependent frequency–severity model
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 07 June 2021, pp. 963-987
-
- Article
- Export citation
On the temporal evolution of turbopause altitude, 1996–2021, 70°N, 19°E
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 04 June 2021, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Productive efficiency of traditional multiple cropping systems compared to monocultures of seven crop species: a benchmark study
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 04 June 2021, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
High but slightly declining COVID-19 vaccine acceptance and reasons for vaccine acceptance, Finland April to December 2020–Corrigendum
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 04 June 2021, e133
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CONSTRAINT QUALIFICATIONS IN PARTIAL IDENTIFICATION
-
- Journal:
- Econometric Theory / Volume 38 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 04 June 2021, pp. 596-619
-
- Article
- Export citation
UNIFORM-IN-SUBMODEL BOUNDS FOR LINEAR REGRESSION IN A MODEL-FREE FRAMEWORK
-
- Journal:
- Econometric Theory / Volume 39 / Issue 6 / December 2023
- Published online by Cambridge University Press:
- 04 June 2021, pp. 1202-1248
-
- Article
-
- You have access
- Open access
- Export citation
APPLYING ECONOMIC MEASURES TO LAPSE RISK MANAGEMENT WITH MACHINE LEARNING APPROACHES
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 04 June 2021, pp. 839-871
- Print publication:
- September 2021
-
- Article
- Export citation
NONPARAMETRIC SIGNIFICANCE TESTING IN MEASUREMENT ERROR MODELS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 04 June 2021, pp. 454-496
-
- Article
- Export citation
-
We develop the first nonparametric significance test for regression models with classical measurement error in the regressors. In particular, a Cramér-von Mises test and a Kolmogorov–Smirnov test for the null hypothesis
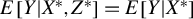 $E\left [Y|X^{*},Z^{*}\right ]=E\left [Y|X^{*}\right ]$ are proposed when only noisy measurements of
$E\left [Y|X^{*},Z^{*}\right ]=E\left [Y|X^{*}\right ]$ are proposed when only noisy measurements of 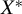 $X^{*}$ and
$X^{*}$ and  $Z^{*}$ are available. The asymptotic null distributions of the test statistics are derived, and a bootstrap method is implemented to obtain the critical values. Despite the test statistics being constructed using deconvolution estimators, we show that the test can detect a sequence of local alternatives converging to the null at the
$Z^{*}$ are available. The asymptotic null distributions of the test statistics are derived, and a bootstrap method is implemented to obtain the critical values. Despite the test statistics being constructed using deconvolution estimators, we show that the test can detect a sequence of local alternatives converging to the null at the 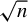 $\sqrt {n}$-rate. We also highlight the finite sample performance of the test through a Monte Carlo study.
$\sqrt {n}$-rate. We also highlight the finite sample performance of the test through a Monte Carlo study.
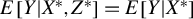
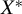

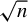
IDENTIFICATION AND ESTIMATION IN A CORRELATED RANDOM COEFFICIENTS TRANSFORMATION MODEL
-
- Journal:
- Econometric Theory / Volume 38 / Issue 4 / August 2022
- Published online by Cambridge University Press:
- 04 June 2021, pp. 621-688
-
- Article
- Export citation
-
This study examines identification and estimation in a correlated random coefficients (CRC) model with an unknown transformation of the dependent variable, namely
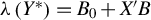 $\lambda \left (Y^{*}\right)=B_{0}+X^{\prime }B$, where the latent outcome
$\lambda \left (Y^{*}\right)=B_{0}+X^{\prime }B$, where the latent outcome 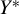 $Y^{*}$ may be subject to a certain kind of censoring mechanism,
$Y^{*}$ may be subject to a certain kind of censoring mechanism, 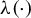 $\lambda (\cdot)$ is an unknown, one-to-one monotone function, and the random coefficients
$\lambda (\cdot)$ is an unknown, one-to-one monotone function, and the random coefficients 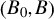 $\left (B_{0},B\right)$ are allowed to be correlated with one or several components of X. Under a conditional median independence plus a conditional median zero restriction, the mean of B is shown to be identified up to scale. Moreover, we show the derivative of the median structural function (MSF) is point identified. This derivative of MSF resembles the marginal treatment effect introduced by Heckman and Vytlacil (2005, Econometrica 73, 669–738).
$\left (B_{0},B\right)$ are allowed to be correlated with one or several components of X. Under a conditional median independence plus a conditional median zero restriction, the mean of B is shown to be identified up to scale. Moreover, we show the derivative of the median structural function (MSF) is point identified. This derivative of MSF resembles the marginal treatment effect introduced by Heckman and Vytlacil (2005, Econometrica 73, 669–738).It generalizes the usual average treatment effect in a linear CRC model and coincides with
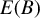 $E(B)$ when
$E(B)$ when 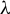 $\lambda $ is equal to the identity function; it is invariant to both location and scale normalization on the coefficients. We develop estimators for the identified parameters and derive asymptotic properties for the derivative of MSF. An empirical example using the U.K. Family Expenditure Survey is provided.
$\lambda $ is equal to the identity function; it is invariant to both location and scale normalization on the coefficients. We develop estimators for the identified parameters and derive asymptotic properties for the derivative of MSF. An empirical example using the U.K. Family Expenditure Survey is provided.
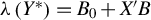
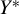
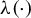
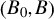
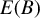
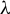
A UNIFORM BOUND ON THE OPERATOR NORM OF SUB-GAUSSIAN RANDOM MATRICES AND ITS APPLICATIONS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 6 / December 2022
- Published online by Cambridge University Press:
- 04 June 2021, pp. 1073-1091
-
- Article
- Export citation
-
For an
 $N \times T$ random matrix
$N \times T$ random matrix 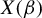 $X(\beta )$ with weakly dependent uniformly sub-Gaussian entries
$X(\beta )$ with weakly dependent uniformly sub-Gaussian entries 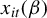 $x_{it}(\beta )$ that may depend on a possibly infinite-dimensional parameter
$x_{it}(\beta )$ that may depend on a possibly infinite-dimensional parameter  $\beta \in \mathbf {B}$, we obtain a uniform bound on its operator norm of the form
$\beta \in \mathbf {B}$, we obtain a uniform bound on its operator norm of the form 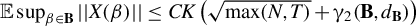 $\mathbb {E} \sup _{\beta \in \mathbf {B}} ||X(\beta )|| \leq CK \left (\sqrt {\max (N,T)} + \gamma _2(\mathbf {B},d_{\mathbf {B}})\right )$, where C is an absolute constant, K controls the tail behavior of (the increments of)
$\mathbb {E} \sup _{\beta \in \mathbf {B}} ||X(\beta )|| \leq CK \left (\sqrt {\max (N,T)} + \gamma _2(\mathbf {B},d_{\mathbf {B}})\right )$, where C is an absolute constant, K controls the tail behavior of (the increments of) 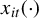 $x_{it}(\cdot )$, and
$x_{it}(\cdot )$, and  $\gamma _2(\mathbf {B},d_{\mathbf {B}})$ is Talagrand’s functional, a measure of multiscale complexity of the metric space
$\gamma _2(\mathbf {B},d_{\mathbf {B}})$ is Talagrand’s functional, a measure of multiscale complexity of the metric space 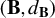 $(\mathbf {B},d_{\mathbf {B}})$. We illustrate how this result may be used for estimation that seeks to minimize the operator norm of moment conditions as well as for estimation of the maximal number of factors with functional data.
$(\mathbf {B},d_{\mathbf {B}})$. We illustrate how this result may be used for estimation that seeks to minimize the operator norm of moment conditions as well as for estimation of the maximal number of factors with functional data.

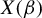
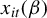

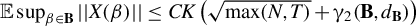
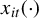

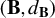
NONPARAMETRIC WEIGHTED AVERAGE QUANTILE DERIVATIVE
-
- Journal:
- Econometric Theory / Volume 38 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 03 June 2021, pp. 497-535
-
- Article
-
- You have access
- Open access
- Export citation
Risk factors for antibiotic resistance development in healthcare settings in China: a systematic review
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 03 June 2021, e141
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk-sensitive average continuous-time Markov decision processes with unbounded transition and cost rates
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 523-550
- Print publication:
- June 2021
-
- Article
- Export citation
Sensitivity of mean-field fluctuations in Erlang loss models with randomized routing
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 428-448
- Print publication:
- June 2021
-
- Article
- Export citation
-
In this paper we study a large system of N servers, each with capacity to process at most C simultaneous jobs; an incoming job is routed to a server if it has the lowest occupancy amongst d (out of N) randomly selected servers. A job that is routed to a server with no vacancy is assumed to be blocked and lost. Such randomized policies are referred to JSQ(d) (Join the Shortest Queue out of d) policies. Under the assumption that jobs arrive according to a Poisson process with rate
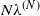 $N\lambda^{(N)}$ where
$N\lambda^{(N)}$ where 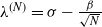 $\lambda^{(N)}=\sigma-\frac{\beta}{\sqrt{N}\,}$,
$\lambda^{(N)}=\sigma-\frac{\beta}{\sqrt{N}\,}$, 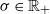 $\sigma\in\mathbb{R}_+$ and
$\sigma\in\mathbb{R}_+$ and 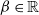 $\beta\in\mathbb{R}$, we establish functional central limit theorems for the fluctuation process in both the transient and stationary regimes when service time distributions are exponential. In particular, we show that the limit is an Ornstein–Uhlenbeck process whose mean and variance depend on the mean field of the considered model. Using this, we obtain approximations to the blocking probabilities for large N, where we can precisely estimate the accuracy of first-order approximations.
$\beta\in\mathbb{R}$, we establish functional central limit theorems for the fluctuation process in both the transient and stationary regimes when service time distributions are exponential. In particular, we show that the limit is an Ornstein–Uhlenbeck process whose mean and variance depend on the mean field of the considered model. Using this, we obtain approximations to the blocking probabilities for large N, where we can precisely estimate the accuracy of first-order approximations.
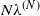
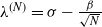
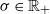
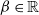
Random additions in urns of integers
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 335-346
- Print publication:
- June 2021
-
- Article
- Export citation
On gradual-impulse control of continuous-time Markov decision processes with exponential utility
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 July 2021, pp. 301-334
- Print publication:
- June 2021
-
- Article
- Export citation
On classes of life distributions based on the mean time to failure function
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 289-313
- Print publication:
- June 2021
-
- Article
- Export citation
-
The performance and effectiveness of an age replacement policy can be assessed by its mean time to failure (MTTF) function. We develop shock model theory in different scenarios for classes of life distributions based on the MTTF function where the probabilities
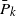 $\bar{P}_k$ of surviving the first k shocks are assumed to have discrete DMTTF, IMTTF and IDMTTF properties. The cumulative damage model of A-Hameed and Proschan [1] is studied in this context and analogous results are established. Weak convergence and moment convergence issues within the IDMTTF class of life distributions are explored. The preservation of the IDMTTF property under some basic reliability operations is also investigated. Finally we show that the intersection of IDMRL and IDMTTF classes contains the BFR family and establish results outlining the positions of various non-monotonic ageing classes in the hierarchy.
$\bar{P}_k$ of surviving the first k shocks are assumed to have discrete DMTTF, IMTTF and IDMTTF properties. The cumulative damage model of A-Hameed and Proschan [1] is studied in this context and analogous results are established. Weak convergence and moment convergence issues within the IDMTTF class of life distributions are explored. The preservation of the IDMTTF property under some basic reliability operations is also investigated. Finally we show that the intersection of IDMRL and IDMTTF classes contains the BFR family and establish results outlining the positions of various non-monotonic ageing classes in the hierarchy.
Gibbs partitions, Riemann–Liouville fractional operators, Mittag–Leffler functions, and fragmentations derived from stable subordinators
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 314-334
- Print publication:
- June 2021
-
- Article
- Export citation
-
Pitman (2003), and subsequently Gnedin and Pitman (2006), showed that a large class of random partitions of the integers derived from a stable subordinator of index
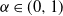 $\alpha\in(0,1)$ have infinite Gibbs (product) structure as a characterizing feature. The most notable case are random partitions derived from the two-parameter Poisson–Dirichlet distribution,
$\alpha\in(0,1)$ have infinite Gibbs (product) structure as a characterizing feature. The most notable case are random partitions derived from the two-parameter Poisson–Dirichlet distribution, 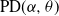 $\textrm{PD}(\alpha,\theta)$, whose corresponding
$\textrm{PD}(\alpha,\theta)$, whose corresponding  $\alpha$-diversity/local time have generalized Mittag–Leffler distributions, denoted by
$\alpha$-diversity/local time have generalized Mittag–Leffler distributions, denoted by 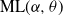 $\textrm{ML}(\alpha,\theta)$. Our aim in this work is to provide indications on the utility of the wider class of Gibbs partitions as it relates to a study of Riemann–Liouville fractional integrals and size-biased sampling, and in decompositions of special functions, and its potential use in the understanding of various constructions of more exotic processes. We provide characterizations of general laws associated with nested families of
$\textrm{ML}(\alpha,\theta)$. Our aim in this work is to provide indications on the utility of the wider class of Gibbs partitions as it relates to a study of Riemann–Liouville fractional integrals and size-biased sampling, and in decompositions of special functions, and its potential use in the understanding of various constructions of more exotic processes. We provide characterizations of general laws associated with nested families of 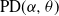 $\textrm{PD}(\alpha,\theta)$ mass partitions that are constructed from fragmentation operations described in Dong et al. (2014). These operations are known to be related in distribution to various constructions of discrete random trees/graphs in [n], and their scaling limits. A centerpiece of our work is results related to Mittag–Leffler functions, which play a key role in fractional calculus and are otherwise Laplace transforms of the
$\textrm{PD}(\alpha,\theta)$ mass partitions that are constructed from fragmentation operations described in Dong et al. (2014). These operations are known to be related in distribution to various constructions of discrete random trees/graphs in [n], and their scaling limits. A centerpiece of our work is results related to Mittag–Leffler functions, which play a key role in fractional calculus and are otherwise Laplace transforms of the 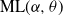 $\textrm{ML}(\alpha,\theta)$ variables. Notably, this leads to an interpretation within the context of
$\textrm{ML}(\alpha,\theta)$ variables. Notably, this leads to an interpretation within the context of 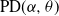 $\textrm{PD}(\alpha,\theta)$ laws conditioned on Poisson point process counts over intervals of scaled lengths of the
$\textrm{PD}(\alpha,\theta)$ laws conditioned on Poisson point process counts over intervals of scaled lengths of the  $\alpha$-diversity.
$\alpha$-diversity.
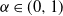
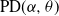

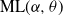
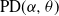
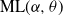
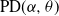

Kelly and Jackson networks with interchangeable, cooperative servers
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 July 2021, pp. 463-483
- Print publication:
- June 2021
-
- Article
- Export citation
