Refine search
Actions for selected content:
53140 results in Statistics and Probability
Estimation of on- and off-time distributions in a dynamic Erdős–Rényi random graph
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 09 October 2025, pp. 562-591
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparison on the criticality parameters for two supercritical branching processes with immigration in random environments
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 08 October 2025, pp. 238-271
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper considers two supercritical branching processes with immigration in different random environments, denoted by
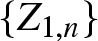 $\{Z_{1,n}\}$ and
$\{Z_{1,n}\}$ and 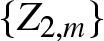 $\{Z_{2,m}\}$, with criticality parameters µ1 and µ2, respectively. Under certain conditions, it is known that
$\{Z_{2,m}\}$, with criticality parameters µ1 and µ2, respectively. Under certain conditions, it is known that 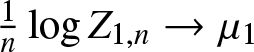 $\frac{1}{n} \log Z_{1,n} \to \mu_1$ and
$\frac{1}{n} \log Z_{1,n} \to \mu_1$ and 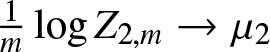 $\frac{1}{m} \log Z_{2,m} \to \mu_2$ converge in probability as
$\frac{1}{m} \log Z_{2,m} \to \mu_2$ converge in probability as 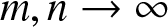 $m, n \to \infty$. We present basic properties about a central limit theorem, a non-uniform Berry–Esseen’s bound, and Cramér’s moderate deviations for
$m, n \to \infty$. We present basic properties about a central limit theorem, a non-uniform Berry–Esseen’s bound, and Cramér’s moderate deviations for 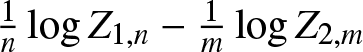 $\frac{1}{n} \log Z_{1,n} - \frac{1}{m} \log Z_{2,m}$ as
$\frac{1}{n} \log Z_{1,n} - \frac{1}{m} \log Z_{2,m}$ as 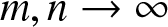 $m, n \to \infty$. To this end, applications to construction of confidence intervals and simulations are also given.
$m, n \to \infty$. To this end, applications to construction of confidence intervals and simulations are also given.
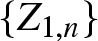
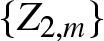
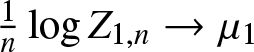
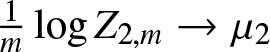
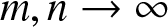
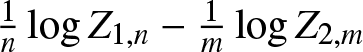
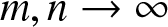
Saturation in random hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 07 October 2025, pp. 40-58
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
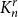 $K^r_n$ be the complete
$K^r_n$ be the complete  $r$-uniform hypergraph on
$r$-uniform hypergraph on  $n$ vertices, that is, the hypergraph whose vertex set is
$n$ vertices, that is, the hypergraph whose vertex set is 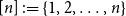 $[n] \, :\! = \{1,2,\ldots ,n\}$ and whose edge set is
$[n] \, :\! = \{1,2,\ldots ,n\}$ and whose edge set is 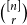 $\binom {[n]}{r}$. We form
$\binom {[n]}{r}$. We form 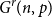 $G^r(n,p)$ by retaining each edge of
$G^r(n,p)$ by retaining each edge of 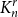 $K^r_n$ independently with probability
$K^r_n$ independently with probability 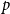 $p$. An
$p$. An  $r$-uniform hypergraph
$r$-uniform hypergraph 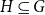 $H\subseteq G$ is
$H\subseteq G$ is 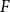 $F$-saturated if
$F$-saturated if 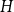 $H$ does not contain any copy of
$H$ does not contain any copy of 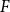 $F$, but any missing edge of
$F$, but any missing edge of 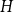 $H$ in
$H$ in 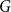 $G$ creates a copy of
$G$ creates a copy of 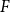 $F$. Furthermore, we say that
$F$. Furthermore, we say that 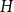 $H$ is weakly
$H$ is weakly 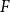 $F$-saturated in
$F$-saturated in 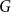 $G$ if
$G$ if 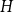 $H$ does not contain any copy of
$H$ does not contain any copy of 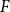 $F$, but the missing edges of
$F$, but the missing edges of 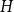 $H$ in
$H$ in 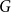 $G$ can be added back one-by-one, in some order, such that every edge creates a new copy of
$G$ can be added back one-by-one, in some order, such that every edge creates a new copy of 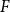 $F$. The smallest number of edges in an
$F$. The smallest number of edges in an 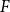 $F$-saturated hypergraph in
$F$-saturated hypergraph in 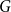 $G$ is denoted by
$G$ is denoted by 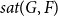 ${\textit {sat}}(G,F)$, and in a weakly
${\textit {sat}}(G,F)$, and in a weakly 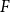 $F$-saturated hypergraph in
$F$-saturated hypergraph in 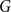 $G$ by
$G$ by 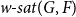 $\mathop {\mbox{$w$-${sat}$}}\! (G,F)$. In 2017, Korándi and Sudakov initiated the study of saturation in random graphs, showing that for constant
$\mathop {\mbox{$w$-${sat}$}}\! (G,F)$. In 2017, Korándi and Sudakov initiated the study of saturation in random graphs, showing that for constant 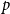 $p$, with high probability
$p$, with high probability 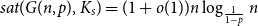 ${\textit {sat}}(G(n,p),K_s)=(1+o(1))n\log _{\frac {1}{1-p}}n$, and
${\textit {sat}}(G(n,p),K_s)=(1+o(1))n\log _{\frac {1}{1-p}}n$, and 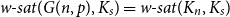 $\mathop {\mbox{$w$-${sat}$}}\! (G(n,p),K_s)=\mathop {\mbox{$w$-${sat}$}}\! (K_n,K_s)$. Generalising their results, in this paper, we solve the saturation problem for random hypergraphs
$\mathop {\mbox{$w$-${sat}$}}\! (G(n,p),K_s)=\mathop {\mbox{$w$-${sat}$}}\! (K_n,K_s)$. Generalising their results, in this paper, we solve the saturation problem for random hypergraphs 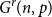 $G^r(n,p)$ for cliques
$G^r(n,p)$ for cliques 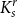 $K_s^r$, for every
$K_s^r$, for every 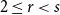 $2\le r \lt s$ and constant
$2\le r \lt s$ and constant 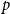 $p$.
$p$.
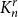


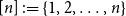
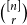
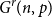
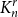
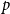

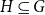
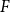
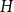
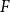
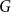
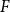
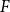
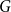
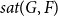
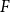
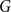
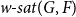
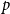
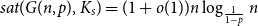
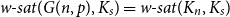
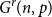
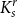
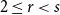
Increased detection of Shiga toxin-producing Escherichia coli (STEC) O26: Environmental exposures and clinical outcomes, England, 2014–2023
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 07 October 2025, e123
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk factors for acute gastrointestinal illness in a Canadian population-based linkage cohort
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 07 October 2025, e124
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tracking the evolutionary footprint of Mpox in West Africa: phylogenetic and clade analysis
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 07 October 2025, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mask wearing by COVID-19 index cases reduces SARS-CoV-2 transmission to household contacts
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 06 October 2025, e125
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ESBL-producing Klebsiella pneumoniae gut colonisation and subsequent health-care associated bacteraemia in preterm newborns: a descriptive cohort with nested case–control study
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 06 October 2025, e121
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Non-uniqueness phase in hyperbolic marked random connection models using the spherical transform
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 03 October 2025, pp. 697-744
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A non-uniqueness phase for infinite clusters is proven for a class of marked random connection models (RCMs) on the d-dimensional hyperbolic space,
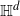 ${\mathbb{H}^d}$, in a high volume-scaling regime. The approach taken in this paper utilizes the spherical transform on
${\mathbb{H}^d}$, in a high volume-scaling regime. The approach taken in this paper utilizes the spherical transform on 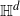 ${\mathbb{H}^d}$ to diagonalize convolution by the adjacency function and the two-point function and bound their
${\mathbb{H}^d}$ to diagonalize convolution by the adjacency function and the two-point function and bound their 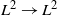 $L^2\to L^2$ operator norms. Under some circumstances, this spherical transform approach also provides bounds on the triangle diagram that allows for a derivation of certain mean-field critical exponents. In particular, the results are applied to some Boolean and weight-dependent hyperbolic RCMs. While most of the paper is concerned with the high volume-scaling regime, the existence of the non-uniqueness phase is also proven without this scaling for some RCMs whose resulting graphs are almost surely not locally finite.
$L^2\to L^2$ operator norms. Under some circumstances, this spherical transform approach also provides bounds on the triangle diagram that allows for a derivation of certain mean-field critical exponents. In particular, the results are applied to some Boolean and weight-dependent hyperbolic RCMs. While most of the paper is concerned with the high volume-scaling regime, the existence of the non-uniqueness phase is also proven without this scaling for some RCMs whose resulting graphs are almost surely not locally finite.
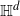
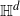
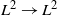
matrixdist: an R package for statistical analysis of matrix distributions
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 2 / July 2026
- Published online by Cambridge University Press:
- 02 October 2025, pp. 217-251
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Large and moderate deviations for Gaussian neural networks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 01 October 2025, pp. 96-115
- Print publication:
- March 2026
-
- Article
- Export citation
Limit theorems for the number of crossings and stress in projections of a random geometric graph
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 01 October 2025, pp. 258-281
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the number of edge crossings in a random graph drawing generated by projecting a random geometric graph on some compact convex set
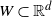 $W\subset \mathbb{R}^d$,
$W\subset \mathbb{R}^d$, 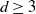 $d\geq 3$, onto a plane. The positions of these crossings form the support of a point process. We show that if the expected number of crossings converges to a positive but finite value, this point process converges to a Poisson point process in the Kantorovich–Rubinstein distance. We further show a multivariate central limit theorem between the number of crossings and a second variable called the stress that holds when the expected vertex degree in the random geometric graph converges to a positive finite value.
$d\geq 3$, onto a plane. The positions of these crossings form the support of a point process. We show that if the expected number of crossings converges to a positive but finite value, this point process converges to a Poisson point process in the Kantorovich–Rubinstein distance. We further show a multivariate central limit theorem between the number of crossings and a second variable called the stress that holds when the expected vertex degree in the random geometric graph converges to a positive finite value.
Integral stochastic orders with parametric classes of functions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 01 October 2025, pp. 1-31
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Duality and transform analysis for non-decreasing functionals of stochastic processes and their applications
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 30 September 2025, pp. 348-374
- Print publication:
- March 2026
-
- Article
- Export citation
Mixed-state branching evolution for cell division models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 29 September 2025, pp. 135-156
- Print publication:
- March 2026
-
- Article
- Export citation
-
We prove a scaling limit theorem for two-type Galton–Watson branching processes with interaction. The limit theorem gives rise to a class of mixed-state branching processes with interaction used to simulate evolution for cell division affected by parasites. Such processes can also be obtained by the pathwise-unique solution to a stochastic equation system. Moreover, we present sufficient conditions for extinction with probability 1 and the exponential ergodicity in the
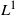 $L^1$-Wasserstein distance of such processes in some cases.
$L^1$-Wasserstein distance of such processes in some cases.
Explicit pathwise expansion for multivariate diffusions with applications
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 29 September 2025, pp. 592-625
- Print publication:
- June 2026
-
- Article
- Export citation
Text message surveillance for rapid salmonella outbreak detection: a novel public health approach
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 29 September 2025, e118
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Embracing foresight in migration policy: a transformative journey toward Anticipatory Governance in North Macedonia
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 29 September 2025, e67
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Two-type branching processes with immigration, and the structured coalescents
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 29 September 2025, pp. 32-60
- Print publication:
- March 2026
-
- Article
- Export citation
SEMIPARAMETRIC ESTIMATION OF QUANTILE REGRESSION WITH BINARY QUANTILE SELECTION
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 29 September 2025, pp. 1-44
-
- Article
-
- You have access
- Open access
- Export citation
-
This article proposes a novel method for estimating quantile regression models that account for sample selection. Unlike the approach by Arellano and Bonhomme (2017, Econometrica 85(1), 1–28; hereafter referred to as AB17), which employs a parametric selection equation, our method utilizes a standard binary quantile regression model to handle the selection issue, thereby accommodating general heterogeneity in both the selection and outcome equations. We adopt a semiparametric estimation technique for the outcome quantile regression by integrating local moment conditions, resulting in
 $\sqrt {n}$-consistent estimators for the quantile coefficients and copula parameter. Monte Carlo simulation results demonstrate that our estimator performs well in finite samples. Additionally, we apply our method to examine the wage distribution among women using a randomly simulated sample from the US General Social Survey. Our key finding is the presence of significant positive selection among women in the US, which is notably more pronounced than the estimates produced by the AB17’s model.
$\sqrt {n}$-consistent estimators for the quantile coefficients and copula parameter. Monte Carlo simulation results demonstrate that our estimator performs well in finite samples. Additionally, we apply our method to examine the wage distribution among women using a randomly simulated sample from the US General Social Survey. Our key finding is the presence of significant positive selection among women in the US, which is notably more pronounced than the estimates produced by the AB17’s model.

