Refine search
Actions for selected content:
53140 results in Statistics and Probability
Behavioural perspectives on personal health data sharing and app design: an international survey study
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 25 September 2025, e66
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Contents
-
- Book:
- Statistics for Chemical Engineers
- Published online:
- 12 December 2025
- Print publication:
- 25 September 2025, pp vii-x
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Statistics for Chemical Engineers
- Published online:
- 12 December 2025
- Print publication:
- 25 September 2025, pp iv-iv
-
- Chapter
- Export citation
References
-
- Book:
- Statistics for Chemical Engineers
- Published online:
- 12 December 2025
- Print publication:
- 25 September 2025, pp 437-440
-
- Chapter
- Export citation
Mean flow data assimilation using physics-constrained graph neural networks
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 25 September 2025, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A brief review of deep learning methods in mortality forecasting
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 24 September 2025, pp. 150-165
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Hands-On Network Machine Learning with Python
-
- Published online:
- 23 September 2025
- Print publication:
- 18 September 2025
Data visualization tool for a fairer geography of refugee protection in Europe
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 22 September 2025, e63
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Adversarial natural language processing: overview, challenges, and policy implications
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 22 September 2025, e64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Leveraging AI in peace processes: A framework for digital dialogues
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 22 September 2025, e65
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Worldwide threatening prevalence of carbapenem-resistant Pseudomonas aeruginosa
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 19 September 2025, e114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparing the sets of volume polynomials and Lorentzian polynomials
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 19 September 2025, pp. 26-39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given
 $n$ convex bodies in the Euclidean space
$n$ convex bodies in the Euclidean space 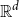 $\mathbb{R}^d$, we can find their volume polynomial which is a homogeneous polynomial of degree
$\mathbb{R}^d$, we can find their volume polynomial which is a homogeneous polynomial of degree 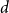 $d$ in
$d$ in  $n$ variables. We consider the set of homogeneous polynomials of degree
$n$ variables. We consider the set of homogeneous polynomials of degree 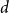 $d$ in
$d$ in  $n$ variables that can be represented as the volume polynomial of any such given convex bodies. This set is a subset of the set of Lorentzian polynomials. Using our knowledge of operations that preserve the Lorentzian property, we give a complete classification of the cases for
$n$ variables that can be represented as the volume polynomial of any such given convex bodies. This set is a subset of the set of Lorentzian polynomials. Using our knowledge of operations that preserve the Lorentzian property, we give a complete classification of the cases for 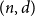 $(n,d)$ when the two sets are equal.
$(n,d)$ when the two sets are equal.

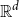
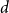

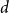

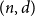
Metastability for telegraph processes in a double-well potential
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 19 September 2025, pp. 204-224
- Print publication:
- March 2026
-
- Article
- Export citation
Phylodynamic inference suggests introductions as main driver of Mpox Clade II outbreak in 2022 in Slovenia
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 19 September 2025, e115
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From ‘wild west’ to ‘responsible’ AI testing ‘in-the-wild’: lessons from live facial recognition testing by law enforcement authorities in Europe
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 19 September 2025, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Glauber dynamics for the hard-core model on bounded-degree
 $H$-free graphs
$H$-free graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 6 / November 2025
- Published online by Cambridge University Press:
- 19 September 2025, pp. 803-814
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The hard-core model has as its configurations the independent sets of some graph instance
 $G$. The probability distribution on independent sets is controlled by a ‘fugacity’
$G$. The probability distribution on independent sets is controlled by a ‘fugacity’  $\lambda \gt 0$, with higher
$\lambda \gt 0$, with higher  $\lambda$ leading to denser configurations. We investigate the mixing time of Glauber (single-site) dynamics for the hard-core model on restricted classes of bounded-degree graphs in which a particular graph
$\lambda$ leading to denser configurations. We investigate the mixing time of Glauber (single-site) dynamics for the hard-core model on restricted classes of bounded-degree graphs in which a particular graph  $H$ is excluded as an induced subgraph. If
$H$ is excluded as an induced subgraph. If  $H$ is a subdivided claw then, for all
$H$ is a subdivided claw then, for all  $\lambda$, the mixing time is
$\lambda$, the mixing time is  $O(n\log n)$, where
$O(n\log n)$, where  $n$ is the order of
$n$ is the order of  $G$. This extends a result of Chen and Gu for claw-free graphs. When
$G$. This extends a result of Chen and Gu for claw-free graphs. When  $H$ is a path, the set of possible instances is finite. For all other
$H$ is a path, the set of possible instances is finite. For all other  $H$, the mixing time is exponential in
$H$, the mixing time is exponential in  $n$ for sufficiently large
$n$ for sufficiently large  $\lambda$, depending on
$\lambda$, depending on  $H$ and the maximum degree of
$H$ and the maximum degree of  $G$.
$G$.
















Factors associated with persistence or recovery from long COVID 6 months post-SARS-CoV-2 infection
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 18 September 2025, e116
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Preface
-
- Book:
- Hands-On Network Machine Learning with Python
- Published online:
- 23 September 2025
- Print publication:
- 18 September 2025, pp ix-xvi
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Hands-On Network Machine Learning with Python
- Published online:
- 23 September 2025
- Print publication:
- 18 September 2025, pp i-iv
-
- Chapter
- Export citation
Appendix B - Learning Representations Theory
-
- Book:
- Hands-On Network Machine Learning with Python
- Published online:
- 23 September 2025
- Print publication:
- 18 September 2025, pp 433-453
-
- Chapter
- Export citation
