Refine search
Actions for selected content:
53140 results in Statistics and Probability
Optimal stopping with variable attention
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 09 September 2025, pp. 235-268
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Proper minor-closed classes of graphs have Assouad–Nagata dimension 2
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 09 September 2025, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multi-cluster outbreak of Salmonella Typhimurium sequence type 36 linked to alfalfa sprouts, Sweden, August–November 2024
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 08 September 2025, e108
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiology of carbapenem-resistant Enterobacterales infections in Tennessee, 2016–2022
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 08 September 2025, e119
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating the national seroprevalence of Toxoplasma gondii infection in pregnant women, France 2021
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 08 September 2025, e107
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Harnessing hybrid digital twinning for decision-support in smart infrastructures
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 08 September 2025, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Introducing and applying varinaccuracy: a measure for doubly truncated random variables in reliability analysis
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 05 September 2025, pp. 155-181
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stationary probabilities and the monotone likelihood ratio in bonus-malus systems
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 04 September 2025, pp. 89-100
- Print publication:
- January 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Spectral goodness-of-fit tests for complete and partial network data
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 04 September 2025, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Antibiotic resistance and factors associated with colonization dynamics of Staphylococcus aureus and Streptococcus pneumoniae in healthy children in Lima, Peru
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 04 September 2025, e106
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A retrospective global study of the prevalence of O-serotypes of invasive Escherichia coli disease in patients admitted to tertiary care hospitals
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 03 September 2025, e109
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The time until a random walk exceeds a square root and other barriers
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 03 September 2025, pp. 146-153
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper investigates the time N until a random walk first exceeds some specified barrier. Letting
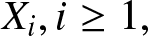 $X_i, i \geq 1,$ be a sequence of independent, identically distributed random variables with a log-concave density or probability mass function, we derive both lower and upper bounds on the probability
$X_i, i \geq 1,$ be a sequence of independent, identically distributed random variables with a log-concave density or probability mass function, we derive both lower and upper bounds on the probability 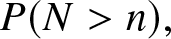 $P(N \gt n),$ as well as bounds on the expected value
$P(N \gt n),$ as well as bounds on the expected value 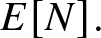 $E[N].$ On barriers of the form
$E[N].$ On barriers of the form 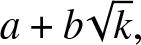 $a + b \sqrt{k},$ where a is nonnegative, b is positive, and k is the number of steps, we provide additional bounds on
$a + b \sqrt{k},$ where a is nonnegative, b is positive, and k is the number of steps, we provide additional bounds on 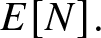 $E[N].$
$E[N].$
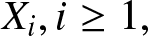
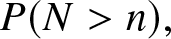
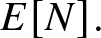
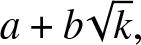
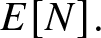
Whittaker–Henderson smoothing revisited: A modern statistical framework for practical use
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 03 September 2025, pp. 1-31
- Print publication:
- January 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A polytopic approach to democratising decision-making on health data reuse in the European Union
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 03 September 2025, e60
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
“On Contemporary Mortality Models for Actuarial Use I: practice and II: principles” by Professor Angus Macdonald and Dr Stephen Richards
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 02 September 2025, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk-sharing rules for mortality pooling products with stochastic and correlated mortality rates
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 15 September 2025, pp. 585-614
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Editorial: Special issue on risk sharing
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 01 October 2025, pp. 487-491
- Print publication:
- September 2025
-
- Article
-
- You have access
- HTML
- Export citation
Optimal design of fixed and variable costs in peer-to-peer insurance with heterogeneous risk
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 22 September 2025, pp. 721-746
- Print publication:
- September 2025
-
- Article
- Export citation
ASB volume 55 issue 3 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 01 October 2025, pp. f1-f2
- Print publication:
- September 2025
-
- Article
-
- You have access
- Export citation
ASB volume 55 issue 3 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 01 October 2025, pp. b1-b3
- Print publication:
- September 2025
-
- Article
-
- You have access
- Export citation
