Refine search
Actions for selected content:
53140 results in Statistics and Probability
Index
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 402-412
-
- Chapter
- Export citation
9 - Recurrent Events
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 230-248
-
- Chapter
- Export citation
12 - Correlated Events
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 304-334
-
- Chapter
- Export citation
2 - Probability Distributions
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 23-42
-
- Chapter
- Export citation
11 - Numerical Simulations
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 289-303
-
- Chapter
- Export citation
Predicting concrete strength using machine learning and fresh-state measurements
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 13 August 2025, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hitting probabilities of constrained random walks representing tandem networks
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 13 August 2025, pp. 90-145
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We develop anapproximation for the buffer overflow probability of a stable tandem network in dimensions three or more. The overflow event in terms of the constrained random walk representing the network is the following: the sum of the components of the process hits n before hitting 0. This is one of the most commonly studied rare events in the context of queueing systems and the constrained processes representing them. The approximation is valid for almost all initial points of the process and its relative error decays exponentially in n. The analysis is based on an affine transformation of the process and the problem; as
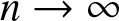 $n\rightarrow \infty$ the transformed process converges to an unstable constrained random walk. The approximation formula consists of the probability of the limit unstable process hitting a limit boundary in finite time. We give an explicit formula for this probability in terms of the utilization rates of the nodes of the network.
$n\rightarrow \infty$ the transformed process converges to an unstable constrained random walk. The approximation formula consists of the probability of the limit unstable process hitting a limit boundary in finite time. We give an explicit formula for this probability in terms of the utilization rates of the nodes of the network.
Autonomous unmanned aerial vehicles exploration for semantic indoor reconstruction using 3D Gaussian splatting
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 13 August 2025, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Utilizing large language models (LLMs) for quantitative reasoning-intensive tasks within the (re)insurance sector
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 12 August 2025, pp. 74-95
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Embedding nearly spanning trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 6 / November 2025
- Published online by Cambridge University Press:
- 11 August 2025, pp. 927-931
-
- Article
- Export citation
-
The Erdős-Sós Conjecture states that every graph with average degree exceeding
 $k-1$ contains every tree with
$k-1$ contains every tree with  $k$ edges as a subgraph. We prove that there are
$k$ edges as a subgraph. We prove that there are  $\delta \gt 0$ and
$\delta \gt 0$ and  $k_0\in \mathbb N$ such that the conjecture holds for every tree
$k_0\in \mathbb N$ such that the conjecture holds for every tree  $T$ with
$T$ with  $k \ge k_0$ edges and every graph
$k \ge k_0$ edges and every graph  $G$ with
$G$ with  $|V(G)| \le (1+\delta )|V(T)|$.
$|V(G)| \le (1+\delta )|V(T)|$.








THREE-DIMENSIONAL FACTOR MODELS WITH GLOBAL AND LOCAL FACTORS
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 11 August 2025, pp. 1-47
-
- Article
- Export citation
Public health agencies need to be ‘Kennedy ready’: take action now to protect vaccine confidence
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 11 August 2025, e91
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A multivariate spatiotemporal model for county-level mortality data in the contiguous United States
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 11 August 2025, pp. 54-73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A stability theorem for multi-partite graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 6 / November 2025
- Published online by Cambridge University Press:
- 11 August 2025, pp. 821-847
-
- Article
- Export citation
-
The Erdős–Simonovits stability theorem is one of the most widely used theorems in extremal graph theory. We obtain an Erdős–Simonovits type stability theorem in multi-partite graphs. Different from the Erdős–Simonovits stability theorem, our stability theorem in multi-partite graphs says that if the number of edges of an
 $H$-free graph
$H$-free graph  $G$ is close to the extremal graphs for
$G$ is close to the extremal graphs for  $H$, then
$H$, then  $G$ has a well-defined structure but may be far away from the extremal graphs for
$G$ has a well-defined structure but may be far away from the extremal graphs for  $H$. As applications, we strengthen a theorem of Bollobás, Erdős, and Straus and solve a conjecture in a stronger form posed by Han and Zhao concerning the maximum number of edges in multi-partite graphs which does not contain vertex-disjoint copies of a clique.
$H$. As applications, we strengthen a theorem of Bollobás, Erdős, and Straus and solve a conjecture in a stronger form posed by Han and Zhao concerning the maximum number of edges in multi-partite graphs which does not contain vertex-disjoint copies of a clique.





A conditional lower bound for the Turán number of spheres
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 6 / November 2025
- Published online by Cambridge University Press:
- 11 August 2025, pp. 848-856
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the hypergraph Turán problem of determining
 $ex(n, S^d)$, the maximum number of facets in a
$ex(n, S^d)$, the maximum number of facets in a  $d$-dimensional simplicial complex on
$d$-dimensional simplicial complex on  $n$ vertices that does not contain a simplicial
$n$ vertices that does not contain a simplicial  $d$-sphere (a homeomorph of
$d$-sphere (a homeomorph of  $S^d$) as a subcomplex. We show that if there is an affirmative answer to a question of Gromov about sphere enumeration in high dimensions, then
$S^d$) as a subcomplex. We show that if there is an affirmative answer to a question of Gromov about sphere enumeration in high dimensions, then  $ex(n, S^d) \geq \Omega (n^{d + 1 - (d + 1)/(2^{d + 1} - 2)})$. Furthermore, this lower bound holds unconditionally for 2-LC (locally constructible) spheres, which includes all shellable spheres and therefore all polytopes. We also prove an upper bound on
$ex(n, S^d) \geq \Omega (n^{d + 1 - (d + 1)/(2^{d + 1} - 2)})$. Furthermore, this lower bound holds unconditionally for 2-LC (locally constructible) spheres, which includes all shellable spheres and therefore all polytopes. We also prove an upper bound on  $ex(n, S^d)$ of
$ex(n, S^d)$ of  $O(n^{d + 1 - 1/2^{d - 1}})$ using a simple induction argument. We conjecture that the upper bound can be improved to match the conditional lower bound.
$O(n^{d + 1 - 1/2^{d - 1}})$ using a simple induction argument. We conjecture that the upper bound can be improved to match the conditional lower bound.








Convergence of the QuickVal residual
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 6 / November 2025
- Published online by Cambridge University Press:
- 11 August 2025, pp. 780-802
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
QuickSelect (also known as Find), introduced by Hoare ((1961) Commun. ACM 4 321–322.), is a randomized algorithm for selecting a specified order statistic from an input sequence of
 $n$ objects, or rather their identifying labels usually known as keys. The keys can be numeric or symbol strings, or indeed any labels drawn from a given linearly ordered set. We discuss various ways in which the cost of comparing two keys can be measured, and we can measure the efficiency of the algorithm by the total cost of such comparisons.
$n$ objects, or rather their identifying labels usually known as keys. The keys can be numeric or symbol strings, or indeed any labels drawn from a given linearly ordered set. We discuss various ways in which the cost of comparing two keys can be measured, and we can measure the efficiency of the algorithm by the total cost of such comparisons.We define and discuss a closely related algorithm known as QuickVal and a natural probabilistic model for the input to this algorithm; QuickVal searches (almost surely unsuccessfully) for a specified population quantile
 $\alpha \in [0, 1]$ in an input sample of size
$\alpha \in [0, 1]$ in an input sample of size  $n$. Call the total cost of comparisons for this algorithm
$n$. Call the total cost of comparisons for this algorithm  $S_n$. We discuss a natural way to define the random variables
$S_n$. We discuss a natural way to define the random variables  $S_1, S_2, \ldots$ on a common probability space. For a general class of cost functions, Fill and Nakama ((2013) Adv. Appl. Probab. 45 425–450.) proved under mild assumptions that the scaled cost
$S_1, S_2, \ldots$ on a common probability space. For a general class of cost functions, Fill and Nakama ((2013) Adv. Appl. Probab. 45 425–450.) proved under mild assumptions that the scaled cost  $S_n / n$ of QuickVal converges in
$S_n / n$ of QuickVal converges in  $L^p$ and almost surely to a limit random variable
$L^p$ and almost surely to a limit random variable  $S$. For a general cost function, we consider what we term the QuickVal residual:
$S$. For a general cost function, we consider what we term the QuickVal residual: \begin{equation*} \rho _n \,{:\!=}\, \frac {S_n}n - S. \end{equation*}
\begin{equation*} \rho _n \,{:\!=}\, \frac {S_n}n - S. \end{equation*}The residual is of natural interest, especially in light of the previous analogous work on the sorting algorithm QuickSort (Bindjeme and Fill (2012) 23rd International Meeting on Probabilistic, Combinatorial, and Asymptotic Methods for the Analysis of Algorithms (AofA'12), Discrete Mathematics, and Theoretical Computer Science Proceedings, AQ, Association: Discrete Mathematics and Theoretical Computer Science, Nancy, pp. 339–348; Neininger (2015) Random Struct. Algorithms 46 346–361; Fuchs (2015) Random Struct. Algorithms 46 677–687; Grübel and Kabluchko (2016) Ann. Appl. Probab. 26 3659–3698; Sulzbach (2017) Random Struct. Algorithms 50 493–508). In the case
 $\alpha = 0$ of QuickMin with unit cost per key-comparison, we are able to calculate–àla Bindjeme and Fill for QuickSort (Bindjeme and Fill (2012) 23rd International Meeting on Probabilistic, Combinatorial, and Asymptotic Methods for the Analysis of Algorithms (AofA'12), Discrete Mathematics and Theoretical Computer Science Proceedings, AQ, Association: Discrete Mathematics and Theoretical Computer Science, Nancy, pp. 339–348.)–the exact (and asymptotic)
$\alpha = 0$ of QuickMin with unit cost per key-comparison, we are able to calculate–àla Bindjeme and Fill for QuickSort (Bindjeme and Fill (2012) 23rd International Meeting on Probabilistic, Combinatorial, and Asymptotic Methods for the Analysis of Algorithms (AofA'12), Discrete Mathematics and Theoretical Computer Science Proceedings, AQ, Association: Discrete Mathematics and Theoretical Computer Science, Nancy, pp. 339–348.)–the exact (and asymptotic)  $L^2$-norm of the residual. We take the result as motivation for the scaling factor
$L^2$-norm of the residual. We take the result as motivation for the scaling factor  $\sqrt {n}$ for the QuickVal residual for general population quantiles and for general cost. We then prove in general (under mild conditions on the cost function) that
$\sqrt {n}$ for the QuickVal residual for general population quantiles and for general cost. We then prove in general (under mild conditions on the cost function) that  $\sqrt {n}\,\rho _n$ converges in law to a scale mixture of centered Gaussians, and we also prove convergence of moments.
$\sqrt {n}\,\rho _n$ converges in law to a scale mixture of centered Gaussians, and we also prove convergence of moments.













Measuring resilience in national food systems using “food systems resilience score”
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 08 August 2025, e54
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hierarchical Gaussian processes for characterizing gait variability in multiple sclerosis
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 07 August 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The future of learning or the future of dividing? Exploring the impact of generative artificial intelligence on higher education—CORRIGENDUM
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 06 August 2025, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analyzing state-level longevity trends with the U.S. mortality database
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 06 August 2025, pp. 22-53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
