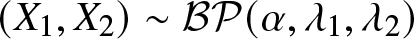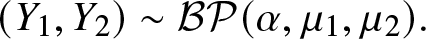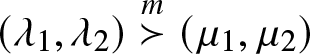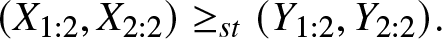Refine search
Actions for selected content:
53140 results in Statistics and Probability
Multiple highly resistant clones of MRSA circulating among patients with skin and soft tissue infection, Peshawar, Pakistan 2021–2022
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 16 September 2025, e113
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of influencing factors of concurrent primary liver cancer in hepatitis B patients and construction of column chart prediction model
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 16 September 2025, e111
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Modeling discrete common-shock risks through matrix distributions
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 16 September 2025, pp. 101-126
- Print publication:
- January 2026
-
- Article
- Export citation
Building Information Graphs (BIGs): remodeling building information for learning and applications
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 15 September 2025, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Uncovering policy priorities for disability inclusion: NLP and LLM approaches to analyzing CRPD state reports
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 15 September 2025, e61
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using graph neural networks and frequency domain data for automated operational modal analysis of populations of structures
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 15 September 2025, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The structure of identity facilitation and interference
- Part of
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 15 September 2025, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Industrial mobile robot-based manufacturing system modeling potential
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 15 September 2025, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An explicit economical additive basis
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 6 / November 2025
- Published online by Cambridge University Press:
- 12 September 2025, pp. 815-820
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present an explicit subset
 $A\subseteq \mathbb{N} = \{0,1,\ldots \}$ such that
$A\subseteq \mathbb{N} = \{0,1,\ldots \}$ such that  $A + A = \mathbb{N}$ and for all
$A + A = \mathbb{N}$ and for all  $\varepsilon \gt 0$,
$\varepsilon \gt 0$, \begin{equation*}\lim _{N\to \infty }\frac {\big |\big \{(n_1,n_2): n_1 + n_2 = N, (n_1,n_2)\in A^2\big \}\big |}{N^{\varepsilon }} = 0.\end{equation*}
\begin{equation*}\lim _{N\to \infty }\frac {\big |\big \{(n_1,n_2): n_1 + n_2 = N, (n_1,n_2)\in A^2\big \}\big |}{N^{\varepsilon }} = 0.\end{equation*}This answers a question of Erdős.




Response to letter to editor from Rattanapitoon, N. & Rattanapitoon, S
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 12 September 2025, e100
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cyber breach risk modeling for insurance: capturing temporal and cross-group dependence
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 12 September 2025, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Letter to the Editor: “Modelling the risk of foodborne transmission of Toxocara spp. to humans” by Healy et al. (2025)
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 12 September 2025, e101
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Modeling the influences of climate conditions on measles transmission in China
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 11 September 2025, e110
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Conditioning Bienaymé–Galton–Watson trees to have large sub-populations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 10 September 2025, pp. 345-386
- Print publication:
- March 2026
-
- Article
- Export citation
Quasi-stationary distributions for subcritical branching Markov chains
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 10 September 2025, pp. 425-471
- Print publication:
- March 2026
-
- Article
- Export citation
-
Consider a subcritical branching Markov chain. Let
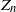 $Z_n$ denote the counting measure of particles of generation n. Under some conditions, we give a probabilistic proof for the existence of the Yaglom limit of
$Z_n$ denote the counting measure of particles of generation n. Under some conditions, we give a probabilistic proof for the existence of the Yaglom limit of  $(Z_n)_{n\in\mathbb{N}}$ by the moment method, based on the spinal decomposition and the many-to-few formula. As a result, we give explicit integral representations of all quasi-stationary distributions of
$(Z_n)_{n\in\mathbb{N}}$ by the moment method, based on the spinal decomposition and the many-to-few formula. As a result, we give explicit integral representations of all quasi-stationary distributions of  $(Z_n)_{n\in\mathbb{N}}$, whose proofs are direct and probabilistic, and do not rely on Martin boundary theory.
$(Z_n)_{n\in\mathbb{N}}$, whose proofs are direct and probabilistic, and do not rely on Martin boundary theory.


Large and moderate deviations in Poisson navigations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 10 September 2025, pp. 387-424
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Well-posedness and averaging principle for non-Gaussian McKean–Vlasov stochastic differential equations with locally Lipschitz coefficients
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 09 September 2025, pp. 301-344
- Print publication:
- March 2026
-
- Article
- Export citation
Asymptotic mixed normality of maximum-likelihood estimator for Ewens–Pitman partition
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 09 September 2025, pp. 214-234
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper investigates the asymptotic properties of parameter estimation for the Ewens–Pitman partition with parameters
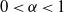 $0\lt\alpha\lt1$ and
$0\lt\alpha\lt1$ and  $\theta\gt-\alpha$. Specifically, we show that the maximum-likelihood estimator (MLE) of
$\theta\gt-\alpha$. Specifically, we show that the maximum-likelihood estimator (MLE) of  $\alpha$ is
$\alpha$ is  $n^{\alpha/2}$-consistent and converges to a variance mixture of normal distributions, where the variance is governed by the Mittag-Leffler distribution. Moreover, we show that a proper normalization involving a random statistic eliminates the randomness in the variance. Building on this result, we construct an approximate confidence interval for
$n^{\alpha/2}$-consistent and converges to a variance mixture of normal distributions, where the variance is governed by the Mittag-Leffler distribution. Moreover, we show that a proper normalization involving a random statistic eliminates the randomness in the variance. Building on this result, we construct an approximate confidence interval for  $\alpha$. Our proof relies on a stable martingale central limit theorem, which is of independent interest.
$\alpha$. Our proof relies on a stable martingale central limit theorem, which is of independent interest.
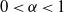




The distance on the slightly supercritical random series–parallel graph
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 09 September 2025, pp. 80-121
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the random series–parallel graph introduced by Hambly and Jordan (2004 Adv. Appl. Probab. 36, 824–838), which is a hierarchical graph with a parameter
 $p\in [0, \, 1]$. The graph is built recursively: at each step, every edge in the graph is either replaced with probability p by a series of two edges, or with probability
$p\in [0, \, 1]$. The graph is built recursively: at each step, every edge in the graph is either replaced with probability p by a series of two edges, or with probability 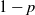 $1-p$ by two parallel edges, and the replacements are independent of each other and of everything up to then. At the nth step of the recursive procedure, the distance between the extremal points on the graph is denoted by
$1-p$ by two parallel edges, and the replacements are independent of each other and of everything up to then. At the nth step of the recursive procedure, the distance between the extremal points on the graph is denoted by  $D_n (p)$. It is known that
$D_n (p)$. It is known that  $D_n(p)$ possesses a phase transition at
$D_n(p)$ possesses a phase transition at  $p=p_c \;:\!=\;\frac{1}{2}$; more precisely,
$p=p_c \;:\!=\;\frac{1}{2}$; more precisely,  $\frac{1}{n}\log {{\mathbb{E}}}[D_n(p)] \to \alpha(p)$ when
$\frac{1}{n}\log {{\mathbb{E}}}[D_n(p)] \to \alpha(p)$ when  $n \to \infty$, with
$n \to \infty$, with  $\alpha(p) >0$ for
$\alpha(p) >0$ for  $p>p_c$ and
$p>p_c$ and  $\alpha(p)=0$ for
$\alpha(p)=0$ for  $p\le p_c$. We study the exponent
$p\le p_c$. We study the exponent  $\alpha(p)$ in the slightly supercritical regime
$\alpha(p)$ in the slightly supercritical regime 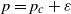 $p=p_c+\varepsilon$. Our main result says that as
$p=p_c+\varepsilon$. Our main result says that as  $\varepsilon\to 0^+$,
$\varepsilon\to 0^+$,  $\alpha(p_c+\varepsilon)$ behaves like
$\alpha(p_c+\varepsilon)$ behaves like 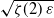 $\sqrt{\zeta(2) \, \varepsilon}$, where
$\sqrt{\zeta(2) \, \varepsilon}$, where  $\zeta(2) \;:\!=\; \frac{\pi^2}{6}$.
$\zeta(2) \;:\!=\; \frac{\pi^2}{6}$.











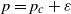


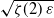

On orderings of vectors of order statistics and sample ranges from heterogeneous bivariate Pareto variables
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 09 September 2025, pp. 182-197
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study ordering properties of vectors of order statistics and sample ranges arising from bivariate Pareto random variables. Assume that
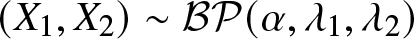 $(X_1,X_2)\sim\mathcal{BP}(\alpha,\lambda_1,\lambda_2)$ and
$(X_1,X_2)\sim\mathcal{BP}(\alpha,\lambda_1,\lambda_2)$ and 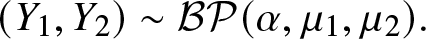 $(Y_1,Y_2)\sim\mathcal{BP}(\alpha,\mu_1,\mu_2).$ We then show that
$(Y_1,Y_2)\sim\mathcal{BP}(\alpha,\mu_1,\mu_2).$ We then show that 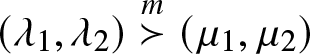 $(\lambda_1,\lambda_2)\stackrel{m}{\succ}(\mu_1,\mu_2)$ implies
$(\lambda_1,\lambda_2)\stackrel{m}{\succ}(\mu_1,\mu_2)$ implies 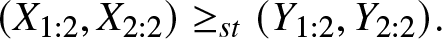 $(X_{1:2},X_{2:2})\ge_{st}(Y_{1:2},Y_{2:2}).$ Under bivariate Pareto distributions, we prove that the reciprocal majorization order between the two vectors of parameters is equivalent to the hazard rate and usual stochastic orders between sample ranges. We also show that the weak majorization order between two vectors of parameters is equivalent to the likelihood ratio and reversed hazard rate orders between sample ranges.
$(X_{1:2},X_{2:2})\ge_{st}(Y_{1:2},Y_{2:2}).$ Under bivariate Pareto distributions, we prove that the reciprocal majorization order between the two vectors of parameters is equivalent to the hazard rate and usual stochastic orders between sample ranges. We also show that the weak majorization order between two vectors of parameters is equivalent to the likelihood ratio and reversed hazard rate orders between sample ranges.