Volume 2 - 2026
Latest volume of Computational Humanities Research
Contents
Research Article
Cognitive stylometry: A computational study of defamiliarization in modern Chinese
- Part of:
-
- Published online by Cambridge University Press:
- 05 December 2025, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Relational arcs as narrative structure: Dynamics, distribution and diachronic change in fiction
- Part of:
-
- Published online by Cambridge University Press:
- 19 December 2025, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fine-tuning large-language models for early modern Dutch translation
-
- Published online by Cambridge University Press:
- 30 January 2026, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The narrative function of ending speech and hermeneutic complexity in Aesopic fables: A computational analysis of 600-fable corpus
-
- Published online by Cambridge University Press:
- 11 February 2026, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From shots to narratives: Expanding multimodal approaches to filmic storytelling in the digital humanities
-
- Published online by Cambridge University Press:
- 16 February 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Erratum
Undate: humanistic dates for computation – ERRATUM
-
- Published online by Cambridge University Press:
- 26 March 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research Article
Toward an ontological representation of fictional characters
-
- Published online by Cambridge University Press:
- 20 February 2026, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Characters are central to narrative theory but remain under-specified in computational work, where they are often reduced to clusters of words or vectors. We propose an operationalizable ontology of characterization that bridges narratological theory and NLP. From BERT-based clustering of character descriptions, we derive 17 classes of attributes (actions, emotions, traits, relations, possessions, etc.), validated through manual annotation (
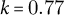 $k = 0.77$) and automatic classification (64% accuracy vs. 12% baseline). Applied to character similarity tasks for French fiction, our framework outperforms existing models. By aligning narratological insights with computational methods, we move toward a representation of fictional characters as structured, comparable entities for large-scale literary analysis.
$k = 0.77$) and automatic classification (64% accuracy vs. 12% baseline). Applied to character similarity tasks for French fiction, our framework outperforms existing models. By aligning narratological insights with computational methods, we move toward a representation of fictional characters as structured, comparable entities for large-scale literary analysis.
McK: Ontology for mapping semantic conflict in plot summary
-
- Published online by Cambridge University Press:
- 24 March 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Operationalizing narrativized change in the political talk for computational recognition
-
- Published online by Cambridge University Press:
- 24 March 2026, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Decoding the conqueror’s gaze: A computational approach to Ennio Flaiano’s (post)colonialism
-
- Published online by Cambridge University Press:
- 24 March 2026, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Software Paper
Introducing reproducible navigation of a web archive: SolrWayback navigation tracker
-
- Published online by Cambridge University Press:
- 13 April 2026, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research Article
A language modeling approach to identifying Russian information confrontation in Colombia
- Part of:
-
- Published online by Cambridge University Press:
- 04 June 2026, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This study integrates multilingual text analytics with time-series modeling to examine how geopolitical narratives emerging around the 2022 Russia–Ukraine conflict align across Russian and Colombian media, drawing on a corpus spanning 2013–2023 that also encompasses the 2014 conflict period. Drawing on a corpus of more than 38,000 Spanish- and Russian-language news articles (2013–2023), we employ a six-stage pipeline combining multilingual NER, document-level sentiment scoring, e5-large-instruct embeddings, BERTopic clustering, and a semi-automated human-LLM labeling workflow. Narrative salience and tone were aggregated to weekly, log-normalized series and analyzed using linear regression and Granger causality tests (lags 1–4 weeks), providing a descriptive view of temporal coupling rather than evidence of direct causal influence.
The period surrounding the 2022 invasion produced the clearest and most coherent patterns. Across four macro-narratives (Security & Conflict, Diplomacy, Economy, and Politics & Society), Russian and Colombian coverage exhibited sequential alignment in which shifts in narrative volume were often followed by shifts in evaluative tone. Thirty-two of forty-four target–topic pairs displayed significant lag structures prior to false-discovery correction ($p<0.05$
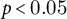 ), with 25 surviving Benjamini–Hochberg adjustment. Categories with lower geopolitical salience (Technology, Health, and Off-topic) displayed less consistent temporal coupling, though this contrast is offered as descriptive context rather than a formal control. While these results do not imply coordinated messaging, they indicate recurring forms of narrative mimicry, understood here as patterned convergence in framing and sentiment across media ecosystems.
), with 25 surviving Benjamini–Hochberg adjustment. Categories with lower geopolitical salience (Technology, Health, and Off-topic) displayed less consistent temporal coupling, though this contrast is offered as descriptive context rather than a formal control. While these results do not imply coordinated messaging, they indicate recurring forms of narrative mimicry, understood here as patterned convergence in framing and sentiment across media ecosystems.By demonstrating how transformer-based semantic representations can be integrated with human-in-the-loop interpretation and classical time-series analysis, this study contributes a reproducible workflow for tracing narrative trajectories at scale. The approach provides a methodological foundation for examining how geopolitical frames circulate, mutate, and align across linguistic and regional boundaries, offering new possibilities for computational humanities research on transnational discourse.
Messy data, low-resource languages, and LLMs: Narrative analysis of pre-modern Slavic Lives of Saints
-
- Published online by Cambridge University Press:
- 12 May 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Misaligning stories: Narrative unreliability, double noise, and feedback ethics in clinical AI
-
- Published online by Cambridge University Press:
- 01 June 2026, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation