


Non-technical Summary
Paleontologists have long used repeated observations from fossil species to document and understand patterns of trait evolution. Here we describe a flexible framework for modeling such data called linear state space models. After summarizing this approach and its properties, we apply it to a classic dataset of trait evolution in species of diatom, a kind of unicellular algae. A set of models were fit to these diatom data using the state space approach, the best supported of which involved a novel model in which the focal trait tracks variations in solar insolation over time. Overall, state space models offer a useful framework for paleontologists to robustly develop, fit, and evaluate models of trait evolution.
Introduction
The project of documenting and explaining historical patterns of evolutionary change has had enduring significance since George Gaylord Simpson introduced the ideas of evolutionary tempo and mode as a tool for bridging observation and theory across micro- and macroevolutionary timescales (Simpson Reference Simpson1944). Fossil trait series provide a sequence of phenotypic measurements drawn from multiple organisms in the same lineage over a period of time, typically on the scale of tens to hundreds of thousands of years. In contrast to comparative methods, which rely on measurements of different species, fossil trait series document historical patterns of evolutionary change in a single species over much longer durations than we can access in the present. This makes fossil trait series a uniquely valuable data source for addressing fundamental questions in evolutionary biology occurring at those scales, including why evolutionary rates of change appear to show a robust scaling with time (Harmon et al. Reference Harmon, Pennell, Henao-Diaz, Rolland, Sipley and Uyeda2021) and whether evolutionary divergence is driven by the gradual accumulation of small changes or short, rapid bursts of change that punctuate long periods of stasis (Hunt et al. Reference Hunt, Hopkins and Lidgard2015). In addition, paleobiologists have long looked at these data for signatures of other evolutionary and ecological processes, seeking to gain insights into processes of adaptation (Voje Reference Voje2020; Kearns et al. Reference Kearns, Bohaty, Edgar, Nogué and Ezard2021), extinction (Brombacher et al. Reference Brombacher, Wilson, Bailey and Ezard2017, Reference Brombacher, Wilson, Bailey and Ezard2018), stasis (Antell et al. Reference Antell, Fenton, Valdes and Saupe2021), and parallel evolution (Stuart et al. Reference Stuart, Travis and Bell2020).
Because evolution is stochastic and involves the interaction of multiple processes such as selection and drift, statistical modeling is essential to reliably estimate evolutionary rates and classify fossil trait series into biologically significant patterns or modes of change (Hunt Reference Hunt2012; Gingerich Reference Gingerich2019). In addition, the sample sizes of fossil lineage data are often small relative to the potential complexity of the system, so it is especially important to make effective use of the available information. The appropriate interpretation of evolutionary rates in a system, for example, is sensitive to the underlying mode of change: for a lineage evolving according to classical Brownian motion, we can understand its rate of change as the variance of random fluctuations it undergoes between points of time, but for a lineage exhibiting a linear directional trend in addition to Brownian motion, we also need to incorporate the magnitude of that linear tendency (Hunt Reference Hunt2012). Numerical estimation of evolutionary rates is also sensitive to model choice, and using an inadequate model for the data can generate scaling artifacts in the magnitude of rates in relation to the absolute time duration of the trait series (Hunt Reference Hunt2012; Gingerich Reference Gingerich2019; Harmon et al. Reference Harmon, Pennell, Henao-Diaz, Rolland, Sipley and Uyeda2021).
In this paper, we present some practical tools and background theory for the use of linear state space models, also called dynamic linear models, in the analysis of phenotypic time series from fossil lineages. This approach provides some key advances over previous methodological approaches. First, state space models, which apply to time series with observations at discrete time points, are grounded in continuous-time models, which are important for knowing how to handle time-varying parameters when there are uneven time steps between observations. Second, the state space framework allows for the ready evaluation of exogenous environmental covariates. Third, the framework provides access to residuals for the predicted and observed values at each time point, a powerful model diagnostic tool that is in standard use across other scientific disciplines. We illustrate the value of these residuals to propose a new interpretation of a classic dataset of diatom evolution in Yellowstone Lake (Theriot et al. Reference Theriot, Fritz, Whitlock and Conley2006). We also present some simulation studies emphasizing the quality of parameter estimation and model selection within this framework in comparison to previous frameworks for estimation.
We focus on univariate evolutionary models from a single species, because this foundation is essential for numerically efficient and stable parameter estimation as paleontologists start to increasingly take advantage of high-throughput specimen processing, including machine-learning methods for image segmentation and trait extraction (Porto and Voje Reference Porto and Voje2020; Goswami and Clavel Reference Goswami and Clavel2024; He et al. Reference He, Mulqueeney, Watt, Salili-James, Barber, Camaiti and Hunt2024). However, the modeling framework we develop here is readily generalized to analyzing multivariate measurements from variable numbers of individual specimens at each time point. This approach also demonstrates the broad relevance of stochastic integral models to analyzing fossil lineage datasets, building on prior work by Reitan et al. (Reference Reitan, Schweder and Henderiks2012), and is complementary to stochastic integral models for species richness (Hannisdal and Liow Reference Hannisdal and Liow2018; Reitan and Liow Reference Reitan and Liow2019) and comparative phylogenetic datasets (Blomberg et al. Reference Blomberg, Rathnayake and Moreau2020; Turley Reference Turley2020).
Methods
In this section, we briefly present the definition of a linear state space model, sometimes known as a dynamic linear model. We introduce the general structure of the model along with some adaptations and quantities that this formulation facilitates. Then, we show how observing an Ornstein-Uhlenbeck (OU) process at discrete time points can be formulated as a linear state space model. In particular, we make clear the relationship between the continuously defined model and the discretely sampled observations. We also discuss the relationship of other familiar models, such as an unbiased random walk (RW), random walk with a directional trend (DT), and stasis (ST) to the linear state space models in Appendix 2.
Definition of a Linear State Space Model
The linear state space model consists of two recursively defined equations: the system equation and the observation equation. We will focus on the unidimensional case for each equation, although multivariate extension is straightforward. The system equation is a linear stochastic equation describing the underlying dynamics of a phenomenon, such as the change of the level of a trait measurement for a population at a given time. The system equation can be written as
 $$ {X}_t=\Phi {X}_{t-1}+{W}_t $$
$$ {X}_t=\Phi {X}_{t-1}+{W}_t $$
for
 $ t=1,\dots, T $
, where
$ t=1,\dots, T $
, where
 $ {W}_1,\dots, {W}_T $
are a sequence of independent and identically distributed normal random variables with zero-mean and variance
$ {W}_1,\dots, {W}_T $
are a sequence of independent and identically distributed normal random variables with zero-mean and variance
 $ {\sigma}_W^2 $
. This is an autoregressive model with coefficient
$ {\sigma}_W^2 $
. This is an autoregressive model with coefficient
 $ \Phi $
. The model is called autoregressive because the sequence could be viewed as having the current time observation depend on the previous observation as a covariate. The observation equation is then defined as
$ \Phi $
. The model is called autoregressive because the sequence could be viewed as having the current time observation depend on the previous observation as a covariate. The observation equation is then defined as
 $$ {Y}_t={AX}_t+{V}_t $$
$$ {Y}_t={AX}_t+{V}_t $$
for
 $ t=1,\dots, T $
, where
$ t=1,\dots, T $
, where
 $ {V}_1,\dots, {V}_T $
is a sequence of independent and identically distributed normal random variables with zero-mean and variance
$ {V}_1,\dots, {V}_T $
is a sequence of independent and identically distributed normal random variables with zero-mean and variance
 $ {\sigma}_V^2 $
, which is also independent of the sequence
$ {\sigma}_V^2 $
, which is also independent of the sequence
 $ {W}_1,\dots, {W}_T $
. This sequence of
$ {W}_1,\dots, {W}_T $
. This sequence of
 $ {Y}_1,\dots {Y}_T $
will model the observed data and is a linear transformation by
$ {Y}_1,\dots {Y}_T $
will model the observed data and is a linear transformation by
 $ A $
of the system process,
$ A $
of the system process,
 $ {X}_t $
, plus an additional observation error,
$ {X}_t $
, plus an additional observation error,
 $ {V}_t $
. Note that the notation here follows the book by Shumway and Stoffer, where detailed calculations associated with this model can be found (Shumway and Stoffer Reference Shumway and Stoffer2000).
$ {V}_t $
. Note that the notation here follows the book by Shumway and Stoffer, where detailed calculations associated with this model can be found (Shumway and Stoffer Reference Shumway and Stoffer2000).
In the subsection that follows and in Appendix 1, we will show how a number of familiar trait evolution models fit into this framework, especially when a few features are added. This linear state space model is the framework for calculating model likelihoods using the renowned Kalman filter. The Kalman filter recursively calculates the conditional distribution of
 $ {X}_t $
given observations
$ {X}_t $
given observations
 $ {Y}_1,\dots, {Y}_t $
; this means that if you have the Kalman filter calculated up to time
$ {Y}_1,\dots, {Y}_t $
; this means that if you have the Kalman filter calculated up to time
 $ t-1 $
and receive a new observation
$ t-1 $
and receive a new observation
 $ {Y}_t $
, then the conditional distribution of
$ {Y}_t $
, then the conditional distribution of
 $ {X}_t $
given the data up to time
$ {X}_t $
given the data up to time
 $ t $
can be calculated without passing back through all of the previous data. A by-product of calculating the Kalman filter is that the likelihood function can be calculated with one pass through the data, so that the computational efficiency of this calculation is of order
$ t $
can be calculated without passing back through all of the previous data. A by-product of calculating the Kalman filter is that the likelihood function can be calculated with one pass through the data, so that the computational efficiency of this calculation is of order
 $ T $
. The likelihood function for a linear state space model can also be calculated using a multivariate normal distribution of size
$ T $
. The likelihood function for a linear state space model can also be calculated using a multivariate normal distribution of size
 $ T $
, which has been the standard approach in previous paleontological research (Hunt et al. Reference Hunt, Bell and Travis2008; Voje Reference Voje2020); however, that approach requires calculating the inverse of a
$ T $
, which has been the standard approach in previous paleontological research (Hunt et al. Reference Hunt, Bell and Travis2008; Voje Reference Voje2020); however, that approach requires calculating the inverse of a
 $ T\times T $
matrix. Hence there can be a significant speed up and improved stability using the Kalman filter algorithm to calculate the relevant likelihood function, especially for time series with many samples.
$ T\times T $
matrix. Hence there can be a significant speed up and improved stability using the Kalman filter algorithm to calculate the relevant likelihood function, especially for time series with many samples.
The Kalman filter approach also makes prediction relatively straightforward. The filter calculates the conditional mean and variance of
 $ {X}_t $
given
$ {X}_t $
given
 $ {Y}_1,\dots, {Y}_t $
, giving us access to a “best guess” for
$ {Y}_1,\dots, {Y}_t $
, giving us access to a “best guess” for
 $ {X}_t $
with the data up to that time. This also allows us to predict, that is, to find the conditional mean and variance, of the next observation
$ {X}_t $
with the data up to that time. This also allows us to predict, that is, to find the conditional mean and variance, of the next observation
 $ {Y}_{t+1} $
given the observations up to time
$ {Y}_{t+1} $
given the observations up to time
 $ t $
(i.e.
$ t $
(i.e.
 $ {Y}_1,\dots {Y}_t\Big) $
, which is known as the one-step ahead predictor of the data and also allows us to construct residuals for our data after having fit it to a specific state space model. Again, using the notation of Shumway and Stoffer, the standardized residuals would be defined as
$ {Y}_1,\dots {Y}_t\Big) $
, which is known as the one-step ahead predictor of the data and also allows us to construct residuals for our data after having fit it to a specific state space model. Again, using the notation of Shumway and Stoffer, the standardized residuals would be defined as
 $$ \frac{Y_{t+1}-{AX}_{t+1}^t}{\sqrt{\Sigma_{t+1}}} $$
$$ \frac{Y_{t+1}-{AX}_{t+1}^t}{\sqrt{\Sigma_{t+1}}} $$
for
 $ t=1,\dots, T-1 $
, where
$ t=1,\dots, T-1 $
, where
 $ {\Sigma}_{t+1} $
is the conditional variance of
$ {\Sigma}_{t+1} $
is the conditional variance of
 $ {Y}_{t+1} $
given
$ {Y}_{t+1} $
given
 $ {Y}_1,\dots, {Y}_t $
, which is calculated as part of the Kalman filter algorithm. Residuals in a time-series context are an important tool for discerning the quality of fit of a model, in a manner similar to their use in regression analysis. It is a way to “approximate” the sequence
$ {Y}_1,\dots, {Y}_t $
, which is calculated as part of the Kalman filter algorithm. Residuals in a time-series context are an important tool for discerning the quality of fit of a model, in a manner similar to their use in regression analysis. It is a way to “approximate” the sequence
 $ {V}_t $
, and we therefore expect them to be approximately independent and identically distributed.
$ {V}_t $
, and we therefore expect them to be approximately independent and identically distributed.
In addition to facilitating likelihood function calculations and predictions of both the system equation model and future observations, the linear state space model facilitates regression with exogenous variables, which is especially important when considering the effects of environmental variables on trait dynamics. These can enter either through the system equation or the observation equations. In addition, the parameters defining the linear state space model can be time-varying. These modifications give
 $$ {X}_t={\Phi}_t{X}_{t-1}+\Upsilon {u}_t+{W}_t $$
$$ {X}_t={\Phi}_t{X}_{t-1}+\Upsilon {u}_t+{W}_t $$
and
 $$ {Y}_t={A}_t{X}_t+\Gamma {u}_t+{V}_t $$
$$ {Y}_t={A}_t{X}_t+\Gamma {u}_t+{V}_t $$
where
 $ {u}_t $
is an
$ {u}_t $
is an
 $ r\times 1 $
column vector of exogenous variables, typically what we think of as covariates, for each
$ r\times 1 $
column vector of exogenous variables, typically what we think of as covariates, for each
 $ t $
, and
$ t $
, and
 $ \Upsilon $
and
$ \Upsilon $
and
 $ \Gamma $
are the coefficients that convert changes in the input variables into changes in
$ \Gamma $
are the coefficients that convert changes in the input variables into changes in
 $ {X}_t $
and
$ {X}_t $
and
 $ {Y}_t $
. In this context, we can still use the Kalman filter to calculate the likelihood and to create predictions, and thus residuals, to evaluate model performance. Visually examining the residuals is a useful complement to the formal model misspecification tests for common fossil lineage models that were introduced by Voje (Reference Voje2018).
$ {Y}_t $
. In this context, we can still use the Kalman filter to calculate the likelihood and to create predictions, and thus residuals, to evaluate model performance. Visually examining the residuals is a useful complement to the formal model misspecification tests for common fossil lineage models that were introduced by Voje (Reference Voje2018).
Unbiased Random Walk as a Linear State Space Model
Many commonly used trait evolution models can be represented in this state space framework. Perhaps the simplest case is that of an RW, which we develop here as an example. Under this model, the trait value at one time step (
 $ {X}_t $
) is equal to the value at the previous time step (
$ {X}_t $
) is equal to the value at the previous time step (
 $ {X}_{t-1} $
), plus an evolutionary perturbation (
$ {X}_{t-1} $
), plus an evolutionary perturbation (
 $ {W}_t $
). The autoregressive coefficient is unity (
$ {W}_t $
). The autoregressive coefficient is unity (
 $ \Phi =1 $
), and the variance of the
$ \Phi =1 $
), and the variance of the
 $ {W}_t $
is usually called the step variance in paleontology. The state equation represents the true trait mean of the population at each time step. Because sample sizes are finite, however, we can never know the true means of our samples. The calculated trait means that we observe,
$ {W}_t $
is usually called the step variance in paleontology. The state equation represents the true trait mean of the population at each time step. Because sample sizes are finite, however, we can never know the true means of our samples. The calculated trait means that we observe,
 $ {Y}_t $
, reflects the true population mean (
$ {Y}_t $
, reflects the true population mean (
 $ {X}_t $
), plus sampling noise (
$ {X}_t $
), plus sampling noise (
 $ {V}_t $
). In most paleontological cases, our measurements of traits are noisy but unbiased, and so
$ {V}_t $
). In most paleontological cases, our measurements of traits are noisy but unbiased, and so
 $ A=1 $
. Biased sampling from, for example, size-selective preservation, could be accounted for in principle by appropriate values of
$ A=1 $
. Biased sampling from, for example, size-selective preservation, could be accounted for in principle by appropriate values of
 $ A $
, although the nature of bias would need to be independently estimated. For trait means, the observational variance of
$ A $
, although the nature of bias would need to be independently estimated. For trait means, the observational variance of
 $ {V}_t $
for each sample will be the within-sample trait variance divided by the number of individuals measured in that sample.
$ {V}_t $
for each sample will be the within-sample trait variance divided by the number of individuals measured in that sample.
Ornstein-Uhlenbeck as a Linear State Space Model
State space models are applied to discretely observed time series, and so an important step in analysis is to understand how continuous-time evolutionary models manifest in discrete time. This section presents this topic for OU models, with additional models considered in Appendix 1. Readers interested mostly in practical application of state space models may wish to proceed directly to the next section.
The OU process is used in evolutionary studies to model adaptation (Hansen Reference Hansen1997; Hunt et al. Reference Hunt, Bell and Travis2008). It is often defined by its stochastic differential equation (SDE) formulation.
 $$ dX(t)=-\alpha X(t) dt+\sigma dW(t) $$
$$ dX(t)=-\alpha X(t) dt+\sigma dW(t) $$
This type of differential is a shorthand to define an integral equation. Such an equation is defined as a solution to sequences of difference equations:
 $$ {\displaystyle \begin{array}{c}\hskip-11em X\left(n\Delta \right)-X\left(\left(n-1\right)\Delta \right)=-\alpha X\left(\left(n-1\right)\Delta \right)\Delta \\ {}\hskip12em +\hskip.4em \sigma W\left(n\Delta \right)-W\left(\left(n-1\right)\Delta \right),\end{array}} $$
$$ {\displaystyle \begin{array}{c}\hskip-11em X\left(n\Delta \right)-X\left(\left(n-1\right)\Delta \right)=-\alpha X\left(\left(n-1\right)\Delta \right)\Delta \\ {}\hskip12em +\hskip.4em \sigma W\left(n\Delta \right)-W\left(\left(n-1\right)\Delta \right),\end{array}} $$
as
 $ \Delta $
goes to zero and
$ \Delta $
goes to zero and
 $ n\Delta $
converges to some terminal time
$ n\Delta $
converges to some terminal time
 $ T $
and with
$ T $
and with
 $ X(0) $
defining an initial value for the equations. (This sequence is on an evenly spaced grid, which is not necessary in general as long as the grid spacing distance shrinks to zero.) The OU process has a solution (Oksendal Reference Oksendal2013) in the form of a stochastic integral with deterministic integrand,
$ X(0) $
defining an initial value for the equations. (This sequence is on an evenly spaced grid, which is not necessary in general as long as the grid spacing distance shrinks to zero.) The OU process has a solution (Oksendal Reference Oksendal2013) in the form of a stochastic integral with deterministic integrand,
 $$ X(t)={e}^{-\alpha t}X(0)+{\int}_0^t{e}^{-\alpha \left(t-s\right)}\sigma dW(s) $$
$$ X(t)={e}^{-\alpha t}X(0)+{\int}_0^t{e}^{-\alpha \left(t-s\right)}\sigma dW(s) $$
The definition of these SDEs as a limit of solutions to certain difference equations points to one possible discretization. Namely, we could rearrange the difference equation to arrive at
 $$ X\left(n\Delta \right)=\left(1-\alpha \Delta \right)X\left(\left(n-1\right)\Delta \right)+\sigma W\left(n\Delta \right)-W\left(\left(n-1\right)\Delta \right) $$
$$ X\left(n\Delta \right)=\left(1-\alpha \Delta \right)X\left(\left(n-1\right)\Delta \right)+\sigma W\left(n\Delta \right)-W\left(\left(n-1\right)\Delta \right) $$
but this is only an approximate solution that accurately represents the model definition when
 $ \Delta $
is small. However, if we take the integral solution of equation (6) and manipulate it appropriately, we arrive at
$ \Delta $
is small. However, if we take the integral solution of equation (6) and manipulate it appropriately, we arrive at
 $$ {X}_n={e}^{-\alpha \Delta}{X}_{n-1}+{\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{-\alpha \left(n\Delta -s\right)}\sigma dW(s) $$
$$ {X}_n={e}^{-\alpha \Delta}{X}_{n-1}+{\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{-\alpha \left(n\Delta -s\right)}\sigma dW(s) $$
We can use Ito’s isometry to calculate the variance of the last term, which is Gaussian and has a zero mean. The variance is then
 $$ Var\left({\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{-\alpha \left(n\Delta -s\right)}\sigma dW(s)\right)={\sigma}^2{e}^{-2\alpha n\Delta}{\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{2\alpha s} ds $$
$$ Var\left({\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{-\alpha \left(n\Delta -s\right)}\sigma dW(s)\right)={\sigma}^2{e}^{-2\alpha n\Delta}{\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{2\alpha s} ds $$
We solve the integral to arrive at the variance of the last term
 $$ {\sigma}_{\Delta}^2=\frac{\sigma^2}{2\alpha}\left(1-{e}^{-2\alpha \Delta}\right) $$
$$ {\sigma}_{\Delta}^2=\frac{\sigma^2}{2\alpha}\left(1-{e}^{-2\alpha \Delta}\right) $$
Note that when
 $ \Delta $
is small, then a Taylor approximation will verify that this expression is approximately equal to
$ \Delta $
is small, then a Taylor approximation will verify that this expression is approximately equal to
 $ {\sigma}^2\Delta $
corresponding to equation (7). So, we can express this discretization as
$ {\sigma}^2\Delta $
corresponding to equation (7). So, we can express this discretization as
 $$ {X}_n={e}^{-\alpha \Delta}{X}_{n-1}+{\sigma}_{\Delta}{\varepsilon}_n $$
$$ {X}_n={e}^{-\alpha \Delta}{X}_{n-1}+{\sigma}_{\Delta}{\varepsilon}_n $$
where
 $ {\varepsilon}_n $
is a sequence of independent standard normal random variables.
$ {\varepsilon}_n $
is a sequence of independent standard normal random variables.
The OU model will eventually settle around zero regardless of the initial condition. We can modify this part of the model for the OU process to be centered around another constant,
 $ \theta $
. The exact discrete version would be
$ \theta $
. The exact discrete version would be
 $$ {X}_n=c+{e}^{-\alpha \Delta}\left({X}_{n-1}-\theta \right)+{\sigma}_{\Delta}{\varepsilon}_n $$
$$ {X}_n=c+{e}^{-\alpha \Delta}\left({X}_{n-1}-\theta \right)+{\sigma}_{\Delta}{\varepsilon}_n $$
This formulation allows for one way to introduce exogenous variables by replacing
 $ \theta $
with a linear combination of covariates, as demonstrated in “Application: Stephanodiscus yellowstonensis Trait Evolution.”.
$ \theta $
with a linear combination of covariates, as demonstrated in “Application: Stephanodiscus yellowstonensis Trait Evolution.”.
Model Estimation and Selection Simulations
We used simulations to validate model fitting in the state space framework using the Kalman filter compared to prior work. We also explored parameter estimation and model selection performance in the state space framework. Details are provided in Appendix 2, but in general, performance was as expected for likelihood-based methods. Corrected Akaike information criterion (AICc) scores generally favored the correct, generating models, increasingly so with increasing sequence length. Parameter estimates were unbiased, or nearly so, although convergence could depend on two inherent observational timescales in trait series: the time step between observed samples (
 $ \Delta $
in equation 7, for example) and the total duration between the first and last observations. Parameter convergence may therefore depend on how increasing the sample size alters these timescales. For example, subdividing a fixed interval of time with more observations does not lead the linear trend parameter,
$ \Delta $
in equation 7, for example) and the total duration between the first and last observations. Parameter convergence may therefore depend on how increasing the sample size alters these timescales. For example, subdividing a fixed interval of time with more observations does not lead the linear trend parameter,
 $ \mu $
, to converge asymptotically in the DT model. In contrast, smaller time steps are valuable for estimating parameters of the OU and decelerating evolution models.
$ \mu $
, to converge asymptotically in the DT model. In contrast, smaller time steps are valuable for estimating parameters of the OU and decelerating evolution models.
Application: Stephanodiscus yellowstonensis Trait Evolution
To illustrate the linear state space framework, we re-analyzed the Stephanodiscus yellowstonensis fossil trait series published in Voje (Reference Voje2020), originally created by Theriot and colleagues (Reference Theriot, Fritz, Whitlock and Conley2006), using the discretized models described in “Methods” and implemented in the state space framework. Script and data files to perform this analysis have been uploaded to Zenodo (see “Data Availability Statement”).
Stephanodiscus yellowstonensis is a species of diatom endemic to Yellowstone Lake, Wyoming, USA, and likely descended from the preexisting species S. niagarae, which is still extant throughout the region (Theriot et al. Reference Theriot, Fritz, Whitlock and Conley2006). The fossil trait series is derived from 63 samples from a sediment core collected from the lake’s central basin, and it covers approximately 14,000 years ago until the present. For each sample, Theriot and co-workers measured 50 individuals, occasionally fewer if this number of specimens was not available. They measured three traits on each individual: valve diameter, the number of costae per valve, and the number of spines per valve. All three traits show a relatively rapid increase in values from about 12,000 to 10,000 years ago, with a slower and fluctuating decrease thereafter. To illustrate the model-fitting methods, we focus on just one variable, spine count (Fig. 1). As noted by Voje (Reference Voje2020), all three traits are considered to be ecologically important for diatoms; valve spines, in particular, may enhance nutrient uptake and photosynthetic rate by affecting how diatoms sink through the water column. Spine counts were log-transformed before analysis, because we consider a proportional scale to be more appropriate for the evolution of this trait. This transformation also has the effect of removing a strong correlation between the mean and variance among samples (
 $ r=0.70 $
, P < 10−4 for untransformed spine counts,
$ r=0.70 $
, P < 10−4 for untransformed spine counts,
 $ r=0.04 $
,
$ r=0.04 $
,
 $ P=0.77 $
after log-transformation).
$ P=0.77 $
after log-transformation).

Figure 1. Evolutionary time series of log spine counts for Stephanodiscus yellowstonensis. Open circles and vertical bars show mean values ±1 SE on those means. The red line is the model-predicted trajectory of the fitness optimum for the best-supported model (see text). Age is in years before present day.
Theriot et al. (Reference Theriot, Fritz, Whitlock and Conley2006) posit that morphological changes in the S. yellowstonensis lineage track environmental changes, and these authors synthesize the available records of regional change through the study interval. Here, we quantitatively analyze two of these records. The first is the proportion of the dominant pollen type, attributable to Pinus contortus, as reflecting floral change in the area. See Figure 2, digitized from figure 10 in Theriot et al. (Reference Theriot, Fritz, Whitlock and Conley2006). The second environmental record we analyzed is solar insolation, which peaked around 11,000 years ago and decreased to the present day. Insolation values in
 $ W/{m}^2 $
were taken from model output from Lasker et al. (2004), using the web interface http://vo.imcce.fr/insola/earth/online/earth/online/index.php for the latitude and longitude of Lake Yellowstone. As S. yellowstonensis blooms in summer (Theriot et al. Reference Theriot, Fritz, Whitlock and Conley2006), we used insolation values for the month of June (Fig. 2).
$ W/{m}^2 $
were taken from model output from Lasker et al. (2004), using the web interface http://vo.imcce.fr/insola/earth/online/earth/online/index.php for the latitude and longitude of Lake Yellowstone. As S. yellowstonensis blooms in summer (Theriot et al. Reference Theriot, Fritz, Whitlock and Conley2006), we used insolation values for the month of June (Fig. 2).

Figure 2. Measured environmental covariates, including June solar insolation (red solid line) and proportion of pollen attributable to Pinus contortus (blue dashed line; note reversed axis).
The sampling times of the environmental records did not precisely match those of the trait time series. We used linear interpolation to produce time series of the environmental records, sampled at the same times as the traits. Both environmental records were mean-centered before analysis to facilitate model fitting.
Our overall model-fitting strategy started with the five models considered by Voje (Reference Voje2020): stasis (ST), random walk (RW), directional trend (DT), Ornstein-Uhlenbeck (OU), and decelerated evolution (DE). To test Theriot et al.’s (Reference Theriot, Fritz, Whitlock and Conley2006) suggestion that environmental changes influenced morphological evolution, we added OU models in which the trait optimum linearly tracks the two environmental covariates described earlier, June solar insolation (
 $ {\mathrm{OU}}_{\mathrm{insol}} $
) and the proportional abundance of Pinus contortus pollen (
$ {\mathrm{OU}}_{\mathrm{insol}} $
) and the proportional abundance of Pinus contortus pollen (
 $ {\mathrm{OU}}_{\mathrm{pollen}} $
). Because model fits and residuals indicated a decrease in stochastic evolutionary change through the core (see “Results”), we considered additional models that allowed for a one-time decrease in the step variance. We specified this time to be 10,000 years ago, following Theriot et al.’s observation (2006: p. 45) that environmental conditions were much more stable after this date.
$ {\mathrm{OU}}_{\mathrm{pollen}} $
). Because model fits and residuals indicated a decrease in stochastic evolutionary change through the core (see “Results”), we considered additional models that allowed for a one-time decrease in the step variance. We specified this time to be 10,000 years ago, following Theriot et al.’s observation (2006: p. 45) that environmental conditions were much more stable after this date.
All these models were fit using functions in the R package paleoTS, the recent update of which (version 0.6.1) allows for fitting models via the Kalman filter and a state space model approach. Approximate profile confidence intervals on parameter estimates were generated using the dentist package (Boyko and O’Meara Reference Boyko and O’Meara2024).Of the five models fit by Voje, we found that DE was best supported by AICc (Table 1, models 1–5), consistent with Voje’s findings. The maximum-likelihood parameter estimate for the decay parameter of the DE model implies a roughly sevenfold decrease in the step variance over the course of the 14 kyr sequence (
 $ \hat{r}=-0.00014 $
; Fig. 3). Examination of residuals indicates that decrease in the stochastic component over time is an important signal in this dataset. Models without this dynamic show residuals with elevated spread early in the sequence (Fig. 4 as an example from the RW model). In contrast, residuals from the DE and best-fitting models are not structured in this way, showing a pattern closer to the ideal even spread (Figs. 5, 6). Also consistent with these data is a model with a single step-down in variance at 10 ka, with separate stochastic variances before (
$ \hat{r}=-0.00014 $
; Fig. 3). Examination of residuals indicates that decrease in the stochastic component over time is an important signal in this dataset. Models without this dynamic show residuals with elevated spread early in the sequence (Fig. 4 as an example from the RW model). In contrast, residuals from the DE and best-fitting models are not structured in this way, showing a pattern closer to the ideal even spread (Figs. 5, 6). Also consistent with these data is a model with a single step-down in variance at 10 ka, with separate stochastic variances before (
 $ {\sigma}_{W_1}^2 $
) and after (
$ {\sigma}_{W_1}^2 $
) and after (
 $ {\sigma}_{W_2}^2 $
) this shift point. This model (Table 1, model 6) fits very slightly better than the DE model. Parameter estimates from this model indicate that the step variance decreases from 2.77 ×
$ {\sigma}_{W_2}^2 $
) this shift point. This model (Table 1, model 6) fits very slightly better than the DE model. Parameter estimates from this model indicate that the step variance decreases from 2.77 ×
 $ {10}^{-5} $
to 1.40 ×
$ {10}^{-5} $
to 1.40 ×
 $ {10}^{-5} $
, about a twofold drop (Fig. 3).
$ {10}^{-5} $
, about a twofold drop (Fig. 3).
Table 1. Model fits to spine counts of the Stephanodiscus yellowstonensis lineage. From left to right, columns give model abbreviations, log-likelihoods, number of parameters, corrected Akaike information criterion (AICc) scores, ∆AICc scores, and Akaike weights. Model abbreviations: RW, random walk; DT, directional trend; OU, Ornstein-Uhlenbeck; DE, decelerating evolution; RWshift, random walk with a shift in the step variance parameter at 10 ka; OUpollen, OU model in which the trait optimum tracks the proportion of the pollen comprised of Pinus contortus; OUinsol, OU model in which the trait optimum tracks solar insolation; OUinsol−shift, OU model in which the trait optimum tracks solar insolation with a shift in the step variance at 10 ka


Figure 3. Modeled changes in the step variance predicted by the two models for which this parameter varies over time. The decelerated evolution (DE) model has a step variance that exponentially decreases, whereas the random walk with a shift in the step variance parameter at 10 ka (RWshift) model posits a single decrease in step variance that occurs at 10 ka.

Figure 4. Residuals from the random walk (RW) model. Note the greater spread of residuals early in the sequence.

Figure 5. Residuals from the decelerated evolution (DE) model. Note they are much less structured over time compared with those from the random walk (RW) model.

Figure 6. Residuals from the best-fitting model (model 9 in Table 1). Note that the spread of residuals does not markedly change over time as it does in the random walk (RW) model.
Comparing the two covariate tracking models, it is more plausible that spine counts tracked June solar insolation rather than the pollen data (Table 1, models 8 and 7, AICc difference of 4.9) (Fig. 7). The
 $ {\mathrm{OU}}_{\mathrm{insol}} $
model shares the features of the OU model, except that the fitness optimum varies with solar insolation instead of being constant over time. The large increase in support between the OU to
$ {\mathrm{OU}}_{\mathrm{insol}} $
model shares the features of the OU model, except that the fitness optimum varies with solar insolation instead of being constant over time. The large increase in support between the OU to
 $ {\mathrm{OU}}_{\mathrm{insol}} $
(Table 1,
$ {\mathrm{OU}}_{\mathrm{insol}} $
(Table 1,
 $ \Delta $
AICc = 6.1) is therefore a measure of the importance of solar insolation in accounting for these observations. Combining this insolation-tracking dynamic with a step decrease in stochastic variance results in a model that is best supported overall (Table 1, model 9; Table 2). This model implies a dynamic where spine counts deterministically follow summer insolation, with overlaid stochastic evolution that is initially high, but then decreases later on.
$ \Delta $
AICc = 6.1) is therefore a measure of the importance of solar insolation in accounting for these observations. Combining this insolation-tracking dynamic with a step decrease in stochastic variance results in a model that is best supported overall (Table 1, model 9; Table 2). This model implies a dynamic where spine counts deterministically follow summer insolation, with overlaid stochastic evolution that is initially high, but then decreases later on.

Figure 7. Log of spine count plotted with respect to June solar insolation in W/m2. Solid line shows the relationship between the two variables predicted by the parameter estimates (Table 2) of the best-fitting model (model 9 in Table 1). Dotted line shows the fit from ordinary least-squares (OLS) regression. The close similarity between the two curves is expected with rapid adaptation, as found here.
Table 2. Maximum-likelihood estimates (MLE) and confidence intervals (CI) for the best-fitting model: an Ornstein-Uhlenbeck (OU) process in which the position of the optimum depends linearly on the value of summer insolation and the step variance is estimated separately before (σ12) and after (σ22) 10,000 years ago. b 0 and b 1 are the intercept and slope of the relationship between solar insolation and the trait optimum, α represents the force of attraction to that optimum, and anc is the estimated trait value at the start of the time series

Discussion
Using the State Space Modeling Framework
We have presented a novel framework based on stochastic integrals and linear state space models for describing and analyzing five models for univariate trait evolution in fossil lineages. We have shown how the stochastic integral approach provides a clearer conceptual basis for relating underlying parameters stated in continuous time to models incorporating discretized sampling and observational error. In particular, we showed how a property of the sampling regime, the duration between observed time points (
 $ \Delta $
), enters into the system equations of the OU model. Looking forward, the framework is naturally generalizable to multivariate systems.
$ \Delta $
), enters into the system equations of the OU model. Looking forward, the framework is naturally generalizable to multivariate systems.
The five base models considered here have all been implemented before for paleontological time series, and they have been fit using maximum likelihood (Hunt Reference Hunt2006; Voje Reference Voje2020). The present approach, using state space models and the Kalman filter, offers an alternative means to compute these same model likelihoods. The two approaches will yield log-likelihoods that are the same (within a constant) and the resulting maximum-likelihood parameter estimates are equivalent, within precision of the hill-climbing algorithm used to search for the best parameter values. Two practical benefits of using the state space approach are that the Kalman filter calculations (1) naturally produce predicted values and residuals useful for assessing model adequacy and (2) do not require inverting a large
 $ T $
by
$ T $
by
 $ T $
matrix, where
$ T $
matrix, where
 $ T $
is the number of samples in the time series. The second benefit applies mostly to rather long time series (
$ T $
is the number of samples in the time series. The second benefit applies mostly to rather long time series (
 $ T>100 $
), as this inversion becomes slow and is prone to fail for very large matrices.
$ T>100 $
), as this inversion becomes slow and is prone to fail for very large matrices.
The analysis of spine counts in Stephanodiscus yellowstonensis is a good example of a typical workflow with the state space approach. An initial set of models were considered, drawn from existing theory and prior interpretations of the system under study. Model fits, as well as examination of residuals, suggest that there are two important signals in the data captured by these models: (1) a decrease over time in the stochastic component of evolutionary change and (2) a correlation between diatom phenotypes and summer solar insolation. The Kalman filter calculations allowed us to quickly implement a model with both of these components, which turned out to be the best supported among those considered. The modular nature of the Kalman filter can thus facilitate model development, as it is allows users to easily combine evolutionary components into new composite models of trait evolution.
We added a single step-down in variance, rather than the exponential decrease of the DE model, to the OU covariate-tracking model. The step decrease in variance is slightly favored over the DE model, but the decision was also a practical one; its incorporation into the OU with covariate tracking is more straightforward. Given the near equivalance in model support between the DE and this discrete shift (Table 1), it is unlikely that these data could discriminate between the two different ways of modeling a reduction in the step variance over time.
Microevolution in Stephanodiscus yellowstonensis
The set of evolutionary models considered here are usually interpreted as phenomenological, not mechanistic. Phenomenological models are useful for representing, using just a few parameters, qualitatively different kinds of dynamics, such as meandering change (RW), fluctuations around a stable mean (ST), or directional trends. In some cases, these models can be shown to be the expected outcome of specific microevolutionary scenarios (e.g., neutral genetic drift will produce a random walk). But these models are usually interpreted descriptively, rather than as the outcome of specific microevolutionary mechanisms.
One potential exception is the OU model. Under a set of simplified but reasonable assumptions, this model describes the expected trajectory of a population evolving in the vicinity of a peak in the adaptive landscape (Lande Reference Lande1976). The peak corresponds to the trait value that results in highest mean population fitness. This peak is stable in the OU model, but changes with extrinsic variables in the covariate-tracking versions implemented here. If the best-fitting of these (
 $ {\mathrm{OU}}_{\mathrm{insol}} $
) is in fact a complete description of the microevolutionary process, its parameters can be related to population genetic parameters related to the strength of natural selection (from the
$ {\mathrm{OU}}_{\mathrm{insol}} $
) is in fact a complete description of the microevolutionary process, its parameters can be related to population genetic parameters related to the strength of natural selection (from the
 $ \alpha $
parameter) and the effective population size (
$ \alpha $
parameter) and the effective population size (
 $ {N}_e $
, from
$ {N}_e $
, from
 $ {\sigma}^2 $
), as described by Hunt et al. (Reference Hunt, Bell and Travis2008).
$ {\sigma}^2 $
), as described by Hunt et al. (Reference Hunt, Bell and Travis2008).
Under this set of assumptions, natural selection is inferred to be rather weak. Mean fitness decreases only 1% or less for individuals 3 SD away from the optimum (Table 3). Caution should be exercised here, because the timescale of adaptation is inferred to be rapid relative to temporal sampling resolution. Its half-life—the amount of time it would take the population to progress halfway to the optimum—is only about 280 years (Table 3), which is close to the median spacing between samples (258 years). As a result, selection could be much stronger than what is estimated, but we would not be able to detect it without finer temporal resolution.
Table 3. Estimates of microevolutionary parameters calculated from the Ornstein-Uhlenbeck (OU) model in which the trait optimum follows summer insolation, with a step-down in step variance at 10 ka (model 9 in Table 1). Shown are calculations assuming low (0.1) and high (0.7) plausible values of trait heritability and 10 generations per year. ω is the computed variance of the population fitness function; larger values indicate broader fitness curves and therefore weaker stabilizing selection. Fitness reduction is the resulting decrease in population mean fitness between the optimal trait value and the trait values corresponding to three population standard deviations away from the optimum. Effective population size (N e) is computed separately before and after 10 ka

The other population genetic parameter that can be calculated is the effective population size,
 $ {N}_e $
. This parameter determines the magnitudes of change due to genetic drift in these models. Drift is more potent in smaller populations, and thus lower
$ {N}_e $
. This parameter determines the magnitudes of change due to genetic drift in these models. Drift is more potent in smaller populations, and thus lower
 $ {N}_e $
values correspond to larger stochastic changes (= higher step variances) around the adaptive trajectory of OU models. The fit of the best model implies about a threefold increase in effective population size at 10 ka. This is consistent with a stepwise increase in the abundance of S. yellowstonensis observed in the core at this time (Theriot et al. Reference Theriot, Fritz, Whitlock and Conley2006).
$ {N}_e $
values correspond to larger stochastic changes (= higher step variances) around the adaptive trajectory of OU models. The fit of the best model implies about a threefold increase in effective population size at 10 ka. This is consistent with a stepwise increase in the abundance of S. yellowstonensis observed in the core at this time (Theriot et al. Reference Theriot, Fritz, Whitlock and Conley2006).
Although the direction of this change is consistent with an increase in the observed absolute abundances of this lineage, the magnitudes of estimated effective population sizes, ranging from
 $ {10}^2 $
to
$ {10}^2 $
to
 $ {10}^4 $
(Table 3), seem rather low for these unicellular algae, which can be found living at abundances high enough to produce that many individuals in just 100 liters of water, or fewer (see Interlandi et al. Reference Interlandi, Kilham and Theriot1999: p. 679). However, it is important to note that effective population size is generally much lower than census population size, with the discrepancy between the two increasing with fluctuations in population size, differences in fitness across individuals, inbreeding, and other factors. The two literature estimates of
$ {10}^4 $
(Table 3), seem rather low for these unicellular algae, which can be found living at abundances high enough to produce that many individuals in just 100 liters of water, or fewer (see Interlandi et al. Reference Interlandi, Kilham and Theriot1999: p. 679). However, it is important to note that effective population size is generally much lower than census population size, with the discrepancy between the two increasing with fluctuations in population size, differences in fitness across individuals, inbreeding, and other factors. The two literature estimates of
 $ {N}_e $
for diatoms are for widespread marine species and are about
$ {N}_e $
for diatoms are for widespread marine species and are about
 $ {10}^7 $
, which although very high, is still orders of magnitude lower than their peak census abundances (Krasovec et al. Reference Krasovec, Sanchez-Brosseau and Piganeau2019). It is likely that our
$ {10}^7 $
, which although very high, is still orders of magnitude lower than their peak census abundances (Krasovec et al. Reference Krasovec, Sanchez-Brosseau and Piganeau2019). It is likely that our
 $ {N}_e $
estimates for S. yellowstonensis are unrealistically low, but the population genetics of lake diatoms is not well enough investigated to be sure of this.
$ {N}_e $
estimates for S. yellowstonensis are unrealistically low, but the population genetics of lake diatoms is not well enough investigated to be sure of this.
Assuming that the
 $ {N}_e $
values computed from the best model are indeed too low, then genetic drift would not be sufficient to account for the stochastic component of spine count evolution. Therefore, other factors, in addition to June insolation, will have caused changes in the position of the adaptive optimum for spine counts, and hints of non-randomness in the residuals of the best-fitting model (Fig. 6) may reflect these unmeasured factors. Theriot et al.’s (Reference Theriot, Fritz, Whitlock and Conley2006) presentation of the paleoenvironmental record provides a detailed account of environmental variation that might contribute to these insolation-independent evolutionary change. In particular, the decrease in the stochastic evolutionary component after 10 ka may be explained by the shift to more stable conditions at this time, leading to more modest selective fluctuations in diatom morphology. Voje (Reference Voje2020) offers an alternative explanation in which ecological opportunity is initially high, perhaps because of the phenotypic changes associated with the origin of the new species S. yellowstonensis. With high ecological opportunity, stabilizing selection may be weakened, permitting greater variation and larger evolutionary steps. This interpretation is consistent with the observation that standing variation in spine counts is initially high and decreases steadily for the first 3 or 4 kyr of the sequence (Fig. 8). These two explanations for the reduction in stochastic evolutionary change—decreasing environmental variation and decreasing ecological opportunity—are not mutually exclusive.
$ {N}_e $
values computed from the best model are indeed too low, then genetic drift would not be sufficient to account for the stochastic component of spine count evolution. Therefore, other factors, in addition to June insolation, will have caused changes in the position of the adaptive optimum for spine counts, and hints of non-randomness in the residuals of the best-fitting model (Fig. 6) may reflect these unmeasured factors. Theriot et al.’s (Reference Theriot, Fritz, Whitlock and Conley2006) presentation of the paleoenvironmental record provides a detailed account of environmental variation that might contribute to these insolation-independent evolutionary change. In particular, the decrease in the stochastic evolutionary component after 10 ka may be explained by the shift to more stable conditions at this time, leading to more modest selective fluctuations in diatom morphology. Voje (Reference Voje2020) offers an alternative explanation in which ecological opportunity is initially high, perhaps because of the phenotypic changes associated with the origin of the new species S. yellowstonensis. With high ecological opportunity, stabilizing selection may be weakened, permitting greater variation and larger evolutionary steps. This interpretation is consistent with the observation that standing variation in spine counts is initially high and decreases steadily for the first 3 or 4 kyr of the sequence (Fig. 8). These two explanations for the reduction in stochastic evolutionary change—decreasing environmental variation and decreasing ecological opportunity—are not mutually exclusive.

Figure 8. Within-sample variance in spine count decreases in the initial part of the Stephanodiscus yellowstonensis sequence.
Analysis of stratigraphic trait changes can be complicated by hiatuses, variation in sedimentation rate, and other aspects of stratigraphic architecture (Patzkowsky and Holland Reference Patzkowsky and Holland2012; Hohmann et al. Reference Hohmann, Koelewijn, Burgess and Jarochowska2024). Thanks to the continuous sedimentation in Lake Yellowstone over the study interval (Theriot et al. Reference Theriot, Fritz, Whitlock and Conley2006), however, such complications are largely avoided in the present case.
Handling Covariates in Models of Trait Evolution
Although a model in which spine counts follow solar insolation as an OU process is the best supported among those considered, we caution that aspects of this model may make it less suitable for some situations. Our implementation requires an assumption that the position of the trait optimum is constant in between the time points at which we have observations. This is reasonable when, as is the case here, the covariates show point-to-point changes that are small compared with the total range of the time series. This assumption will be less appropriate for covariates that fluctuate widely on short timescales. In addition, the microevolutionary intepretation of the OU dynamics is only tenable if the sampling resolution is fine enough to potentially capture the adaptive dynamics of the population chasing the moving fitness peak. Even with the exceptional temporal resolution of the S. yellowstonensis data, the evolutionary dynamics may be too rapid to well constrain estimates for the strength of stabilizing selection. In addition, this modeling approach may be prone to receiving spuriously strong support when applied to traits that show clearly directional change if analyzed with covariates that are also trended. Including the simpler DT model of a trend (without covariates), as is done here, may protect against this effect, as the fewer parameters of the trend model give it an AICc advantage.
State space models are flexible enough to allow for other approaches to incorporate the effects of exogenous covariates that may be more suitable in other circumstances. For example, one could model a trait as an RW, with an additional pulse of change that is proportional to changes in a covariate, implemented through the
 $ \Upsilon $
term of the state equation. Such a modeling approach does not attempt to capture the dynamics of a population climbing an adaptive peak and instead would be consistent with an assumption that enough time has elapsed between samples for the population to have reached the adaptive optimum. This approach would therefore be more appropriate for trait time series at more typical paleontological resolutions. And the use of changes in covariates as input variables, rather than covariates themselves, would render this approach less susceptible to trended sequences as described earlier.
$ \Upsilon $
term of the state equation. Such a modeling approach does not attempt to capture the dynamics of a population climbing an adaptive peak and instead would be consistent with an assumption that enough time has elapsed between samples for the population to have reached the adaptive optimum. This approach would therefore be more appropriate for trait time series at more typical paleontological resolutions. And the use of changes in covariates as input variables, rather than covariates themselves, would render this approach less susceptible to trended sequences as described earlier.
Conclusion
The state space framework provides a practical approach for analyzing phenotypic evolution in fossil lineages that facilitates model development, including those that incorporate exogenous environmental variables. We highlighted some additional useful features, especially the ease of accessing time-series residuals and enhanced numerical stability and efficiency. Our analysis suggested a novel biological interpretation of evolution in spine count for S. yellowstonensis based on stabilizing selection to changing solar insolation levels. Our focus on univariate trait models in this paper provides a foundation for expanding into more complex, multivariate models that, for example, allow for estimation of trait covariances in a time-series setting. Such a multivariate approach will be essential to understand how solar insolation may jointly affect all three traits measured by Theriot et al. (Reference Theriot, Fritz, Whitlock and Conley2006) and to better understand in general the evolution of integrated phenotypes over time.
Acknowledgments
This research was supported by the Templeton Foundation, award number 62220, and the National Museum of Natural History. J.F. also received financial support from the French government in the framework of the France 2030 program IdEx Université de Bordeaux. We are grateful to K. Voje and an anonymous reviewer for their helpful and careful reading of the manuscript and to E. Theriot for providing raw data and insight about this system.
Competing Interests
The authors declare no competing interests.
Data Availability Statement
Data files and analysis scripts have been uploaded to Zenodo (https://zenodo.org) and can be accessed at https://doi.org/10.5281/zenodo.14984759.
Appendix 1. Common Models as Linear State Space Models
Stochastic Integral Models and Their Discretizations
In this section, we will discuss a number of well-known models of trait evolution in fossil lineages and give a corresponding continuous time equivalent. We will then show that each of these models can be exactly discretized to correspond to discretely observed data.
Each of these standard models may be expressed as an Ito integral with a deterministic integrand. We can then look at how each can then be expressed as a linear state space model when observed at discrete time points.
First, the definition of a Ito integral for a deterministic integrand is:
 $$ X(t)={\int}_0^tf\left(t,s\right) dW(s) $$
$$ X(t)={\int}_0^tf\left(t,s\right) dW(s) $$
where
 $ f\left(t,s\right) $
is a deterministic function and
$ f\left(t,s\right) $
is a deterministic function and
 $ W(s) $
is a standard Weiner process (Oksendal Reference Oksendal2013). In other words, for each
$ W(s) $
is a standard Weiner process (Oksendal Reference Oksendal2013). In other words, for each
 $ s $
,
$ s $
,
 $ W(s) $
is a normal random variable with zero mean and variance equal to
$ W(s) $
is a normal random variable with zero mean and variance equal to
 $ s $
. This process also has the property of independent increments, implying that
$ s $
. This process also has the property of independent increments, implying that
 $ W(t)-W(s) $
is independent of
$ W(t)-W(s) $
is independent of
 $ W(v)-W(u) $
as long as
$ W(v)-W(u) $
as long as
 $ \left(s,t\right] $
and
$ \left(s,t\right] $
and
 $ \left(u,v\right] $
do not overlap. The fact that
$ \left(u,v\right] $
do not overlap. The fact that
 $ W(s) $
has zero mean for each
$ W(s) $
has zero mean for each
 $ s $
implies that
$ s $
implies that
 $ X(t) $
does also. Each of the models that we examine in this paper is a Gaussian process, and using this integral representation allows us to express the models in a unified way.
$ X(t) $
does also. Each of the models that we examine in this paper is a Gaussian process, and using this integral representation allows us to express the models in a unified way.
An important property of this integral, especially when calculating variances, is the Ito isometry (Oksendal Reference Oksendal2013).
 $$ E\left[{X}^2(t)\right]=E{\left({\int}_0^tf\left(t,s\right) dW(s)\right)}^2={\int}_0^t{\left(f\left(t,s\right)\right)}^2 ds $$
$$ E\left[{X}^2(t)\right]=E{\left({\int}_0^tf\left(t,s\right) dW(s)\right)}^2={\int}_0^t{\left(f\left(t,s\right)\right)}^2 ds $$
Now, we write some basic models in the form of such an integral along with their exact discretizations and approximate discretizations where appropriate.
Random Walk (RW)
For the RW model, the deterministic function is simply a constant,
 $ \sigma $
, and
$ \sigma $
, and
 $$ X(t)=\sigma W(t) $$
$$ X(t)=\sigma W(t) $$
Note then, that a discretely observed version of this model, assuming equal spacing in time, would be
 $$ X\left(n\Delta \right)=X\left(\left(n-1\right)\Delta \right)+\sigma \left(W\left(n\Delta \right)-W\left(\left(n-1\right)\Delta \right)\right) $$
$$ X\left(n\Delta \right)=X\left(\left(n-1\right)\Delta \right)+\sigma \left(W\left(n\Delta \right)-W\left(\left(n-1\right)\Delta \right)\right) $$
which we could we write as follows by using the fact of independent increments of Brownian motion:
 $$ {X}_n={X}_{n-1}+\sigma \sqrt{\Delta}{\varepsilon}_n $$
$$ {X}_n={X}_{n-1}+\sigma \sqrt{\Delta}{\varepsilon}_n $$
where
 $ {\varepsilon}_n $
is a sequence of independent standard normal random variables, and
$ {\varepsilon}_n $
is a sequence of independent standard normal random variables, and
 $ \Delta $
is the amount of time between observations. This can be derived directly from the earlier integral definition with the
$ \Delta $
is the amount of time between observations. This can be derived directly from the earlier integral definition with the
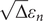 $ \sqrt{\Delta}{\varepsilon}_n $
corresponding to
$ \sqrt{\Delta}{\varepsilon}_n $
corresponding to
 $ W\left(n\Delta \right)-W\left(\left(n-1\right)\Delta \right) $
. In this discrete version,
$ W\left(n\Delta \right)-W\left(\left(n-1\right)\Delta \right) $
. In this discrete version,
 $ {X}_n $
corresponds to
$ {X}_n $
corresponds to
 $ X\left(n\Delta \right) $
.
$ X\left(n\Delta \right) $
.
Directed Random Walk
For this model, we add a deterministic linear directionality to the RW model.
 $$ X(t)=\mu t+\sigma W(t) $$
$$ X(t)=\mu t+\sigma W(t) $$
In a similar way then, a discretely observed version of this model, again assuming equal spacing in time, would be
 $$ {X}_n={X}_{n-1}+\mu \Delta +\sigma \sqrt{\Delta}{\varepsilon}_n $$
$$ {X}_n={X}_{n-1}+\mu \Delta +\sigma \sqrt{\Delta}{\varepsilon}_n $$
with similar interpretations as for the RW.
Decelerated Evolution (DE)
Voje (Reference Voje2020) considered a model for the evolution of a trait where the step variance of a RW declines exponentially. In other words, a model that could be describe with the recursion
 $$ {X}_n={X}_{n-1}+{\sigma}_V{e}^{\frac{-r}{2}n}{\varepsilon}_n $$
$$ {X}_n={X}_{n-1}+{\sigma}_V{e}^{\frac{-r}{2}n}{\varepsilon}_n $$
where
 $ {\sigma}_V $
and
$ {\sigma}_V $
and
 $ r $
are positive parameters and
$ r $
are positive parameters and
 $ {\varepsilon}_n $
is a sequence of standard normal random variables. A natural way to write this as a stochastic integral would be
$ {\varepsilon}_n $
is a sequence of standard normal random variables. A natural way to write this as a stochastic integral would be
 $$ X(t)=X(0)+{\int}_0^t{e}^{\frac{-r}{2}s}\sigma dW(s) $$
$$ X(t)=X(0)+{\int}_0^t{e}^{\frac{-r}{2}s}\sigma dW(s) $$
An Euler approximation of this integral would then be defined by the recursion
 $$ {X}_n={X}_{n-1}+\sigma {e}^{\frac{-r}{2}n\Delta}\sqrt{\Delta}{\varepsilon}_n, $$
$$ {X}_n={X}_{n-1}+\sigma {e}^{\frac{-r}{2}n\Delta}\sqrt{\Delta}{\varepsilon}_n, $$
and if we identify
 $ {\sigma}_V=\sigma \sqrt{\Delta} $
, we notice that this approximation corresponds to Voje’s original definition. However, we can write down an exact discretization of the stochastic integral.
$ {\sigma}_V=\sigma \sqrt{\Delta} $
, we notice that this approximation corresponds to Voje’s original definition. However, we can write down an exact discretization of the stochastic integral.
 $$ {X}_n={X}_{n-1}+{\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{-\frac{r}{2}s}\sigma dW(s) $$
$$ {X}_n={X}_{n-1}+{\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{-\frac{r}{2}s}\sigma dW(s) $$
We can again look at the second term on the right and calculate the variance using Ito’s isometry
 $$ Var\left({\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{-\frac{r}{2}s}\sigma dW(s)\right)={\sigma}^2{\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{- rs} ds $$
$$ Var\left({\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{-\frac{r}{2}s}\sigma dW(s)\right)={\sigma}^2{\int}_{\left(n-1\right)\Delta}^{n\Delta}{e}^{- rs} ds $$
So, solving the integral on the right-hand side of the above equation, we find
 $$ {\sigma}_{\Delta}^2(n)={\sigma}^2\frac{1}{r}{e}^{- rn\Delta}\left({e}^{r\Delta}-1\right) $$
$$ {\sigma}_{\Delta}^2(n)={\sigma}^2\frac{1}{r}{e}^{- rn\Delta}\left({e}^{r\Delta}-1\right) $$
Applying a Taylor expansion with
 $ \Delta $
small, we see that
$ \Delta $
small, we see that
 $$ {\sigma}_{\Delta}^2(n)\approx {\sigma}^2{e}^{- rn\Delta}\Delta $$
$$ {\sigma}_{\Delta}^2(n)\approx {\sigma}^2{e}^{- rn\Delta}\Delta $$
and this corresponds to the Euler approximation.
Stasis (ST)
The ST model assumes that each observation is independent and identically distributed, typically with a normal distribution. So,
 $ {X}_n $
is normal with mean
$ {X}_n $
is normal with mean
 $ c $
and variance
$ c $
and variance
 $ {\sigma}_S^2 $
, which we could write as
$ {\sigma}_S^2 $
, which we could write as
 $$ {X}_n=c+{\sigma}_S{\varepsilon}_n $$
$$ {X}_n=c+{\sigma}_S{\varepsilon}_n $$
where the
 $ {\varepsilon}_n $
is a sequence of independent and identically distributed random variables. Effectively, there is no continuous version of this model. One way to think of this model, however, is as a discretely observed Ornstein-Uhlenbeck (OU) process with sufficient spacing between the observations relative to the parameter
$ {\varepsilon}_n $
is a sequence of independent and identically distributed random variables. Effectively, there is no continuous version of this model. One way to think of this model, however, is as a discretely observed Ornstein-Uhlenbeck (OU) process with sufficient spacing between the observations relative to the parameter
 $ \alpha $
. The OU process is stationary, meaning that after a sufficient time, the initial condition is trivially relevant and the relationship between observations at two times depends only on the distance between those observations. Because the OU process is Gaussian, the variance and covariances define the process. The covariance between two observations of a (zero-mean) OU process is given by
$ \alpha $
. The OU process is stationary, meaning that after a sufficient time, the initial condition is trivially relevant and the relationship between observations at two times depends only on the distance between those observations. Because the OU process is Gaussian, the variance and covariances define the process. The covariance between two observations of a (zero-mean) OU process is given by
 $$ Cov\left(X(t),X(s)\right)=E\left[X(t)X(s)\right]=\frac{\sigma^2}{2\alpha }{e}^{-\alpha \mid t-s\mid } $$
$$ Cov\left(X(t),X(s)\right)=E\left[X(t)X(s)\right]=\frac{\sigma^2}{2\alpha }{e}^{-\alpha \mid t-s\mid } $$
So, if the observations are sufficiently spaced, this covariance is effectively zero (as long as
 $ \alpha $
is not too small). Therefore, the ST model could be viewed as an OU process that is approximately stationary and sufficiently spaced with the relationship between the variances being
$ \alpha $
is not too small). Therefore, the ST model could be viewed as an OU process that is approximately stationary and sufficiently spaced with the relationship between the variances being
 $ {\sigma}_S^2={\sigma}^2/\left(2\alpha \right) $
, where
$ {\sigma}_S^2={\sigma}^2/\left(2\alpha \right) $
, where
 $ {\sigma}^2 $
is the infinitesimal variance of the OU model. If we look at equation (14), with
$ {\sigma}^2 $
is the infinitesimal variance of the OU model. If we look at equation (14), with
 $ \alpha \Delta $
being large, then the we see that the OU model is effectively the ST model.
$ \alpha \Delta $
being large, then the we see that the OU model is effectively the ST model.
Appendix 2. Simulations and Model Selection
To ensure comparability of results, we re-used code from previous studies to simulate data from the five models, including the paleoTS R package maintained by Hunt and supplementary materials from Voje (Reference Voje2020). We used paleoTS to simulate data for the stasis (ST), random walk (RW), directional trend (DT), and Ornstein-Uhlenbeck (OU) models and code from Voje (Reference Voje2020) to simulate data for the decelerated evolution (DE) model. However, we found that prior simulation studies explored parameter values and data-sampling regimes in a way that varied both observational and biological timescales simultaneously (Hunt Reference Hunt2006, 2008; Voje Reference Voje2020), making their separate effects on performance difficult to disentangle. We chose simulation parameters to feature substantial levels of model uncertainty in order to illustrate dependence on sampling scales.
For model selection, we calculated model goodness-of-fit using the corrected Akaike information criterion (AICc), which is modified for better performance in small sample sizes (Hunt Reference Hunt2008). In general, the AICc provides an unbiased estimator of a model’s expected likelihood for small sample sizes, and picking the model with the best (i.e., lowest) AIC score will asymptotically converge on the true distribution when it is unique to a single model (Burnham and Anderson Reference Burnham and Anderson2002). We also calculated Akaike weights for each model using the AICc scores (Wagenmakers and Farrell Reference Wagenmakers and Farrell2004), which approximate the probability that a model is the best out of the candidates considered. For model estimation, we used the linear Kalman filter in the state space models and compared the results of our procedures to those in paleoTS and Voje’s code.
Parameter Estimation
We find that estimation accuracy and uncertainty are not uniformly influenced by sampling timescales. We show simulation results for the RW and DT models (Fig. A2.1), OU model (Fig. A2.2), and DE model (Fig. A2.3). We explored three scenarios for modifying sample timescales: first, increasing sampling with constant total duration (shrinking
 $ \Delta $
); second, increasing duration and increasing sample size (uniform
$ \Delta $
); second, increasing duration and increasing sample size (uniform
 $ \Delta $
); and third, increasing duration while holding sample size constant (increasing
$ \Delta $
); and third, increasing duration while holding sample size constant (increasing
 $ \Delta $
). The ST model is not shown but is effectively an independent, identically distributed (i.i.d.) process with time-indexed observations, and so estimation of
$ \Delta $
). The ST model is not shown but is effectively an independent, identically distributed (i.i.d.) process with time-indexed observations, and so estimation of
 $ {\hat{\sigma}}^2 $
will depend on sample size but not total duration or
$ {\hat{\sigma}}^2 $
will depend on sample size but not total duration or
 $ \Delta $
.
$ \Delta $
.

Figure A2.1. Parameter estimation for random walk (RW) and directional trend (DT) models using varying ratios of stepwise and total observational timescales. The left column shows estimation of the diffusion parameter for the RW model. The middle and right columns show estimation of the diffusion and the drift parameters, respectively, for the DT model. The true parameter values are
 $ {\sigma}^2=25 $
and
$ {\sigma}^2=25 $
and
 $ \mu =5 $
. We use different values for the sample size
$ \mu =5 $
. We use different values for the sample size
 $ N=\left\{\mathrm{20,40,80,160}\right\} $
, the size of the increments
$ N=\left\{\mathrm{20,40,80,160}\right\} $
, the size of the increments
 $ \Delta =\left\{1/8,1/4,1/2,1\right\} $
, and the terminal time
$ \Delta =\left\{1/8,1/4,1/2,1\right\} $
, and the terminal time
 $ T=\left\{\mathrm{2.5,5,10,20}\right\} $
. Box plots show 100 replicates.
$ T=\left\{\mathrm{2.5,5,10,20}\right\} $
. Box plots show 100 replicates.
For the RW and DT models, the results in Figure A2.1 show that increasing total time while keeping the sample size fixed does not affect
 $ {\hat{\sigma}}^2 $
but does improve
$ {\hat{\sigma}}^2 $
but does improve
 $ \hat{\mu} $
. Note that the sufficient statistic for
$ \hat{\mu} $
. Note that the sufficient statistic for
 $ \hat{\mu} $
is the value of the process at the terminal point of the time series, so intermediate values do not matter for estimation, only the endpoint. Increasing duration with constant
$ \hat{\mu} $
is the value of the process at the terminal point of the time series, so intermediate values do not matter for estimation, only the endpoint. Increasing duration with constant
 $ \Delta $
improves both
$ \Delta $
improves both
 $ {\hat{\sigma}}^2 $
and
$ {\hat{\sigma}}^2 $
and
 $ \hat{m}u $
, but for different reasons:
$ \hat{m}u $
, but for different reasons:
 $ \hat{\mu} $
is improving because the total time observed is increasing, but
$ \hat{\mu} $
is improving because the total time observed is increasing, but
 $ {\hat{\sigma}}^2 $
is improving because there are more steps observed.
$ {\hat{\sigma}}^2 $
is improving because there are more steps observed.
In contrast, the OU model parameters in Figure A2.2 show several different types of response to timescales. Both
 $ \hat{\alpha} $
and
$ \hat{\alpha} $
and
 $ {\hat{\sigma}}^2 $
improve for both the scenarios, with increasing sampling with constant duration or increasing duration. As
$ {\hat{\sigma}}^2 $
improve for both the scenarios, with increasing sampling with constant duration or increasing duration. As
 $ \Delta $
becomes larger in row 3, however, estimation gets worse, because
$ \Delta $
becomes larger in row 3, however, estimation gets worse, because
 $ \exp \left(-\Delta \right) $
goes to zero and the process starts to look i.i.d., so that
$ \exp \left(-\Delta \right) $
goes to zero and the process starts to look i.i.d., so that
 $ \hat{\alpha} $
and
$ \hat{\alpha} $
and
 $ {\hat{\sigma}}^2 $
are both being fit to a normal distribution with mean
$ {\hat{\sigma}}^2 $
are both being fit to a normal distribution with mean
 $ \theta $
and variance
$ \theta $
and variance
 $ {\sigma}^2/\left(2\alpha \right) $
. The initial value parameter,
$ {\sigma}^2/\left(2\alpha \right) $
. The initial value parameter,
 $ \hat{Z} $
, is unaffected in all three scenarios, because better estimation of the restoring force,
$ \hat{Z} $
, is unaffected in all three scenarios, because better estimation of the restoring force,
 $ \alpha $
, can only improve precision for the initial condition up to a point. Similar to
$ \alpha $
, can only improve precision for the initial condition up to a point. Similar to
 $ \hat{\mu} $
’s behavior in the RW and DT models, the OU equilibrium value parameter,
$ \hat{\mu} $
’s behavior in the RW and DT models, the OU equilibrium value parameter,
 $ \hat{\theta} $
, does not converge under the increased sampling intensity. Neighboring observations are positively correlated, so adding more time points within a fixed interval gives diminishing returns for estimating the mean, but if
$ \hat{\theta} $
, does not converge under the increased sampling intensity. Neighboring observations are positively correlated, so adding more time points within a fixed interval gives diminishing returns for estimating the mean, but if
 $ T $
is increasing, the observations are spaced farther apart and so are more independent.
$ T $
is increasing, the observations are spaced farther apart and so are more independent.

Figure A2.2. Parameter estimation on simulated data from the Ornstein-Uhlenbeck (OU) model for different combinations of sample size, time step, and total duration. Each of the columns shows parameter estimation for
 $ \alpha, \sigma, {Z}_0 $
, and
$ \alpha, \sigma, {Z}_0 $
, and
 $ \theta $
, respectively. True values are
$ \theta $
, respectively. True values are
 $ \alpha = $
0.50,
$ \alpha = $
0.50,
 $ {\sigma}^2=20 $
,
$ {\sigma}^2=20 $
,
 $ {Z}_0=40 $
, and
$ {Z}_0=40 $
, and
 $ \theta =50 $
, as represented with dashed red lines. We varied the sample size
$ \theta =50 $
, as represented with dashed red lines. We varied the sample size
 $ N=\left\{\mathrm{20,40,80,160}\right\} $
, the size of the increments
$ N=\left\{\mathrm{20,40,80,160}\right\} $
, the size of the increments
 $ \Delta =\left\{1/8,1/4,1/2,1\right\} $
, and the terminal time
$ \Delta =\left\{1/8,1/4,1/2,1\right\} $
, and the terminal time
 $ T=\left\{\mathrm{2.5,5,10,20}\right\} $
. Box plots show 100 replicates.
$ T=\left\{\mathrm{2.5,5,10,20}\right\} $
. Box plots show 100 replicates.
For the DE model, the variance decay parameter
 $ \hat{r} $
in Figure A2.3 shows improved precision in the increasing sampling intensity and increasing duration, constant-sampling scenarios but remains biased below the true value for the simulation setups we examined. The DE model shows phenomenologically the same behavior in
$ \hat{r} $
in Figure A2.3 shows improved precision in the increasing sampling intensity and increasing duration, constant-sampling scenarios but remains biased below the true value for the simulation setups we examined. The DE model shows phenomenologically the same behavior in
 $ {\hat{Z}}_0 $
and
$ {\hat{Z}}_0 $
and
 $ {\hat{\sigma}}^2 $
as the OU model but for different reasons. As the step variance of the process decays exponentially to zero with time, observing the process over a longer duration provides progressively less information.
$ {\hat{\sigma}}^2 $
as the OU model but for different reasons. As the step variance of the process decays exponentially to zero with time, observing the process over a longer duration provides progressively less information.

Figure A2.3. Parameter estimation for decelerated evolution (DE) model on simulated data using varying combinations of sample size, time step, and total duration. The columns show parameter estimation of
 $ r,\sigma $
, and
$ r,\sigma $
, and
 $ {Z}_0 $
, respectively. Dashed red lines show the true values of
$ {Z}_0 $
, respectively. Dashed red lines show the true values of
 $ r= $
−1,
$ r= $
−1,
 $ {\sigma}^2=20 $
, and
$ {\sigma}^2=20 $
, and
 $ {Z}_0=40 $
. We used sample sizes
$ {Z}_0=40 $
. We used sample sizes
 $ N=\left\{\mathrm{20,40,80,160}\right\} $
, time increments of
$ N=\left\{\mathrm{20,40,80,160}\right\} $
, time increments of
 $ \Delta =\left\{1/8,1/4,1/2,1\right\} $
, and terminal times
$ \Delta =\left\{1/8,1/4,1/2,1\right\} $
, and terminal times
 $ T=\left\{\mathrm{2.5,5,10,20}\right\} $
. Box plots show 100 replicates.
$ T=\left\{\mathrm{2.5,5,10,20}\right\} $
. Box plots show 100 replicates.
Model Selection Performance
Figure A2.4 shows how model selection performance, measured in terms of the average Akaike weight of the true model, varies with sampling. Columns in the figure show increasing total duration. Rows show denser sampling as total duration shrinks. Diagonals from top left to bottom right show increasingly dense sampling within a fixed total duration.

Figure A2.4. Model selection performance using the Akaike information criterion (AIC) on simulated data for varying ratios of stepwise and total observational timescales. In each panel, the true model is labeled on the x-axis, and the stacked histogram shows the average Akaike weight for each model. Perfect model performance would show each bar as completely filled by the corresponding true model’s shade on the legend (ST as white, RW as light gray, DT as medium gray, etc.). The true model parameters are ST:
 $ \theta =50 $
,
$ \theta =50 $
,
 $ \omega =20 $
; RW:
$ \omega =20 $
; RW:
 $ {\sigma}_{step}^2=20 $
; DT:
$ {\sigma}_{step}^2=20 $
; DT:
 $ Drift=5 $
,
$ Drift=5 $
,
 $ {\sigma}_{step}^2=25 $
; OU:
$ {\sigma}_{step}^2=25 $
; OU:
 $ \theta =50 $
,
$ \theta =50 $
,
 $ \alpha =20 $
,
$ \alpha =20 $
,
 $ {\sigma}_{step}^2=20 $
; and DE:
$ {\sigma}_{step}^2=20 $
; and DE:
 $ r=-1 $
,
$ r=-1 $
,
 $ {\sigma}_{step}^2=20 $
. The initial condition for all the models is
$ {\sigma}_{step}^2=20 $
. The initial condition for all the models is
 $ {Z}_0=40 $
, the variance of the evolutionary step is
$ {Z}_0=40 $
, the variance of the evolutionary step is
 $ {V}_p=5 $
, and the vector of population sample size is
$ {V}_p=5 $
, and the vector of population sample size is
 $ m=50 $
. We varied sample size
$ m=50 $
. We varied sample size
 $ N=\left\{\mathrm{20,40,80,160}\right\} $
, the size of the increments
$ N=\left\{\mathrm{20,40,80,160}\right\} $
, the size of the increments
 $ \Delta =\left\{1/8,1/4,1/2,1\right\} $
, and the terminal time
$ \Delta =\left\{1/8,1/4,1/2,1\right\} $
, and the terminal time
 $ T=\left\{\mathrm{2.5,5,10,20}\right\} $
. ST, stasis; RW, random walk; DT, directional trend; OU, Ornstein-Uhlenbeck; DE, decelerated evolution.
$ T=\left\{\mathrm{2.5,5,10,20}\right\} $
. ST, stasis; RW, random walk; DT, directional trend; OU, Ornstein-Uhlenbeck; DE, decelerated evolution.
ST is almost exclusively conflated with OU. Increased data appear to slightly worsen false positives for OU when ST is true, likely because the AICc has a bias for nested models toward the model with more parameters. RW is most frequently confused with DT and OU models. The average Akaike weight does not vary significantly with sampling timescales, again likely because of the AICc’s bias toward complex models. As expected, the evidence for DT improves significantly as total duration grows. OU shows improvement with greater duration and sampling density. The same is true for DE, which is mainly competitive with ST for small sample sizes.






















































 Open access
Open access