The Australian SKA Pathfinder (ASKAP) has surveyed the sky at multiple frequencies as part of the Rapid ASKAP Continuum Survey (RACS). The first two RACS observing epochs, at 887.5 (RACS-low) and 1 367.5 (RACS-mid) MHz, have been released (McConnell, et al. 2020, PASA, 37, e048; Duchesne, et al. 2023, PASA, 40, e034). A catalogue of radio sources from RACS-low has also been released, covering the sky south of declination 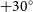 $+30^{\circ}$ (Hale, et al., 2021, PASA, 38, e058). With this paper, we describe and release the first set of catalogues from RACS-mid, covering the sky below declination
$+30^{\circ}$ (Hale, et al., 2021, PASA, 38, e058). With this paper, we describe and release the first set of catalogues from RACS-mid, covering the sky below declination 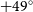 $+49^{\circ}$. The catalogues are created in a similar manner to the RACS-low catalogue, and we discuss this process and highlight additional changes. The general purpose primary catalogue covering 36 200 deg
$+49^{\circ}$. The catalogues are created in a similar manner to the RACS-low catalogue, and we discuss this process and highlight additional changes. The general purpose primary catalogue covering 36 200 deg $^2$ features a variable angular resolution to maximise sensitivity and sky coverage across the catalogued area, with a median angular resolution of
$^2$ features a variable angular resolution to maximise sensitivity and sky coverage across the catalogued area, with a median angular resolution of 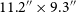 $11.2^{\prime\prime} \times 9.3^{\prime\prime}$. The primary catalogue comprises 3 105 668 radio sources, including those in the Galactic Plane (2 861 923 excluding Galactic latitudes of
$11.2^{\prime\prime} \times 9.3^{\prime\prime}$. The primary catalogue comprises 3 105 668 radio sources, including those in the Galactic Plane (2 861 923 excluding Galactic latitudes of 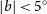 $|b|<5^{\circ}$), and we estimate the catalogue to be 95% complete for sources above 2 mJy. With the primary catalogue, we also provide two auxiliary catalogues. The first is a fixed-resolution, 25-arcsec catalogue approximately matching the sky coverage of the RACS-low catalogue. This 25-arcsec catalogue is constructed identically to the primary catalogue, except images are convolved to a less-sensitive 25-arcsec angular resolution. The second auxiliary catalogue is designed for time-domain science and is the concatenation of source lists from the original RACS-mid images with no additional convolution, mosaicking, or de-duplication of source entries to avoid losing time-variable signals. All three RACS-mid catalogues, and all RACS data products, are available through the CSIRO ASKAP Science Data Archive (https://research.csiro.au/casda/).
$|b|<5^{\circ}$), and we estimate the catalogue to be 95% complete for sources above 2 mJy. With the primary catalogue, we also provide two auxiliary catalogues. The first is a fixed-resolution, 25-arcsec catalogue approximately matching the sky coverage of the RACS-low catalogue. This 25-arcsec catalogue is constructed identically to the primary catalogue, except images are convolved to a less-sensitive 25-arcsec angular resolution. The second auxiliary catalogue is designed for time-domain science and is the concatenation of source lists from the original RACS-mid images with no additional convolution, mosaicking, or de-duplication of source entries to avoid losing time-variable signals. All three RACS-mid catalogues, and all RACS data products, are available through the CSIRO ASKAP Science Data Archive (https://research.csiro.au/casda/).


