Education can be viewed as a control theory problem in which students seek ongoing exogenous input—either through traditional classroom teaching or other alternative training resources—to minimize the discrepancies between their actual and target (reference) performance levels. Using illustrative data from \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n=784$$\end{document}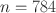 Dutch elementary school students as measured using the Math Garden, a web-based computer adaptive practice and monitoring system, we simulate and evaluate the outcomes of using off-line and finite memory linear quadratic controllers with constraintsto forecast students’ optimal training durations. By integrating population standards with each student’s own latent change information, we demonstrate that adoption of the control theory-guided, person- and time-specific training dosages could yield increased training benefits at reduced costs compared to students’ actual observed training durations, and a fixed-duration training scheme. The control theory approach also outperforms a linear scheme that provides training recommendations based on observed scores under noisy and the presence of missing data. Design-related issues such as ways to determine the penalty cost of input administration and the size of the control horizon window are addressed through a series of illustrative and empirically (Math Garden) motivated simulations.
Dutch elementary school students as measured using the Math Garden, a web-based computer adaptive practice and monitoring system, we simulate and evaluate the outcomes of using off-line and finite memory linear quadratic controllers with constraintsto forecast students’ optimal training durations. By integrating population standards with each student’s own latent change information, we demonstrate that adoption of the control theory-guided, person- and time-specific training dosages could yield increased training benefits at reduced costs compared to students’ actual observed training durations, and a fixed-duration training scheme. The control theory approach also outperforms a linear scheme that provides training recommendations based on observed scores under noisy and the presence of missing data. Design-related issues such as ways to determine the penalty cost of input administration and the size of the control horizon window are addressed through a series of illustrative and empirically (Math Garden) motivated simulations.

