Refine search
Actions for selected content:
23 results
BAYESIAN GENERALISED ADDITIVE MODEL SELECTION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 114 / Issue 1 / August 2026
- Published online by Cambridge University Press:
- 11 June 2026, pp. 210-211
- Print publication:
- August 2026
-
- Article
-
- You have access
- HTML
- Export citation
Mixed-Effects XGBoost with Group-Aware Permutation Importance and Cross-Validation for Multilevel Cross-Classified Continuous Outcomes
-
- Journal:
- Psychometrika ,
- Published online by Cambridge University Press:
- 10 April 2026, pp. 1-40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Explaining Performance Gaps with Problem-Solving Process Data via Latent Class Mediation Analysis
-
- Journal:
- Psychometrika / Volume 90 / Issue 5 / December 2025
- Published online by Cambridge University Press:
- 11 August 2025, pp. 1622-1650
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
VARIABLE SELECTION IN MULTIVARIATE DATA BY ANALYSIS OF DATA PATTERN
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 112 / Issue 3 / December 2025
- Published online by Cambridge University Press:
- 11 August 2025, pp. 572-573
- Print publication:
- December 2025
-
- Article
-
- You have access
- HTML
- Export citation
Estimating the Cognitive Diagnosis \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}
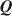 Matrix with Expert Knowledge: Application to the Fraction-Subtraction Dataset
Matrix with Expert Knowledge: Application to the Fraction-Subtraction Dataset
-
- Journal:
- Psychometrika / Volume 84 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 333-357
-
- Article
- Export citation
-
Cognitive diagnosis models (CDMs) are an important psychometric framework for classifying students in terms of attribute and/or skill mastery. The \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}
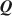 matrix, which specifies the required attributes for each item, is central to implementing CDMs. The general unavailability of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}
matrix, which specifies the required attributes for each item, is central to implementing CDMs. The general unavailability of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}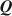 for most content areas and datasets poses a barrier to widespread applications of CDMs, and recent research accordingly developed fully exploratory methods to estimate Q. However, current methods do not always offer clear interpretations of the uncovered skills and existing exploratory methods do not use expert knowledge to estimate Q. We consider Bayesian estimation of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}
for most content areas and datasets poses a barrier to widespread applications of CDMs, and recent research accordingly developed fully exploratory methods to estimate Q. However, current methods do not always offer clear interpretations of the uncovered skills and existing exploratory methods do not use expert knowledge to estimate Q. We consider Bayesian estimation of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}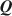 using a prior based upon expert knowledge using a fully Bayesian formulation for a general diagnostic model. The developed method can be used to validate which of the underlying attributes are predicted by experts and to identify residual attributes that remain unexplained by expert knowledge. We report Monte Carlo evidence about the accuracy of selecting active expert-predictors and present an application using Tatsuoka’s fraction-subtraction dataset.
using a prior based upon expert knowledge using a fully Bayesian formulation for a general diagnostic model. The developed method can be used to validate which of the underlying attributes are predicted by experts and to identify residual attributes that remain unexplained by expert knowledge. We report Monte Carlo evidence about the accuracy of selecting active expert-predictors and present an application using Tatsuoka’s fraction-subtraction dataset.
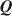
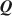
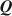
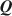
A Variable-Selection Heuristic for K-means Clustering
-
- Journal:
- Psychometrika / Volume 66 / Issue 2 / June 2001
- Published online by Cambridge University Press:
- 01 January 2025, pp. 249-270
-
- Article
- Export citation
Variable Neighborhood Search Heuristics for Selecting a Subset of Variables in Principal Component Analysis
-
- Journal:
- Psychometrika / Volume 74 / Issue 4 / December 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 705-726
-
- Article
- Export citation
Selection of Variables in Cluster Analysis: An Empirical Comparison of Eight Procedures
-
- Journal:
- Psychometrika / Volume 73 / Issue 1 / March 2008
- Published online by Cambridge University Press:
- 01 January 2025, pp. 125-144
-
- Article
- Export citation
A Bayesian Vector Multidimensional Scaling Procedure Incorporating Dimension Reparameterization with Variable Selection
-
- Journal:
- Psychometrika / Volume 80 / Issue 4 / December 2015
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1043-1065
-
- Article
- Export citation
Comparing Bayesian Variable Selection to Lasso Approaches for Applications in Psychology
-
- Journal:
- Psychometrika / Volume 88 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1032-1055
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identification of Inconsistent Variates in Factor Analysis
-
- Journal:
- Psychometrika / Volume 59 / Issue 1 / March 1994
- Published online by Cambridge University Press:
- 01 January 2025, pp. 5-20
-
- Article
- Export citation
5 - Multivariate Feature Selection
- from Part I - Framework for Multivariate Biomarker Discovery
-
- Book:
- Multivariate Biomarker Discovery
- Published online:
- 30 May 2024
- Print publication:
- 06 June 2024, pp 76-98
-
- Chapter
- Export citation
3 - Multiple Linear Regression
-
- Book:
- A Practical Guide to Data Analysis Using R
- Published online:
- 11 May 2024
- Print publication:
- 30 May 2024, pp 144-207
-
- Chapter
- Export citation
3 - Weighting
- from Part I - Polling in Context
-
- Book:
- Polling at a Crossroads
- Published online:
- 29 February 2024
- Print publication:
- 07 March 2024, pp 47-76
-
- Chapter
- Export citation
Chapter 3 - Correlation and Regression Analysis
-
- Book:
- The General Linear Model
- Published online:
- 15 June 2023
- Print publication:
- 29 June 2023, pp 10-123
-
- Chapter
- Export citation
Predicting patients who will drop out of out-patient psychotherapy using machine learning algorithms
-
- Journal:
- The British Journal of Psychiatry / Volume 220 / Issue 4 / April 2022
- Published online by Cambridge University Press:
- 18 February 2022, pp. 192-201
- Print publication:
- April 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Variable selection methods for identifying predictor interactions in data with repeatedly measured binary outcomes
-
- Journal:
- Journal of Clinical and Translational Science / Volume 5 / Issue 1 / 2021
- Published online by Cambridge University Press:
- 16 November 2020, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Evaluating Model Fit and Selecting among Multiple Models
- from Part II - Building a Joint Species Distribution Model Step by Step
-
- Book:
- Joint Species Distribution Modelling
- Published online:
- 18 May 2020
- Print publication:
- 11 June 2020, pp 217-252
-
- Chapter
- Export citation
The Effects of Political Institutions on the Extensive and Intensive Margins of Trade
-
- Journal:
- International Organization / Volume 73 / Issue 4 / Fall 2019
- Published online by Cambridge University Press:
- 25 September 2019, pp. 755-792
- Print publication:
- Fall 2019
-
- Article
- Export citation
LEARNING GRADIENTS FROM NONIDENTICAL DATA
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 58 / Issue 3-4 / April 2017
- Published online by Cambridge University Press:
- 07 March 2017, pp. 220-230
-
- Article
-
- You have access
- Export citation
