Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Hitting Time Theorems for Random Matrices
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 5 / September 2014
- Published online by Cambridge University Press:
- 09 July 2014, pp. 635-669
-
- Article
- Export citation
The Random Connection Model on the Torus
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 5 / September 2014
- Published online by Cambridge University Press:
- 09 July 2014, pp. 796-804
-
- Article
- Export citation
Approximately Counting Embeddings into Random Graphs†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 6 / November 2014
- Published online by Cambridge University Press:
- 09 July 2014, pp. 1028-1056
-
- Article
- Export citation
A New Upper Bound for 1324-Avoiding Permutations
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 5 / September 2014
- Published online by Cambridge University Press:
- 09 July 2014, pp. 717-724
-
- Article
- Export citation
-
We prove that the number of 1324-avoiding permutations of length n is less than
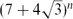 $(7+4\sqrt{3})^n$. The novelty of our method is that we injectively encode such permutations by a pair of words of length n over a finite alphabet that avoid a given factor.
$(7+4\sqrt{3})^n$. The novelty of our method is that we injectively encode such permutations by a pair of words of length n over a finite alphabet that avoid a given factor.

Modal Logic
-
- Published online:
- 05 July 2014
- Print publication:
- 28 June 2001

Analysis of Boolean Functions
-
- Published online:
- 05 July 2014
- Print publication:
- 05 June 2014

Digital Nets and Sequences
- Discrepancy Theory and Quasi–Monte Carlo Integration
-
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010

Understanding Machine Learning
- From Theory to Algorithms
-
- Published online:
- 05 July 2014
- Print publication:
- 19 May 2014

Process Algebra: Equational Theories of Communicating Processes
-
- Published online:
- 05 July 2014
- Print publication:
- 16 December 2009
Existence of an infinite ternary 64-abelian square-freeword
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 3 / July 2014
- Published online by Cambridge University Press:
- 10 July 2014, pp. 307-314
- Print publication:
- July 2014
-
- Article
- Export citation
Integers in number systems with positive and negative quadraticPisot base
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 3 / July 2014
- Published online by Cambridge University Press:
- 13 June 2014, pp. 341-367
- Print publication:
- July 2014
-
- Article
- Export citation
CPC volume 23 issue 4 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 13 June 2014, pp. b1-b8
-
- Article
-
- You have access
- Export citation
On the Spread of Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 13 June 2014, pp. 477-504
-
- Article
- Export citation
-
The spread of a connected graph G was introduced by Alon, Boppana and Spencer [1], and measures how tightly connected the graph is. It is defined as the maximum over all Lipschitz functions f on V(G) of the variance of f(X) when X is uniformly distributed on V(G). We investigate the spread for certain models of sparse random graph, in particular for random regular graphs G(n,d), for Erdős–Rényi random graphs Gn,p in the supercritical range p>1/n, and for a ‘small world’ model. For supercritical Gn,p, we show that if p=c/n with c>1 fixed, then with high probability the spread of the giant component is bounded, and we prove corresponding statements for other models of random graphs, including a model with random edge lengths. We also give lower bounds on the spread for the barely supercritical case when p=(1+o(1))/n. Further, we show that for d large, with high probability the spread of G(n,d) becomes arbitrarily close to that of the complete graph
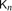 $\mathsf{K}_n$.
$\mathsf{K}_n$.
Intersection Conductance and Canonical Alternating Paths: Methods for General Finite Markov Chains
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 13 June 2014, pp. 585-606
-
- Article
- Export citation
CPC volume 23 issue 4 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 13 June 2014, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Abelian pattern avoidance in partial words∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 3 / July 2014
- Published online by Cambridge University Press:
- 10 June 2014, pp. 315-339
- Print publication:
- July 2014
-
- Article
- Export citation
Singularity Analysis Via the Iterated Kernel Method
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 5 / September 2014
- Published online by Cambridge University Press:
- 10 June 2014, pp. 861-888
-
- Article
- Export citation
Dedication
-
- Book:
- Analysis of Boolean Functions
- Published online:
- 05 July 2014
- Print publication:
- 05 June 2014, pp v-vi
-
- Chapter
- Export citation
Some Tips
-
- Book:
- Analysis of Boolean Functions
- Published online:
- 05 July 2014
- Print publication:
- 05 June 2014, pp 393-394
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Analysis of Boolean Functions
- Published online:
- 05 July 2014
- Print publication:
- 05 June 2014, pp 395-416
-
- Chapter
- Export citation
