Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
1 - Introduction
-
- Book:
- Understanding Machine Learning
- Published online:
- 05 July 2014
- Print publication:
- 19 May 2014, pp 1-10
-
- Chapter
- Export citation
2 - A Gentle Start
- from Part 1 - Foundations
-
- Book:
- Understanding Machine Learning
- Published online:
- 05 July 2014
- Print publication:
- 19 May 2014, pp 13-21
-
- Chapter
- Export citation
Contents
-
- Book:
- Understanding Machine Learning
- Published online:
- 05 July 2014
- Print publication:
- 19 May 2014, pp vii-xiv
-
- Chapter
- Export citation
6 - The VC-Dimension
- from Part 1 - Foundations
-
- Book:
- Understanding Machine Learning
- Published online:
- 05 July 2014
- Print publication:
- 19 May 2014, pp 43-57
-
- Chapter
- Export citation
27 - Covering Numbers
- from Part 4 - Advanced Theory
-
- Book:
- Understanding Machine Learning
- Published online:
- 05 July 2014
- Print publication:
- 19 May 2014, pp 337-340
-
- Chapter
- Export citation
13 - Regularization and Stability
- from Part 2 - From Theory to Algorithms
-
- Book:
- Understanding Machine Learning
- Published online:
- 05 July 2014
- Print publication:
- 19 May 2014, pp 137-149
-
- Chapter
- Export citation
Randomized Rumour Spreading: The Effect of the Network Topology
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 2 / March 2015
- Published online by Cambridge University Press:
- 06 May 2014, pp. 457-479
-
- Article
- Export citation
Cycles Are Strongly Ramsey-Unsaturated
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 29 April 2014, pp. 607-630
-
- Article
- Export citation
An Optimal Algorithm for Finding Frieze–Kannan Regular Partitions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 2 / March 2015
- Published online by Cambridge University Press:
- 23 April 2014, pp. 407-437
-
- Article
- Export citation
Counting Independent Sets in Hypergraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 08 April 2014, pp. 539-550
-
- Article
- Export citation
-
Let G be a triangle-free graph with n vertices and average degree t. We show that G contains at least
independent sets. This improves a recent result of the first and third authors [8]. In particular, it implies that as n → ∞, every triangle-free graph on n vertices has at least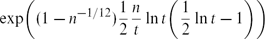 ${\exp\biggl({1-n^{-1/12})\frac{1}{2}\frac{n}{t}\ln t} \biggl(\frac{1}{2}\ln t-1\biggr)\biggr)}$
${\exp\biggl({1-n^{-1/12})\frac{1}{2}\frac{n}{t}\ln t} \biggl(\frac{1}{2}\ln t-1\biggr)\biggr)}$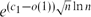 ${e^{(c_1-o(1)) \sqrt{n} \ln n}}$ independent sets, where
${e^{(c_1-o(1)) \sqrt{n} \ln n}}$ independent sets, where 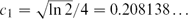 $c_1 = \sqrt{\ln 2}/4 = 0.208138 \ldots$. Further, we show that for all n, there exists a triangle-free graph with n vertices which has at most
$c_1 = \sqrt{\ln 2}/4 = 0.208138 \ldots$. Further, we show that for all n, there exists a triangle-free graph with n vertices which has at most 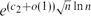 ${e^{(c_2+o(1))\sqrt{n}\ln n}}$ independent sets, where
${e^{(c_2+o(1))\sqrt{n}\ln n}}$ independent sets, where 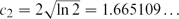 $c_2 = 2\sqrt{\ln 2} = 1.665109 \ldots$. This disproves a conjecture from [8].
$c_2 = 2\sqrt{\ln 2} = 1.665109 \ldots$. This disproves a conjecture from [8].Let H be a (k+1)-uniform linear hypergraph with n vertices and average degree t. We also show that there exists a constant ck such that the number of independent sets in H is at least
This is tight apart from the constant ck and generalizes a result of Duke, Lefmann and Rödl [9], which guarantees the existence of an independent set of size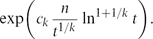 ${\exp\biggl({c_{k} \frac{n}{t^{1/k}}\ln^{1+1/k}{t}\biggr})}.$Both of our lower bounds follow from a more general statement, which applies to hereditary properties of hypergraphs.
${\exp\biggl({c_{k} \frac{n}{t^{1/k}}\ln^{1+1/k}{t}\biggr})}.$Both of our lower bounds follow from a more general statement, which applies to hereditary properties of hypergraphs.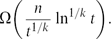 $\Omega\biggl(\frac{n}{t^{1/k}} \ln^{1/k}t\biggr).$
$\Omega\biggl(\frac{n}{t^{1/k}} \ln^{1/k}t\biggr).$
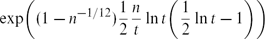
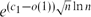
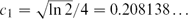
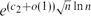
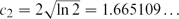
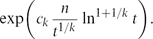
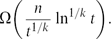
The First k-Regular Subgraph is Large
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 07 April 2014, pp. 412-433
-
- Article
- Export citation
-
Let
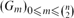 $(G_m)_{0\le m\le \binom{n}{2}}$ be the random graph process starting from the empty graph on vertex set [n] and with a random edge added in each step. Let mk denote the minimum integer such that Gmk contains a k-regular subgraph. We prove that for all sufficiently large k, there exist two constants εk ≥ σk > 0, with εk → 0 as k → ∞, such that asymptotically almost surely any k-regular subgraph of Gmk has size between (1 − εk)|
$(G_m)_{0\le m\le \binom{n}{2}}$ be the random graph process starting from the empty graph on vertex set [n] and with a random edge added in each step. Let mk denote the minimum integer such that Gmk contains a k-regular subgraph. We prove that for all sufficiently large k, there exist two constants εk ≥ σk > 0, with εk → 0 as k → ∞, such that asymptotically almost surely any k-regular subgraph of Gmk has size between (1 − εk)|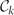 ${\mathcal C}_k$| and (1 − σk)|${\mathcal C}_k$|, where ${\mathcal C}_k$ denotes the k-core of Gmk.
${\mathcal C}_k$| and (1 − σk)|${\mathcal C}_k$|, where ${\mathcal C}_k$ denotes the k-core of Gmk.
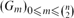
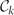
CPC volume 23 issue 3 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 07 April 2014, pp. b1-b2
-
- Article
-
- You have access
- Export citation
CPC volume 23 issue 3 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 07 April 2014, pp. f1-f2
-
- Article
-
- You have access
- Export citation
On the state complexity of semi-quantum finiteautomata⋆⋆⋆
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 17 April 2014, pp. 187-207
- Print publication:
- April 2014
-
- Article
- Export citation
A Generalized Model of PAC Learning and itsApplicability
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 09 April 2014, pp. 209-245
- Print publication:
- April 2014
-
- Article
- Export citation
Colouring Planar Graphs With Three Colours and No Large Monochromatic Components
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 551-570
-
- Article
- Export citation
-
We prove the existence of a function
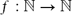 $f :\mathbb{N} \to \mathbb{N}$ such that the vertices of every planar graph with maximum degree Δ can be 3-coloured in such a way that each monochromatic component has at most f(Δ) vertices. This is best possible (the number of colours cannot be reduced and the dependence on the maximum degree cannot be avoided) and answers a question raised by Kleinberg, Motwani, Raghavan and Venkatasubramanian in 1997. Our result extends to graphs of bounded genus.
$f :\mathbb{N} \to \mathbb{N}$ such that the vertices of every planar graph with maximum degree Δ can be 3-coloured in such a way that each monochromatic component has at most f(Δ) vertices. This is best possible (the number of colours cannot be reduced and the dependence on the maximum degree cannot be avoided) and answers a question raised by Kleinberg, Motwani, Raghavan and Venkatasubramanian in 1997. Our result extends to graphs of bounded genus.
New Bounds for Edge-Cover by Random Walk
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 11 March 2014, pp. 571-584
-
- Article
- Export citation
Robust Analysis of Preferential Attachment Models with Fitness
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 24 February 2014, pp. 386-411
-
- Article
- Export citation
CPC volume 23 issue 2 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 2 / March 2014
- Published online by Cambridge University Press:
- 19 February 2014, pp. b1-b7
-
- Article
-
- You have access
- Export citation
CPC volume 23 issue 2 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 2 / March 2014
- Published online by Cambridge University Press:
- 19 February 2014, pp. f1-f2
-
- Article
-
- You have access
- Export citation
