Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Partially Observed Boolean Sequences and Noise Sensitivity
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 13 February 2014, pp. 317-330
-
- Article
- Export citation
-
Let
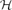 ${\mathcal H}$ denote a collection of subsets of {1,2,. . .,n}, and assign independent random variables uniformly distributed over [0,1] to the n elements. Declare an element p-present if its corresponding value is at most p. In this paper, we quantify how much the observation of the r-present (r>p) set of elements affects the probability that the set of p-present elements is contained in ${\mathcal H}$. In the context of percolation, we find that this question is closely linked to the near-critical regime. As a consequence, we show that for every r>1/2, bond percolation on the subgraph of the square lattice given by the set of r-present edges is almost surely noise sensitive at criticality, thus generalizing a result due to Benjamini, Kalai and Schramm.
${\mathcal H}$ denote a collection of subsets of {1,2,. . .,n}, and assign independent random variables uniformly distributed over [0,1] to the n elements. Declare an element p-present if its corresponding value is at most p. In this paper, we quantify how much the observation of the r-present (r>p) set of elements affects the probability that the set of p-present elements is contained in ${\mathcal H}$. In the context of percolation, we find that this question is closely linked to the near-critical regime. As a consequence, we show that for every r>1/2, bond percolation on the subgraph of the square lattice given by the set of r-present edges is almost surely noise sensitive at criticality, thus generalizing a result due to Benjamini, Kalai and Schramm.
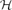
The Asymptotic Number of Connected d-Uniform Hypergraphs†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 13 February 2014, pp. 367-385
-
- Article
- Export citation
-
For d ≥ 2, let Hd(n,p) denote a random d-uniform hypergraph with n vertices in which each of the
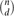 $\binom{n}{d}$ possible edges is present with probability p=p(n) independently, and let Hd(n,m) denote a uniformly distributed d-uniform hypergraph with n vertices and m edges. Let either H=Hd(n,m) or H=Hd(n,p), where m/n and
$\binom{n}{d}$ possible edges is present with probability p=p(n) independently, and let Hd(n,m) denote a uniformly distributed d-uniform hypergraph with n vertices and m edges. Let either H=Hd(n,m) or H=Hd(n,p), where m/n and 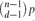 $\binom{n-1}{d-1}p$ need to be bounded away from (d−1)−1 and 0 respectively. We determine the asymptotic probability that H is connected. This yields the asymptotic number of connected d-uniform hypergraphs with given numbers of vertices and edges. We also derive a local limit theorem for the number of edges in Hd(n,p), conditioned on Hd(n,p) being connected.
$\binom{n-1}{d-1}p$ need to be bounded away from (d−1)−1 and 0 respectively. We determine the asymptotic probability that H is connected. This yields the asymptotic number of connected d-uniform hypergraphs with given numbers of vertices and edges. We also derive a local limit theorem for the number of edges in Hd(n,p), conditioned on Hd(n,p) being connected.
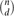
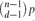
Local Limit Theorems for the Giant Component of Random Hypergraphs†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 13 February 2014, pp. 331-366
-
- Article
- Export citation
-
Let Hd(n,p) signify a random d-uniform hypergraph with n vertices in which each of the
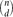 $\binom{n}{d}$ possible edges is present with probability p=p(n) independently, and let Hd(n,m) denote a uniformly distributed d-uniform hypergraph with n vertices and m edges. We derive local limit theorems for the joint distribution of the number of vertices and the number of edges in the largest component of Hd(n,p) and Hd(n,m) in the regime
$\binom{n}{d}$ possible edges is present with probability p=p(n) independently, and let Hd(n,m) denote a uniformly distributed d-uniform hypergraph with n vertices and m edges. We derive local limit theorems for the joint distribution of the number of vertices and the number of edges in the largest component of Hd(n,p) and Hd(n,m) in the regime 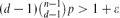 $(d-1)\binom{n-1}{d-1}p>1+\varepsilon$, resp. d(d−1)m/n>1+ϵ, where ϵ>0 is arbitrarily small but fixed as n → ∞. The proofs are based on a purely probabilistic approach.
$(d-1)\binom{n-1}{d-1}p>1+\varepsilon$, resp. d(d−1)m/n>1+ϵ, where ϵ>0 is arbitrarily small but fixed as n → ∞. The proofs are based on a purely probabilistic approach.
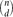
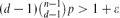
2 - Perfect Graphs and Graphical Modeling
- from Part 1 - Graphical Structure
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 39-68
-
- Chapter
- Export citation
1 - Treewidth and Hypertree Width
- from Part 1 - Graphical Structure
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 3-38
-
- Chapter
- Export citation
Part 3 - Algorithms and their Analysis
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 173-174
-
- Chapter
- Export citation
7 - Tractable Optimization in Machine Learning
- from Part 3 - Algorithms and their Analysis
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 202-230
-
- Chapter
- Export citation
8 - Approximation Algorithms
- from Part 3 - Algorithms and their Analysis
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 231-259
-
- Chapter
- Export citation
3 - Submodular Function Maximization
- from Part 2 - Language Restrictions
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 71-104
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp i-iv
-
- Chapter
- Export citation
11 - Towards Practical Graph-Based, Iteratively Decoded Channel Codes: Insights through Absorbing Sets
- from Part 4 - Tractability in Some Specific Areas
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 304-328
-
- Chapter
- Export citation
12 - SAT Solvers
- from Part 5 - Heuristics
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 331-349
-
- Chapter
- Export citation
4 - Tractable Valued Constraints
- from Part 2 - Language Restrictions
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 105-140
-
- Chapter
- Export citation
Part 4 - Tractability in Some Specific Areas
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 283-284
-
- Chapter
- Export citation
13 - Tractability and Modern Satisfiability Modulo Theories Solvers
- from Part 5 - Heuristics
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 350-377
-
- Chapter
- Export citation
Part 5 - Heuristics
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 329-330
-
- Chapter
- Export citation
Part 1 - Graphical Structure
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 1-2
-
- Chapter
- Export citation
Contributors
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp xi-xii
-
- Chapter
- Export citation
6 - Tree-Reweighted Message Passing
- from Part 3 - Algorithms and their Analysis
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 175-201
-
- Chapter
- Export citation
Contents
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp v-x
-
- Chapter
- Export citation
