Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
1 - Galton–Watson branching processes
-
- Book:
- Epidemics and Rumours in Complex Networks
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009, pp 7-18
-
- Chapter
- Export citation
7 - Power laws via preferential attachment
-
- Book:
- Epidemics and Rumours in Complex Networks
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009, pp 77-86
-
- Chapter
- Export citation
PART I - SHAPELESS NETWORKS
-
- Book:
- Epidemics and Rumours in Complex Networks
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009, pp 5-6
-
- Chapter
- Export citation
6 - The small-world phenomenon
-
- Book:
- Epidemics and Rumours in Complex Networks
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009, pp 65-76
-
- Chapter
- Export citation
3 - Connectivity and Poisson approximation
-
- Book:
- Epidemics and Rumours in Complex Networks
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009, pp 35-45
-
- Chapter
- Export citation
PART II - STRUCTURED NETWORKS
-
- Book:
- Epidemics and Rumours in Complex Networks
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009, pp 63-64
-
- Chapter
- Export citation

Applications of Process Algebra
-
- Published online:
- 03 December 2009
- Print publication:
- 20 September 1990
Frontmatter
-
- Book:
- Epidemics and Rumours in Complex Networks
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009, pp i-iv
-
- Chapter
- Export citation
Introduction
-
- Book:
- Epidemics and Rumours in Complex Networks
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009, pp 1-4
-
- Chapter
- Export citation
CPC volume 19 issue 1 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 02 December 2009, pp. b1-b3
-
- Article
-
- You have access
- Export citation
Expressing Combinatorial Problems by Systems of Polynomial Equations and Hilbert's Nullstellensatz – Corrigendum
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 02 December 2009, p. 159
-
- Article
-
- You have access
- Export citation

Bounded Arithmetic, Propositional Logic and Complexity Theory
-
- Published online:
- 02 December 2009
- Print publication:
- 24 November 1995
CPC volume 19 issue 1 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 02 December 2009, pp. f1-f2
-
- Article
-
- You have access
- Export citation

Basic Simple Type Theory
-
- Published online:
- 02 December 2009
- Print publication:
- 31 July 1997

Algorithmic Information Theory
-
- Published online:
- 23 November 2009
- Print publication:
- 15 October 1987
Relative Tutte Polynomials for Coloured Graphs and Virtual Knot Theory
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 3 / May 2010
- Published online by Cambridge University Press:
- 18 November 2009, pp. 343-369
-
- Article
- Export citation
Vicarious Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 13 November 2009, pp. 819-827
-
- Article
- Export citation
-
Let H be some fixed graph. We call a graph Gvicarious for H if G is maximal H-free and, for every edge e of G, there is an edge f not in G such that G − e + f is also H-free. We demonstrate various properties of vicarious graphs and several examples are given. It is conjectured that a graph of order n which is vicarious for K3 has size at most (1/4 + o(1))(
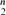
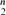
The Number of Independent Sets in a Regular Graph
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 2 / March 2010
- Published online by Cambridge University Press:
- 13 November 2009, pp. 315-320
-
- Article
- Export citation
Graph Partitioning via Adaptive Spectral Techniques
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 2 / March 2010
- Published online by Cambridge University Press:
- 13 November 2009, pp. 227-284
-
- Article
- Export citation

Epistemic Logic for AI and Computer Science
-
- Published online:
- 11 November 2009
- Print publication:
- 24 November 1995
