Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry

Algorithms on Strings
-
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007
I - THE SIMPLEST POSSIBLE MACHINE
- from The three stages of rationality
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 49-216
-
- Chapter
- Export citation
BIBLIOGRAPHY
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 739-748
-
- Chapter
- Export citation
0 - FUNDAMENTAL STRUCTURES
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 7-46
-
- Chapter
- Export citation
III - THE PERTINENCE OF ENUMERATION
- from The three stages of rationality
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 375-520
-
- Chapter
- Export citation
Directed Graphs Without Short Cycles
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 2 / March 2010
- Published online by Cambridge University Press:
- 01 October 2009, pp. 285-301
-
- Article
- Export citation
M. Pascal's division machine
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 1-6
-
- Chapter
- Export citation
II - THE POWER OF ALGEBRA
- from The three stages of rationality
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 217-374
-
- Chapter
- Export citation
Preface
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp xvii-xxiv
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp i-vi
-
- Chapter
- Export citation
A note on the number of squaresin a partial word with one hole
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 4 / October 2009
- Published online by Cambridge University Press:
- 01 October 2009, pp. 767-774
- Print publication:
- October 2009
-
- Article
- Export citation
-
A well known result of Fraenkel and Simpson states that the number of distinct squares in a word of length n is bounded by 2n since at each position there are at most two distinct squares whose last occurrence starts. In this paper, we investigate squares in partial words with one hole,or sequences over a finite alphabet that have a “do not know” symbol or “hole”. A square in a partial word over a given alphabet has the form uv where u is compatible with v, and consequently, such square is compatible with a number of words over the alphabet that are squares. Recently, it was shown that for partial words with one hole, there may be more than two squares that have their last occurrence starting at the same position. Here, we prove that if such is the case, then the length of the shortest square is at most half the length of the third shortest square.As a result, we show that the number of distinct squares compatible with factors of a partial word with one hole of length n is bounded by $\frac{7n}{2}$
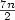 .
.
Contents
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp vii-xiv
-
- Chapter
- Export citation
INDEX
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 749-758
-
- Chapter
- Export citation
IV - THE RICHNESS OF TRANSDUCERS
- from Rationality in relations
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 523-642
-
- Chapter
- Export citation
Preface to the English edition
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp xv-xvi
-
- Chapter
- Export citation
The three stages of rationality
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 47-48
-
- Chapter
- Export citation
Rationality in relations
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 521-522
-
- Chapter
- Export citation
V - THE SIMPLICITY OF FUNCTIONAL TRANSDUCERS
- from Rationality in relations
-
- Book:
- Elements of Automata Theory
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009, pp 643-738
-
- Chapter
- Export citation
Dejean's conjecture holds for N ≥ 27
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 4 / October 2009
- Published online by Cambridge University Press:
- 29 September 2009, pp. 775-778
- Print publication:
- October 2009
-
- Article
- Export citation
A perfect hashing incremental scheme for unranked trees using pseudo-minimal automata
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 4 / October 2009
- Published online by Cambridge University Press:
- 29 September 2009, pp. 779-790
- Print publication:
- October 2009
-
- Article
- Export citation
