Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry

Singularities and Computer Algebra
-
- Published online:
- 11 November 2009
- Print publication:
- 06 April 2006

Theoretical Foundations of VLSI Design
-
- Published online:
- 06 November 2009
- Print publication:
- 13 December 1990

Communication Complexity
-
- Published online:
- 05 November 2009
- Print publication:
- 28 December 1996
Random Sampling of Plane Partitions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 2 / March 2010
- Published online by Cambridge University Press:
- 02 November 2009, pp. 201-226
-
- Article
- Export citation

Formal Specification and Design
-
- Published online:
- 02 November 2009
- Print publication:
- 22 October 1992

The Uncertain Reasoner's Companion
- A Mathematical Perspective
-
- Published online:
- 29 October 2009
- Print publication:
- 12 January 1995

Deductive and Declarative Programming
-
- Published online:
- 24 October 2009
- Print publication:
- 22 October 1992

Free Choice Petri Nets
-
- Published online:
- 21 October 2009
- Print publication:
- 12 January 1995

Concentration of Measure for the Analysis of Randomized Algorithms
-
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009

Metamathematics, Machines and Gödel's Proof
-
- Published online:
- 16 October 2009
- Print publication:
- 12 May 1994

Solving Polynomial Equation Systems I
- The Kronecker-Duval Philosophy
-
- Published online:
- 15 October 2009
- Print publication:
- 27 March 2003

Two-Level Functional Languages
-
- Published online:
- 12 October 2009
- Print publication:
- 16 July 1992
On the Rank of Random Sparse Matrices
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 3 / May 2010
- Published online by Cambridge University Press:
- 12 October 2009, pp. 321-342
-
- Article
- Export citation

The Logic of Typed Feature Structures
- With Applications to Unification Grammars, Logic Programs and Constraint Resolution
-
- Published online:
- 12 October 2009
- Print publication:
- 26 June 1992
CPC volume 18 issue 6 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 6 / November 2009
- Published online by Cambridge University Press:
- 09 October 2009, pp. f1-f2
-
- Article
-
- You have access
- Export citation
CPC volume 18 issue 6 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 6 / November 2009
- Published online by Cambridge University Press:
- 09 October 2009, pp. b1-b5
-
- Article
-
- You have access
- Export citation
A Separator Theorem for String Graphs and its Applications
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 3 / May 2010
- Published online by Cambridge University Press:
- 07 October 2009, pp. 371-390
-
- Article
- Export citation
-
A string graph is the intersection graph of a collection of continuous arcs in the plane. We show that any string graph with m edges can be separated into two parts of roughly equal size by the removal of
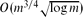 vertices. This result is then used to deduce that every string graph with n vertices and no complete bipartite subgraph Kt,t has at most ctn edges, where ct is a constant depending only on t. Another application shows that locally tree-like string graphs are globally tree-like: for any ε > 0, there is an integer g(ε) such that every string graph with n vertices and girth at least g(ε) has at most (1 + ε)n edges. Furthermore, the number of such labelled graphs is at most (1 + ε)nT(n), where T(n) = nn−2 is the number of labelled trees on n vertices.
vertices. This result is then used to deduce that every string graph with n vertices and no complete bipartite subgraph Kt,t has at most ctn edges, where ct is a constant depending only on t. Another application shows that locally tree-like string graphs are globally tree-like: for any ε > 0, there is an integer g(ε) such that every string graph with n vertices and girth at least g(ε) has at most (1 + ε)n edges. Furthermore, the number of such labelled graphs is at most (1 + ε)nT(n), where T(n) = nn−2 is the number of labelled trees on n vertices.
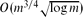 vertices. This result is then used to deduce that every string graph with
vertices. This result is then used to deduce that every string graph with 
Formal Semantics and Pragmatics for Natural Language Querying
-
- Published online:
- 06 October 2009
- Print publication:
- 29 June 1990

Information Dispersal and Parallel Computation
-
- Published online:
- 03 October 2009
- Print publication:
- 29 January 1993

Geometry and Topology for Mesh Generation
-
- Published online:
- 03 October 2009
- Print publication:
- 28 May 2001
