Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
13 - Grammars as software libraries
-
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp 281-308
-
- Chapter
- Export citation
26 - The tower of informatic models
-
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp 561-574
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp i-iv
-
- Chapter
- Export citation
21 - Reversal strategies for adjoint algorithms
-
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp 489-506
-
- Chapter
- Export citation
19 - Proxy caching in split TCP: dynamics, stability and tail asymptotics
-
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp 437-464
-
- Chapter
- Export citation
22 - Reflections on INRIA and the role of Gilles Kahn
-
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp 507-516
-
- Chapter
- Export citation
Preface
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp xiii-xx
-
- Chapter
- Export citation
15 - Theorem-proving support in programming language semantics
-
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp 337-362
-
- Chapter
- Export citation
6 - A simple type-theoretic language: Mini-TT
-
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp 139-164
-
- Chapter
- Export citation
8 - Algorithms for equivalence and reduction to minimal form for a class of simple recursive equations
-
-
- Book:
- From Semantics to Computer Science
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009, pp 169-184
-
- Chapter
- Export citation

Boolean Function Complexity
-
- Published online:
- 23 September 2009
- Print publication:
- 05 November 1992

Belief Revision
-
- Published online:
- 21 September 2009
- Print publication:
- 21 May 1992

Logic and Computation
- Interactive Proof with Cambridge LCF
-
- Published online:
- 17 September 2009
- Print publication:
- 15 October 1987

Purely Functional Data Structures
-
- Published online:
- 17 September 2009
- Print publication:
- 13 April 1998
Palindromes in infinite ternary words
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 4 / October 2009
- Published online by Cambridge University Press:
- 15 September 2009, pp. 687-702
- Print publication:
- October 2009
-
- Article
- Export citation
-
We study infinite words u over an alphabet $\mathcal{A}$
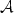 satisfying the property $\mathcal{P} :~\mathcal{P}(n)+\mathcal{P}(n+1) = 1+ \#\mathcal{A}\ {\rm for\ any}\ n \in\mathbb{N}$
satisfying the property $\mathcal{P} :~\mathcal{P}(n)+\mathcal{P}(n+1) = 1+ \#\mathcal{A}\ {\rm for\ any}\ n \in\mathbb{N}$ 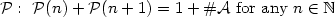 , where $\mathcal{P}(n)$
, where $\mathcal{P}(n)$ 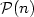 denotes the number ofpalindromic factors of length n occurring in the language of u.We study also infinite words satisfying a strongerproperty $\mathcal{PE}$
denotes the number ofpalindromic factors of length n occurring in the language of u.We study also infinite words satisfying a strongerproperty $\mathcal{PE}$ 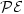 : every palindrome of u has exactly one palindromic extension in u. For binary words, the properties $\mathcal{P}$
: every palindrome of u has exactly one palindromic extension in u. For binary words, the properties $\mathcal{P}$ 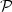 and $\mathcal{PE}$
and $\mathcal{PE}$ 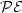 coincide and these properties characterize Sturmian words, i.e.,words with the complexity C(n) = n + 1 for any $n \in \mathbb{N}$
coincide and these properties characterize Sturmian words, i.e.,words with the complexity C(n) = n + 1 for any $n \in \mathbb{N}$ 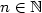 . In this paper, we focus on ternary infinite wordswith the language closed under reversal. For such words u,we prove that if C(n) = 2n + 1 for any $n \in \mathbb{N}$
. In this paper, we focus on ternary infinite wordswith the language closed under reversal. For such words u,we prove that if C(n) = 2n + 1 for any $n \in \mathbb{N}$ 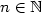 ,then u satisfies the property $\mathcal{P}$ andmoreover u is rich in palindromes. Also a sufficient condition for the property $\mathcal{PE}$ is given.We construct a word demonstrating that $\mathcal{P}$ on a ternaryalphabet does not imply $\mathcal{PE}$ .
,then u satisfies the property $\mathcal{P}$ andmoreover u is rich in palindromes. Also a sufficient condition for the property $\mathcal{PE}$ is given.We construct a word demonstrating that $\mathcal{P}$ on a ternaryalphabet does not imply $\mathcal{PE}$ .
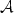
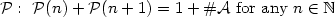
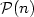
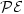
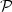
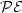
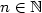
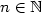
The Regular Excluded Minors for Signed-Graphic Matroids
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 6 / November 2009
- Published online by Cambridge University Press:
- 14 September 2009, pp. 953-978
-
- Article
- Export citation
The t-Improper Chromatic Number of Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 09 September 2009, pp. 87-98
-
- Article
- Export citation

Geometric Spanner Networks
-
- Published online:
- 05 September 2009
- Print publication:
- 08 January 2007
Two extensions of system Fwith (co)iteration and primitive(co)recursion principles
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 4 / October 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 703-766
- Print publication:
- October 2009
-
- Article
- Export citation
Economical Elimination of Cycles in the Torus
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 619-627
-
- Article
- Export citation
-
Let m > 2 be an integer, let C2m denote the cycle of length 2m on the set of vertices [−m, m) = {−m, −m + 1, . . ., m − 2, m − 1}, and let G = G(m, d) denote the graph on the set of vertices [−m, m)d, in which two vertices are adjacent if and only if they are adjacent in C2m in one coordinate, and equal in all others. This graph can be viewed as the graph of the d-dimensional torus. We prove that one can delete a fraction of at most
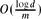 of the vertices of G so that no topologically non-trivial cycles remain. This is tight up to the logd factor and improves earlier estimates by various researchers.
of the vertices of G so that no topologically non-trivial cycles remain. This is tight up to the logd factor and improves earlier estimates by various researchers.
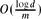 of the vertices of
of the vertices of 