Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
On the Random Satisfiable Process
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 775-801
-
- Article
- Export citation
-
In this work we suggest a new model for generating random satisfiable k-CNF formulas. To generate such formulas. randomly permute all
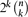 possible clauses over the variables x1,. . .,xn, and starting from the empty formula, go over the clauses one by one, including each new clause as you go along if, after its addition, the formula remains satisfiable. We study the evolution of this process, namely the distribution over formulas obtained after scanning through the first m clauses (in the random permutation's order).
possible clauses over the variables x1,. . .,xn, and starting from the empty formula, go over the clauses one by one, including each new clause as you go along if, after its addition, the formula remains satisfiable. We study the evolution of this process, namely the distribution over formulas obtained after scanning through the first m clauses (in the random permutation's order).Random processes with conditioning on a certain property being respected are widely studied in the context of graph properties. This study was pioneered by Ruciński and Wormald in 1992 for graphs with a fixed degree sequence, and also by Erdős, Suen and Winkler in 1995 for triangle-free and bipartite graphs. Since then many other graph properties have been studied, such as planarity and H-freeness. Thus our model is a natural extension of this approach to the satisfiability setting.
Our main contribution is as follows. For m ≥ cn, c = c(k) a sufficiently large constant, we are able to characterize the structure of the solution space of a typical formula in this distribution. Specifically, we show that typically all satisfying assignments are essentially clustered in one cluster, and all but e−Ω(m/n)n of the variables take the same value in all satisfying assignments. We also describe a polynomial-time algorithm that finds w.h.p. a satisfying assignment for such formulas.
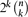 possible clauses over the variables
possible clauses over the variables On 14-Cycle-Free Subgraphs of the Hypercube
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 725-729
-
- Article
- Export citation
On Colourings of Hypergraphs Without Monochromatic Fano Planes
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 803-818
-
- Article
- Export citation
-
For k-uniform hypergraphs F and H and an integer r, let cr,F(H) denote the number of r-colourings of the set of hyperedges of H with no monochromatic copy of F, and let
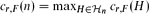 , where the maximum runs over all k-uniform hypergraphs on n vertices. Moreover, let ex(n,F) be the usual extremal or Turán function, i.e., the maximum number of hyperedges of an n-vertex k-uniform hypergraph which contains no copy of F.
, where the maximum runs over all k-uniform hypergraphs on n vertices. Moreover, let ex(n,F) be the usual extremal or Turán function, i.e., the maximum number of hyperedges of an n-vertex k-uniform hypergraph which contains no copy of F.For complete graphs F = Kℓ and r = 2, Erdős and Rothschild conjectured that c2,Kℓ(n) = 2ex(n,Kℓ). This conjecture was proved by Yuster for ℓ = 3 and by Alon, Balogh, Keevash and Sudakov for arbitrary ℓ. In this paper, we consider the question for hypergraphs and show that, in the special case when F is the Fano plane and r = 2 or 3, then cr,F(n) = rex(n,F), while cr,F(n) ≫ rex(n,F) for r ≥ 4.
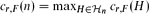 , where the maximum runs over all
, where the maximum runs over all Introduction
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 617-618
-
- Article
- Export citation
CPC volume 18 issue 5 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. b1-b4
-
- Article
-
- You have access
- Export citation
Efficient Graph Packing via Game Colouring
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 765-774
-
- Article
- Export citation
A Note on Universal and Canonically Coloured Sequences
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 683-689
-
- Article
- Export citation
-
A sequence X = {xi}ni=1 over an alphabet containing t symbols is t-universal if every permutation of those symbols is contained as a subsequence. Kleitman and Kwiatkowski showed that the minimum length of a t-universal sequence is (1 − o(1))t2. In this note we address a related Ramsey-type problem. We say that an r-colouring χ of the sequence X is canonical if χ(xi) = χ(xj) whenever xi = xj. We prove that for any fixedt the length of the shortest sequence over an alphabet of size t, which has the property that every r-colouring of its entries contains a t-universal and canonically coloured subsequence, is at most
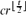 . This is best possible up to a multiplicative constant c independent of r.
. This is best possible up to a multiplicative constant c independent of r.
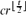 . This is best possible up to a multiplicative constant
. This is best possible up to a multiplicative constant Conflict-Free Colourings of Graphs and Hypergraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 819-834
-
- Article
- Export citation
-
A colouring of the vertices of a hypergraph H is called conflict-free if each hyperedge E of H contains a vertex of ‘unique’ colour that does not get repeated in E. The smallest number of colours required for such a colouring is called the conflict-free chromatic number of H, and is denoted by χCF(H). This parameter was first introduced by Even, Lotker, Ron and Smorodinsky (FOCS 2002) in a geometric setting, in connection with frequency assignment problems for cellular networks. Here we analyse this notion for general hypergraphs. It is shown that
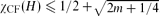 , for every hypergraph with m edges, and that this bound is tight. Better bounds of the order of m1/t log m are proved under the assumption that the size of every edge of H is at least 2t − 1, for some t ≥ 3. Using Lovász's Local Lemma, the same result holds for hypergraphs in which the size of every edge is at least 2t − 1 and every edge intersects at most m others. We give efficient polynomial-time algorithms to obtain such colourings.
, for every hypergraph with m edges, and that this bound is tight. Better bounds of the order of m1/t log m are proved under the assumption that the size of every edge of H is at least 2t − 1, for some t ≥ 3. Using Lovász's Local Lemma, the same result holds for hypergraphs in which the size of every edge is at least 2t − 1 and every edge intersects at most m others. We give efficient polynomial-time algorithms to obtain such colourings.Our machinery can also be applied to the hypergraphs induced by the neighbourhoods of the vertices of a graph. It turns out that in this case we need far fewer colours. For example, it is shown that the vertices of any graph G with maximum degree Δ can be coloured with log2+ε Δ colours, so that the neighbourhood of every vertex contains a point of ‘unique’ colour. We give an efficient deterministic algorithm to find such a colouring, based on a randomized algorithmic version of the Lovász Local Lemma, suggested by Beck, Molloy and Reed. To achieve this, we need to (1) correct a small error in the Molloy–Reed approach, (2) restate and re-prove their result in a deterministic form.
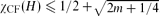 , for every hypergraph with
, for every hypergraph with On Families of Subsets With a Forbidden Subposet
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 731-748
-
- Article
- Export citation
-
Let
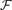
CPC volume 18 issue 5 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. f1-f3
-
- Article
-
- You have access
- Export citation
Concentration on the Discrete Torus Using Transportation
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 835-860
-
- Article
- Export citation
A Combinatorial Distinction Between Unit Circles and Straight Lines: How Many Coincidences Can they Have?
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 691-705
-
- Article
- Export citation
The Degree Sequence of Random Graphs from Subcritical Classes†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 647-681
-
- Article
- Export citation
Erdős–Ko–Rado in Random Hypergraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 629-646
-
- Article
- Export citation
On the Number of 2-SAT Functions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 749-764
-
- Article
- Export citation
-
We give an alternative proof of a conjecture of Bollobás, Brightwell and Leader, first proved by Peter Allen, stating that the number of Boolean functions definable by 2-SAT formulae is
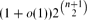 . One step in the proof determines the asymptotics of the number of ‘odd-blue-triangle-free’ graphs on n vertices.
. One step in the proof determines the asymptotics of the number of ‘odd-blue-triangle-free’ graphs on n vertices.
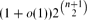 . One step in the proof determines the asymptotics of the number of ‘odd-blue-triangle-free’ graphs on
. One step in the proof determines the asymptotics of the number of ‘odd-blue-triangle-free’ graphs on ULD-Lattices and Δ-Bonds
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 5 / September 2009
- Published online by Cambridge University Press:
- 01 September 2009, pp. 707-724
-
- Article
- Export citation

Planning Algorithms
-
- Published online:
- 21 August 2009
- Print publication:
- 29 May 2006

Curve and Surface Reconstruction
- Algorithms with Mathematical Analysis
-
- Published online:
- 20 August 2009
- Print publication:
- 16 October 2006

Permutation Group Algorithms
-
- Published online:
- 15 August 2009
- Print publication:
- 17 March 2003

Visibility Algorithms in the Plane
-
- Published online:
- 14 August 2009
- Print publication:
- 29 March 2007
