Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
12 - Isoperimetric Inequalities and Concentration via Transportation Cost Inequalities
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 151-160
-
- Chapter
- Export citation
14 - Log-Sobolev Inequalities and Concentration
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 171-184
-
- Chapter
- Export citation
Appendix A - Summary of the Most Useful Bounds
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 185-188
-
- Chapter
- Export citation
9 - Interlude: The Infamous Upper Tail
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 121-125
-
- Chapter
- Export citation
CPC volume 18 issue 3 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. f1-f2
-
- Article
-
- You have access
- Export citation
On the Difference of Expected Lengths of Minimum Spanning Trees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 423-434
-
- Article
- Export citation
Simplex Stability
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 441-454
-
- Article
- Export citation
-
A d-simplex is a collection of d + 1 sets such that every d of them has non-empty intersection and the intersection of all of them is empty. Fix k ≥ d + 2 ≥ 3 and let
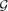
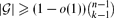 , then there is a vertex x of
, then there is a vertex x of Our main result is actually stronger, and implies that if
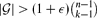 for any ϵ < 0 and n sufficiently large, then
for any ϵ < 0 and n sufficiently large, then
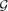
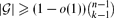 , then there is a vertex
, then there is a vertex 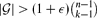 for any ϵ < 0 and
for any ϵ < 0 and On the Likely Number of Solutions for the Stable Marriage Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 371-421
-
- Article
- Export citation
Growing at a Perfect Speed
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 301-308
-
- Article
- Export citation
Freiman's Theorem in Finite Fields via Extremal Set Theory
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 335-355
-
- Article
- Export citation
-
Using various results from extremal set theory (interpreted in the language of additive combinatorics), we prove an asymptotically sharp version of Freiman's theorem in
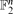 : if
: if  is a set for which |A + A| ≤ K|A| then A is contained in a subspace of size
is a set for which |A + A| ≤ K|A| then A is contained in a subspace of size 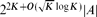 ; except for the
; except for the 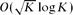 error, this is best possible. If in addition we assume that A is a downset, then we can also cover A by O(K46) translates of a coordinate subspace of size at most |A|, thereby verifying the so-called polynomial Freiman–Ruzsa conjecture in this case. A common theme in the arguments is the use of compression techniques. These have long been familiar in extremal set theory, but have been used only rarely in the additive combinatorics literature.
error, this is best possible. If in addition we assume that A is a downset, then we can also cover A by O(K46) translates of a coordinate subspace of size at most |A|, thereby verifying the so-called polynomial Freiman–Ruzsa conjecture in this case. A common theme in the arguments is the use of compression techniques. These have long been familiar in extremal set theory, but have been used only rarely in the additive combinatorics literature.
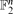 : if
: if  is a set for which |
is a set for which |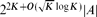 ; except for the
; except for the 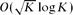 error, this is best possible. If in addition we assume that
error, this is best possible. If in addition we assume that Algebraic Properties of Modulo q Complete ℓ-Wide Families
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 309-333
-
- Article
- Export citation
-
Let q be a power of a prime p, and let n, d, ℓ be integers such that 1 ≤ n, 1 ≤ ℓ < q. Consider the modulo q complete ℓ-wide family:
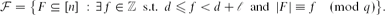
We describe a Gröbner basis of the vanishing ideal I(
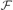
We compute the Hilbert function of I(
We apply our results to problems from extremal set theory. We prove a sharp upper bound of the cardinality of a modulo q ℓ-wide family, which shatters only small sets. This is closely related to a conjecture of Frankl [13] on certain ℓ-antichains. The formula of the Hilbert function also allows us to obtain an upper bound on the size of a set system with certain restricted intersections, generalizing a bound proposed by Babai and Frankl [6].
The paper generalizes and extends the results of [15], [16] and [17].
CPC volume 18 issue 3 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. b1-b4
-
- Article
-
- You have access
- Export citation
Decision Trees and Influences of Variables Over Product Probability Spaces
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 357-369
-
- Article
- Export citation
-
A celebrated theorem of Friedgut says that every function f : {0, 1}n → {0, 1} can be approximated by a function g : {0, 1}n → {0, 1} with
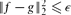 , which depends only on eO(If / ε) variables, where If is the sum of the influences of the variables of f. Dinur and Friedgut later showed that this statement also holds if we replace the discrete domain {0, 1}n with the continuous domain [0, 1]n, under the extra assumption that f is increasing. They conjectured that the condition of monotonicity is unnecessary and can be removed.
, which depends only on eO(If / ε) variables, where If is the sum of the influences of the variables of f. Dinur and Friedgut later showed that this statement also holds if we replace the discrete domain {0, 1}n with the continuous domain [0, 1]n, under the extra assumption that f is increasing. They conjectured that the condition of monotonicity is unnecessary and can be removed.We show that certain constant-depth decision trees provide counter-examples to the Dinur–Friedgut conjecture. This suggests a reformulation of the conjecture in which the function g : [0, 1]n → {0, 1}, instead of depending on a small number of variables, has a decision tree of small depth. In fact we prove this reformulation by showing that the depth of the decision tree of g can be bounded by eO(If / ε2).
Furthermore, we consider a second notion of the influence of a variable, and study the functions that have bounded total influence in this sense. We use a theorem of Bourgain to show that these functions have certain properties. We also study the relation between the two different notions of influence.
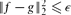 , which depends only on
, which depends only on A Spectral Erdős–Stone–Bollobás Theorem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 455-458
-
- Article
- Export citation
-
Let r ≥ 3 and (c/rr)r log n ≥ 1. If G is a graph of order n and its largest eigenvalue μ(G) satisfies
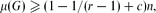 then G contains a complete r-partite subgraph with r − 1 parts of size ⌊(c/rr)r log n⌋ and one part of size greater than n1−cr−1.
then G contains a complete r-partite subgraph with r − 1 parts of size ⌊(c/rr)r log n⌋ and one part of size greater than n1−cr−1.This result implies the Erdős–Stone–Bollobás theorem, the essential quantitative form of the Erdős–Stone theorem. Another easy consequence is that if F1, F2, . . . are r-chromatic graphs satisfying v(Fn) = o(log n), then
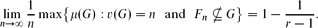
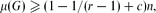
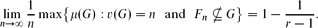
Triangles in Regular Graphs with Density Below One Half
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 435-440
-
- Article
- Export citation
-
Let k3reg(n, d) be the minimum number of triangles in d-regular graphs with n vertices. We find the exact value of k3reg(n, d) for d between
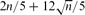 and n/2. In addition, we identify the structure of the extremal graphs.
and n/2. In addition, we identify the structure of the extremal graphs.
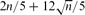 and
and Left-to-right regular languages and two-way restarting automata
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 3 / July 2009
- Published online by Cambridge University Press:
- 24 April 2009, pp. 653-665
- Print publication:
- July 2009
-
- Article
- Export citation
Appendix: Mathematical background
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 20 April 2009, pp 508-530
-
- Chapter
- Export citation
6 - Boolean circuits
- from PART ONE - BASIC COMPLEXITY CLASSES
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 20 April 2009, pp 106-122
-
- Chapter
- Export citation
7 - Randomized computation
- from PART ONE - BASIC COMPLEXITY CLASSES
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 20 April 2009, pp 123-142
-
- Chapter
- Export citation
0 - Notational conventions
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 20 April 2009, pp 1-6
-
- Chapter
- Export citation
