Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry

Rippling: Meta-Level Guidance for Mathematical Reasoning
-
- Published online:
- 13 August 2009
- Print publication:
- 30 June 2005

Data Structures and Algorithms Using Visual Basic.NET
-
- Published online:
- 11 August 2009
- Print publication:
- 07 March 2005
Identifying and Locating–Dominating Codes in (Random) Geometric Networks
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 6 / November 2009
- Published online by Cambridge University Press:
- 11 August 2009, pp. 925-952
-
- Article
- Export citation
-
We model a problem about networks built from wireless devices using identifying and locating–dominating codes in unit disk graphs. It is known that minimizing the size of an identifying code is
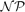
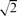
Weighted Interlace Polynomials
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 10 August 2009, pp. 133-157
-
- Article
- Export citation
-
The interlace polynomials introduced by Arratia, Bollobás and Sorkin extend to invariants of graphs with vertex weights, and these weighted interlace polynomials have several novel properties. One novel property is a version of the fundamental three-term formula
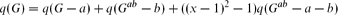 that lacks the last term. It follows that interlace polynomial computations can be represented by binary trees rather than mixed binary–ternary trees. Binary computation trees provide a description of q(G) that is analogous to the activities description of the Tutte polynomial. If G is a tree or forest then these ‘algorithmic activities’ are associated with a certain kind of independent set in G. Three other novel properties are weighted pendant-twin reductions, which involve removing certain kinds of vertices from a graph and adjusting the weights of the remaining vertices in such a way that the interlace polynomials are unchanged. These reductions allow for smaller computation trees as they eliminate some branches. If a graph can be completely analysed using pendant-twin reductions, then its interlace polynomial can be calculated in polynomial time. An intuitively pleasing property is that graphs which can be constructed through graph substitutions have vertex-weighted interlace polynomials which can be obtained through algebraic substitutions.
that lacks the last term. It follows that interlace polynomial computations can be represented by binary trees rather than mixed binary–ternary trees. Binary computation trees provide a description of q(G) that is analogous to the activities description of the Tutte polynomial. If G is a tree or forest then these ‘algorithmic activities’ are associated with a certain kind of independent set in G. Three other novel properties are weighted pendant-twin reductions, which involve removing certain kinds of vertices from a graph and adjusting the weights of the remaining vertices in such a way that the interlace polynomials are unchanged. These reductions allow for smaller computation trees as they eliminate some branches. If a graph can be completely analysed using pendant-twin reductions, then its interlace polynomial can be calculated in polynomial time. An intuitively pleasing property is that graphs which can be constructed through graph substitutions have vertex-weighted interlace polynomials which can be obtained through algebraic substitutions.
Duality of Ends
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 10 August 2009, pp. 47-60
-
- Article
- Export citation
Step Size in Stein's Method of Exchangeable Pairs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 6 / November 2009
- Published online by Cambridge University Press:
- 10 August 2009, pp. 979-1017
-
- Article
- Export citation
On the proper intervalization of colored caterpillar trees
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 4 / October 2009
- Published online by Cambridge University Press:
- 30 July 2009, pp. 667-686
- Print publication:
- October 2009
-
- Article
- Export citation
On Sums of Dilates
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 6 / November 2009
- Published online by Cambridge University Press:
- 09 July 2009, pp. 871-880
-
- Article
- Export citation
Finding an Unknown Acyclic Orientation of a Given Graph
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 09 July 2009, pp. 121-131
-
- Article
- Export citation
Application of a Generalization of Russo's Formula to Learning from Multiple Random Oracles
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 2 / March 2010
- Published online by Cambridge University Press:
- 09 July 2009, pp. 183-199
-
- Article
- Export citation
Sizes of Induced Subgraphs of Ramsey Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. 459-476
-
- Article
- Export citation
The Equivalence of Two Graph Polynomials and a Symmetric Function
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. 601-615
-
- Article
- Export citation
Subgraphs of Random k-Edge-Coloured k-Regular Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. 533-549
-
- Article
- Export citation
Random Graphs from a Minor-Closed Class
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. 583-599
-
- Article
- Export citation
-
A minor-closed class of graphs is addable if each excluded minor is 2-connected. We see that such a class
CPC volume 18 issue 4 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. b1-b5
-
- Article
-
- You have access
- Export citation
On a Speculated Relation Between Chvátal–Sankoff Constants of Several Sequences
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. 517-532
-
- Article
- Export citation
Expressing Combinatorial Problems by Systems of Polynomial Equations and Hilbert's Nullstellensatz
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. 551-582
-
- Article
- Export citation
Asymptotic Enumeration of Constellations and Related Families of Maps on Orientable Surfaces
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. 477-516
-
- Article
- Export citation
CPC volume 18 issue 4 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 4 / July 2009
- Published online by Cambridge University Press:
- 01 July 2009, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Deterministic Edge Weights in Increasing Tree Families
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 22 June 2009, pp. 99-119
-
- Article
- Export citation
