Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
The Longest Minimum-Weight Path in a Complete Graph
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 22 June 2009, pp. 1-19
-
- Article
- Export citation
Hypergraph Packing and Sparse Bipartite Ramsey Numbers
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 6 / November 2009
- Published online by Cambridge University Press:
- 22 June 2009, pp. 913-923
-
- Article
- Export citation
Randomized Greedy Algorithms for Independent Sets and Matchings in Regular Graphs: Exact Results and Finite Girth Corrections
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 22 June 2009, pp. 61-85
-
- Article
- Export citation
-
We derive new results for the performance of a simple greedy algorithm for finding large independent sets and matchings in constant-degree regular graphs. We show that for r-regular graphs with n nodes and girth at least g, the algorithm finds an independent set of expected cardinality
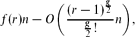 where f(r) is a function which we explicitly compute. A similar result is established for matchings. Our results imply improved bounds for the size of the largest independent set in these graphs, and provide the first results of this type for matchings. As an implication we show that the greedy algorithm returns a nearly perfect matching when both the degree r and girth g are large. Furthermore, we show that the cardinality of independent sets and matchings produced by the greedy algorithm in arbitrary bounded-degree graphs is concentrated around the mean. Finally, we analyse the performance of the greedy algorithm for the case of random i.i.d. weighted independent sets and matchings, and obtain a remarkably simple expression for the limiting expected values produced by the algorithm. In fact, all the other results are obtained as straightforward corollaries from the results for the weighted case.
where f(r) is a function which we explicitly compute. A similar result is established for matchings. Our results imply improved bounds for the size of the largest independent set in these graphs, and provide the first results of this type for matchings. As an implication we show that the greedy algorithm returns a nearly perfect matching when both the degree r and girth g are large. Furthermore, we show that the cardinality of independent sets and matchings produced by the greedy algorithm in arbitrary bounded-degree graphs is concentrated around the mean. Finally, we analyse the performance of the greedy algorithm for the case of random i.i.d. weighted independent sets and matchings, and obtain a remarkably simple expression for the limiting expected values produced by the algorithm. In fact, all the other results are obtained as straightforward corollaries from the results for the weighted case.
The Linus Sequence
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 1 / January 2010
- Published online by Cambridge University Press:
- 22 June 2009, pp. 21-46
-
- Article
- Export citation
3 - Chernoff–Hoeffding Bounds in Dependent Settings
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 34-50
-
- Chapter
- Export citation
6 - The Simple Method of Bounded Differences in Action
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 74-84
-
- Chapter
- Export citation
1 - Chernoff–Hoeffding Bounds
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 1-15
-
- Chapter
- Export citation
13 - Quadratic Transportation Cost and Talagrand's Inequality
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 161-170
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp i-vi
-
- Chapter
- Export citation
Index
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 195-196
-
- Chapter
- Export citation
10 - Isoperimetric Inequalities and Concentration
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 126-135
-
- Chapter
- Export citation
8 - The Method of Bounded Variances
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 106-120
-
- Chapter
- Export citation
5 - Martingales and the Method of Bounded Differences
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 58-73
-
- Chapter
- Export citation
11 - Talagrand's Isoperimetric Inequality
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 136-150
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 189-194
-
- Chapter
- Export citation
Contents
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp vii-x
-
- Chapter
- Export citation
4 - Interlude: Probabilistic Recurrences
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 51-57
-
- Chapter
- Export citation
Preface
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp xi-xvi
-
- Chapter
- Export citation
7 - The Method of Averaged Bounded Differences
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 85-105
-
- Chapter
- Export citation
2 - Applications of the Chernoff–Hoeffding Bounds
-
- Book:
- Concentration of Measure for the Analysis of Randomized Algorithms
- Published online:
- 19 October 2009
- Print publication:
- 15 June 2009, pp 16-33
-
- Chapter
- Export citation
