Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Part I - Fundamentals and Probability on Events
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 1-42
-
- Chapter
- Export citation
7 - Continuous Random Variables: Single Distribution
- from Part III - Continuous Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 134-152
-
- Chapter
- Export citation
Part V - Statistical Inference
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 253-304
-
- Chapter
- Export citation
25 - Ergodicity for Finite-State Discrete-Time Markov Chains
- from Part VIII - Discrete-Time Markov Chains
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 438-478
-
- Chapter
- Export citation
-
Summary
At this point in our discussion of discrete-time Markov chains (DTMCs) with
states, we have defined the notion of a limiting probability of being in state
19 - Applications of Tail Bounds: Confidence Intervals and Balls and Bins
- from Part VI - Tail Bounds and Applications
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 327-345
-
- Chapter
- Export citation
1 - Before We Start … Some Mathematical Basics
- from Part I - Fundamentals and Probability on Events
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 2-20
-
- Chapter
- Export citation
16 - Classical Statistical Inference
- from Part V - Statistical Inference
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 265-284
-
- Chapter
- Export citation
5 - Variance, Higher Moments, and Random Sums
- from Part II - Discrete Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 83-115
-
- Chapter
- Export citation
The Excluded Tree Minor Theorem Revisited
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 27 September 2023, pp. 85-90
-
- Article
- Export citation
-
We prove that for every tree
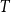 $T$ of radius
$T$ of radius 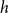 $h$, there is an integer
$h$, there is an integer  $c$ such that every
$c$ such that every 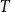 $T$-minor-free graph is contained in
$T$-minor-free graph is contained in 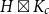 $H\boxtimes K_c$ for some graph
$H\boxtimes K_c$ for some graph 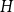 $H$ with pathwidth at most
$H$ with pathwidth at most 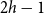 $2h-1$. This is a qualitative strengthening of the Excluded Tree Minor Theorem of Robertson and Seymour (GM I). We show that radius is the right parameter to consider in this setting, and
$2h-1$. This is a qualitative strengthening of the Excluded Tree Minor Theorem of Robertson and Seymour (GM I). We show that radius is the right parameter to consider in this setting, and 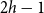 $2h-1$ is the best possible bound.
$2h-1$ is the best possible bound.
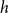

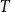
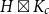
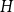
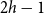
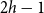
Part II - Eigensystem
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 305-306
-
- Chapter
- Export citation
Part I - Spectra of graphs
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 13-14
-
- Chapter
- Export citation
7 - Density function of the eigenvalues
- from Part I - Spectra of graphs
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 247-270
-
- Chapter
- Export citation
Symbols
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp xvii-xx
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 1-12
-
- Chapter
- Export citation
9 - Topics in linear algebra
- from Part II - Eigensystem
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 307-344
-
- Chapter
- Export citation
Dedication
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp v-vi
-
- Chapter
- Export citation
8 - Spectra of complex networks
- from Part I - Spectra of graphs
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 271-304
-
- Chapter
- Export citation
Index
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 513-515
-
- Chapter
- Export citation
11 - Polynomials with real coefficients
- from Part III - Polynomials
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 401-466
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp i-iv
-
- Chapter
- Export citation
